Patroni has dramatically simplified the setup of the PostgreSQL High-Availability cluster. Personally I consider Patroni to be by far the best tool out there to cluster PostgreSQL and to ensure HA in the most reliable and straightforward way possible.
The main questions asked by many people are: How can you make a PostgreSQL cluster transparent? How does the application figure out where the primary database is? The solution to the problem is a tool we implemented some time ago: Let me introduce you to vip-manager (Virtual IP Manager), a simple to use tool to handle service IPs in a PostgreSQL Patroni cluster.
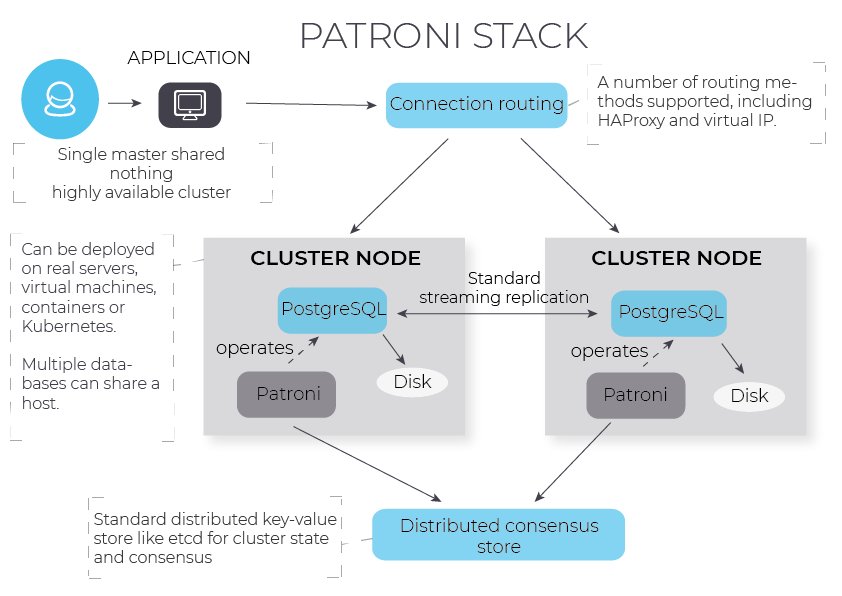
Before we dig a bit deeper into vip-manager, I want to explain the basic architecture of Patroni itself briefly. As you might know, Patroni is a tool developed initially by Zalando, which was a milestone in the development of PostgreSQL High-Availability. Over the years, we (CYBERTEC) have contributed countless patches to Patroni. We hope that we have made a difference in this crucial area relevant to so many people relying on PostgreSQL HA.
Patroni uses a key-value store (usually, etcd, zookeeper or consul) to handle consensus. The idea is to keep a leader key in the key-value store, which knows where the current master is. In other words: the cluster knows who happens to be primary and who happens to be secondary. Why not use this information to move a service IP around inside the cluster and assign it to the active primary? This is precisely what vip-manager does. It runs on every database node and checks if the node it runs on happens to be the "chosen one". In case vip-manager sees that it runs on the current primary it grabs the IP and creates an IP alias. In case the vip-manager sees that the node it is running on is not the master, it ensures that the IP is removed.
In a cluster consisting of 3 database servers, you will therefore need 4 IPs. 1 IP per server will be static - one IP will be moved around and follow the primary. Of course, the floating IP is what you should use in your applications.
A typical node in a Patroni cluster has to run two services: Patroni and vip-manager. Patroni controls PostgreSQL (stop, start, sync, etc.). vip-manager is a simple Go application doing nothing else but control the floating IP pointing to the master.
Configuring vip-manager is simple. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# config for vip-manager by Cybertec PostgreSQL International GmbH # time (in milliseconds) after which vip-manager wakes up and checks # if it needs to register or release ip addresses. interval: 1000 # the etcd or consul key which vip-manager will regularly poll. key: '/service/pgcluster/leader' # if the value of the above key matches the NodeName (often the hostname of this host), # vip-manager will try to add the virtual ip address to the interface specified in Iface nodename: 'pgcluster_member1' ip: 192.168.0.123 # the virtual ip address to manage mask: 24 # netmask for the virtual ip iface: enp0s3 #interface to which the virtual ip will be added # how the virtual ip should be managed. we currently support 'ip addr add/remove' # through shell commands or the Hetzner api hosting_type: basic # possible values: basic, or hetzner. endpoint_type: etcd # etcd or consul # a list that contains all endpoints to which etcd could talk. endpoints: - http://127.0.0.1:2379 - http://192.168.0.42:2379 # A single list-item is also fine. # consul will always only use the first entry from this list. # For consul, you'll obviously need to change the port to 8500. Unless you're # using a different one. Maybe you're a rebel and are running consul on port 2379? # Just to confuse people? Why would you do that? Oh, I get it. etcd_user: 'patroni' etcd_password: 'Julian's secret password' # don't worry about parameter with a prefix that doesn't match the endpoint_type. # You can write anything there, I won't even look at it. consul_token: 'Julian's secret token' # how often things should be retried and how long to wait between retries. # (currently only affects arpClient) retry_num: 2 retry_after: 250 #in milliseconds |
Basically, the configuration is simple: First of all, vip-manager has to know where etcd is. Then it has to know where it can find the leader key (URL). Finally, we want to know which IP has to be bound to which network interface. The rest is the simple login information for etcd or some retry configuration. The core is really: Where is my etcd and how can I log in? Where in etcd is my leader key and which IP is assigned to which device. That is the entire magic.
vip-manager helps to make a cluster fully transparent. It is available as binary packages for the most common Linux distributions and Windows. We maintain the package and add improvements as needed. One improvement worth pointing out is that vip-manager is also able to work on Hetzner (a leading German hosting company). We are able to talk to the Hetzner API to move IPs around. The reason I am mentioning this is that if you've got special requirements vip-manager can be adjusted to your needs with reasonable effort.
I hope you enjoyed this posting about virtual IPs and PostgreSQL clustering. If you want to know more about recent software released, I want to point you to Scalefield, a solution to automate PostgreSQL deployments using Kubernetes.
If you want to read something right now, I want to tell you about one more tool we have recently implemented in Go (golang). pg_timetable is a cutting-edge job scheduler for PostgreSQL, which allows you to run SQL code as well as built-ins (email, etc.) and other executables. Check out our posts about that here.
In SQL, the concept of foreign keys is an important one that can be found in all professional databases used in the industry. The core idea is to prevent your PostgreSQL database from storing inconsistent data by enforcing constraints ensuring the correctness of your tables (at least as far as relations between objects are concerned). Referential integrity is therefore one of the most important concepts ever invented in IT.
However, foreign keys will introduce some issues which you have to take care of when writing applications. If there are no foreign keys, you can insert data into any table in any order. PostgreSQL does not care. However, if a foreign key is in place, order starts to matter (at least in a typical scenario but more on that later).
To show the importance of order, we have to create a data model first:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE TABLE t_currency ( id int, shortcut char (3), PRIMARY KEY (id) ); CREATE TABLE t_location ( id int, location_name text, PRIMARY KEY (id) ); CREATE TABLE t_product ( id int, name text, currency_id int REFERENCES t_currency (id), PRIMARY KEY (id) ); CREATE TABLE t_product_desc ( id int, product_id int REFERENCES t_product (id), description text, PRIMARY KEY (id) ); CREATE TABLE t_product_stock ( product_id int REFERENCES t_product (id), location_id int REFERENCES t_location (id), amount numeric CHECK (amount >= 0) ); |
We want to store currencies, products, as well as product descriptions. Basically it is a very simple data model. Let us see if we happen to insert into the product table:
|
1 2 3 4 5 |
test=# INSERT INTO t_product VALUES (1, 'PostgreSQL consulting', 1); ERROR: insert or update on table 't_product' violates foreign key constraint 't_product_currency_id_fkey' DETAIL: Key (currency_id)=(1) is not present in table 't_currency'. test=# INSERT INTO t_product VALUES (1, 'PostgreSQL consulting', NULL); INSERT 0 1 |
Logically the first INSERT is going to fail because currency number 1 does not exist yet. If we want to INSERT, we have to use a NULL value (= unknown currency). In order words: We have to fill the currency table first, then insert locations, and so on. The order does matter in the default case.
If you have to start using an existing data model, it can be a bit hard to wrap your head around this stuff. Populating an empty data model can be a bit tricky. So why not write a query telling us the order in which we are supposed to insert data?
Well, here is that magic query...
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
WITH RECURSIVE fkeys AS ( /* source and target tables for all foreign keys */ SELECT conrelid AS source, confrelid AS target FROM pg_constraint WHERE contype = 'f' ), tables AS ( ( /* all tables ... */ SELECT oid AS table_name, 1 AS level, ARRAY[oid] AS trail, FALSE AS circular FROM pg_class WHERE relkind = 'r' AND NOT relnamespace::regnamespace::text LIKE ANY (ARRAY['pg_catalog', 'information_schema', 'pg_temp_%']) EXCEPT /* ... except the ones that have a foreign key */ SELECT source, 1, ARRAY[ source ], FALSE FROM fkeys ) UNION ALL /* all tables with a foreign key pointing a table in the working set */ SELECT fkeys.source, tables.level + 1, tables.trail || fkeys.source, tables.trail @> ARRAY[fkeys.source] FROM fkeys JOIN tables ON tables.table_name = fkeys.target /* * Stop when a table appears in the trail the third time. * This way, we get the table once with 'circular = TRUE'. */ WHERE cardinality(array_positions(tables.trail, fkeys.source)) < 2 ), ordered_tables AS ( /* get the highest level per table */ SELECT DISTINCT ON (table_name) table_name, level, circular FROM tables ORDER BY table_name, level DESC ) SELECT table_name::regclass, level FROM ordered_tables WHERE NOT circular ORDER BY level, table_name; |
The query is not trivial to read, but I have done my best to document it a bit. Basically, the PostgreSQL system tables have all the information we need to determine the correct order. Here is the output:
|
1 2 3 4 5 6 7 8 |
table_name | level -----------------+------- t_currency | 1 t_location | 1 t_product | 2 t_product_desc | 3 t_product_stock | 3 (5 rows) |
As you can see, the query has correctly given us the tables in the desired order. First, we have to insert into all tables at level one and so on. If we stick to this order, referential integrity will always be ensured (assuming the data is correct).
In some cases, the insertion order can be a nasty thing to deal with. What if we had the means to tell PostgreSQL to ignore the order and check integrity on commit instead? This is exactly what "initially deferred" does. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
BEGIN; CREATE TABLE t_currency ( id int, shortcut char (3), PRIMARY KEY (id) ); CREATE TABLE t_product ( id int, name text, currency_id int REFERENCES t_currency (id) INITIALLY DEFERRED, PRIMARY KEY (id) ); INSERT INTO t_product VALUES (1, 'PostgreSQL support', 1); INSERT INTO t_currency VALUES (1, 'EUR'); COMMIT; |
In this case, we can modify data in any order we want. As long as integrity is guaranteed to be intact at the end of the transaction, PostgreSQL is perfectly fine. PostgreSQL will postpone the constraint check and take some burden off the developer.
If you want to learn more about advanced SQL, you might want to take a look at my blog about some more advanced windowing functions (with ties). So put on your tie and read to learn more.
Partitioning data is a well known way to optimize big tables into smaller ones using a given attribute. And while creating a partitioned table structure itself is not complicated, the migration of a table on a live system can be tricky. Our solution offers a simple way to solve this problem.
The usual way can be summarized the following:
The disadvantage of the method above is that it is relatively complex; the triggers that secure data integrity must be tested. It also creates data redundancy, because during migration the data must be duplicated. It also requires a migration plan, and a change in the application when switching from the old table to the new one - and that may or may not be an issue.
During data migration the particular difficulty is: how to be certain that if a given batch of data is being migrated and entries of the same batch of data is updated or deleted, the correct values are going to be present in the new, partitioned table. It may mean some freeze of insert/updated during migration (see answer 13) or some logic that re-scans the data in the batch after migration for any changes and gives priority to the original table. At think project! we needed both to be sure that we have no data loss - that may not be an issue in some scenarios -, and that the downtime/service time is minimal, or the better, non existent.
Below, we would like to present a simple and robust solution that does not require duplication of the data, nor downtime or any freeze during migration and overall it is a minimum intrusion to the system. The solution is using the original table as the mother table for the partitioning. The data is moved from the mother table using a BEFORE UPDATE trigger, updating an extra column of each row by some migration process. This update value is added only for this purpose. In case a row is still in the mother table when queried - Postgres will deliver it from the mother table before consulting a partition.
Below we demonstrate how to set up a basic partitioning, and after that our proposal for the migration process is discussed.
Let's take the source table that acts as our live table. The part_value will be the base of our partitioning.
|
1 2 3 4 5 6 7 8 |
CREATE TABLE livedata ( id SERIAL PRIMARY KEY, some_data TEXT, part_value INTEGER NOT NULL ); INSERT INTO livedata(part_value,some_data) VALUES (1,'this'), (1,'this_is'),(2,'that'); |
Let's create the child tables for partitioning:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE livedata_part_1 (LIKE livedata); ALTER TABLE livedata_part_1 INHERIT livedata; ALTER TABLE livedata_part_1 ADD CONSTRAINT part_value CHECK ( part_value = 1 ); CREATE TABLE livedata_part_2 (LIKE livedata); ALTER TABLE livedata_part_2 INHERIT livedata; ALTER TABLE livedata_part_2 ADD CONSTRAINT part_value CHECK ( part_value = 2 ); |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE OR REPLACE FUNCTION livedata_insert_function() RETURNS TRIGGER AS $$ BEGIN IF NEW.part_value BETWEEN 1 AND 2 THEN EXECUTE 'INSERT INTO livedata_part_'||NEW.part_value ||' VALUES ($1.*)' USING NEW; ELSE RAISE EXCEPTION 'part_value is out of range'; END IF; RETURN NULL; END; $$ LANGUAGE plpgsql; |
Bind the function to a trigger:
|
1 2 3 |
CREATE TRIGGER tr_insert_livedata BEFORE INSERT ON livedata FOR EACH ROW EXECUTE PROCEDURE livedata_insert_function(); |
Up to this point we have prepared the partitions and the insert trigger, following the standard way. As soon as the function is bound to a trigger, the mother table inserts will land in the child tables, and will be delivered from there. The existing data will be delivered from the mother table.
|
1 2 |
INSERT INTO livedata(some_data, part_value) VALUES ('new_one',1); SELECT * FROM livedata_part_1; |
should show the new entry in the partition table, as expected.
Now, let's migrate the data from the mother table. Our logic uses an UPDATE trigger. For the controlled migration we use a value to update and for this we choose to add an extra BOOL column without default values. This column can also be handy for monitoring the migration process. The application/client can be unaware of it's existence. Without default values and indices this modification runs in 10-100ms even if the table is huge.
|
1 |
ALTER TABLE livedata ADD COLUMN in_partition BOOL; |
Now let's add a BEFORE UPDATE trigger, so that it copies the values from the mother table to the partition and then performs an update on the copied value, setting the in_partition flag on the updated row. This will be our migration function. The migration will simply be an update on the rows on the mother table setting the in_partition flag to true.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE OR REPLACE FUNCTION migrate_data() RETURNS trigger AS $$ DECLARE partition_table TEXT; BEGIN -- the trigger table name is the suffix for the partition table partition_table := TG_TABLE_NAME || '_part_' || NEW.part_value; EXECUTE format('DELETE FROM %s WHERE id = %s',TG_TABLE_NAME,NEW.id); EXECUTE format('INSERT INTO %s (id, some_data, part_value, in_partition) VALUES (%s,%L,%s,TRUE)' ,partition_table, NEW.id,NEW.some_data,NEW.part_value); RETURN NULL; END; $$ LANGUAGE plpgsql; DROP TRIGGER IF EXISTS tr_migrate_data_on_update ON livedata; CREATE TRIGGER tr_migrate_data_on_update BEFORE UPDATE ON livedata FOR EACH ROW EXECUTE PROCEDURE migrate_data(); |
The migration happens when there is any update on a not yet migrated row.
|
1 |
UPDATE livedata SET some_data = 'new_value' WHERE id = 1; |
To migrate the values through some migration process, we use the in_partition BOOL flag. Eg. doing a batch migration by part_value simply execute the following:
|
1 |
UPDATE livedata SET in_partition = true WHERE part_value = 1; |
The race conditions are going to be handled by the database itself. The application code requires no change, all the migration happens inside the database. The data is not duplicated during the process and the integrity is maintained by the database, and requires very little extra code. To check if the migration is finished, either the size of the source table should be checked using the PostgreSQL internals, or adding the following to the insert_trigger() directly after the IF ... BETWEEN statement we can set the in_partition attribute to true on each insert.
|
1 |
NEW.in_partition := true; |
In this case there is no need to set this attribute to true in the migrate_data(). Using this logic if the following query returns no rows the source table is fully migrated:
|
1 |
SELECT id FROM livedata WHERE in_partition IS NULL; |
This blogpost was written by László Forró (LinkedIn) and André Plöger (LinkedIn & Xing).
To dig a bit deeper into zheap and PostgreSQL storage technology in general I decided to provide some more empirical information about space consumption. As stated in my previous blog post about zheap is more efficient in terms of storage consumption. The reasons are:
The question is: While those theoretical statements are true one wants to know what this means in a real-world scenario. This blog will shed some light on this question and give you some more empirical insights as to what is to be expected as soon as zheap is production-ready (which it is NOT as of October 2020).
To show the differences in storage consumption I have created some sample data. To make it fair I have first added data to a temporary table which is in memory. This way there are no undesired side effects:
|
1 2 3 4 5 6 7 8 |
test=# SET temp_buffers TO '1 GB'; SET test=# CREATE TEMP TABLE raw AS SELECT id, hashtext(id::text) as name, random() * 10000 AS n, true AS b FROM generate_series(1, 10000000) AS id; SELECT 10000000 |
10 million rows will roughly translate to half a gigabyte of data:
|
1 2 3 4 5 6 |
test=# d+ List of relations Schema | Name | Type | Owner | Persistence | Size | Description -----------+------+-------+-------+-------------+--------+------------- pg_temp_5 | raw | table | hs | temporary | 498 MB | (1 row) |
A standard temporary table is absolutely fine for our purpose.
One of my favorite features in PostgreSQL is CREATE TABLE … LIKE …. It allows you to quickly create identical tables. This feature is especially useful if you want to clone a table containing a large number of columns and you don't want to to list them all, manually create all indexes etc.
Copying the data from "raw" into a normal heap table takes around 7.5 seconds:
|
1 2 3 4 5 6 7 8 |
test=# timing Timing is on. test=# CREATE TABLE h1 (LIKE raw) USING heap; CREATE TABLE Time: 7.836 ms test=# INSERT INTO h1 SELECT * FROM raw; INSERT 0 10000000 Time: 7495.798 ms (00:07.496) |
Let us do the same thing. This time we will use a zheap table. Note that to use zheap one has to add a USING-clause to the statement:
|
1 2 3 4 5 6 |
test=# CREATE TABLE z1 (LIKE raw) USING zheap; CREATE TABLE Time: 8.045 ms test=# INSERT INTO z1 SELECT * FROM raw; INSERT 0 10000000 Time: 27947.516 ms (00:27.948) |
As you can see creating the content of the table takes a bit longer but the difference in table size is absolutely stunning:
|
1 2 3 4 5 6 7 8 |
test=# d+ List of relations Schema | Name | Type | Owner | Persistence | Size | Description -----------+------+-------+-------+-------------+--------+------------- pg_temp_5 | raw | table | hs | temporary | 498 MB | public | h1 | table | hs | permanent | 498 MB | public | z1 | table | hs | permanent | 251 MB | (3 rows) |
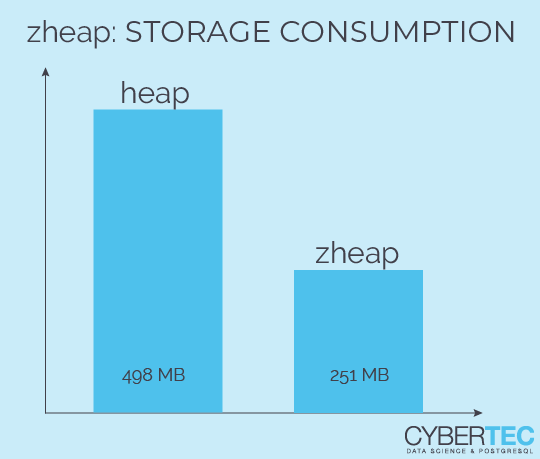
The zheap table is roughly 50% smaller than the normal PostgreSQL storage format. The main question naturally arising is: Why is that the case? There are basically two important factors:
Let us consider the tuple header first: The new tuple header is only 5 bytes which is almost 20 bytes less per row. That alone saves us around 200 MB of storage space. The reason for the smaller tuple header is that the visibility information has been moved from the row to the page level ("transaction slots"). The more columns you've got the lower the overall percentage will be but if your table is really narrow the difference between heap and zheap is very significant.
NOTE: Reduced storage consumption is mostly an issue for tables containing just a few columns - if your table contains X00 columns it is less of an issue.
UPDATE has traditionally been an important thing when talking about zheap in general. So let us see what happens when a table is modified:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
test=# BEGIN; BEGIN test=*# SELECT pg_size_pretty(pg_relation_size('z1')); pg_size_pretty ---------------- 251 MB (1 row) test=*# UPDATE z1 SET id = id + 1; UPDATE 10000000 test=*# SELECT pg_size_pretty(pg_relation_size('z1')); pg_size_pretty ---------------- 251 MB (1 row) |
In my case the size of the row is identical. We simply want to change the ID of the data. What is important to notice here is that the size of the table is identical. In case of heap the size of the data file would have doubled.
To support transactions UPDATE must not forget the old rows. Therefore the data has to be "somewhere". This "somewhere" is called "undo":
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[hs@hs-MS-7817 undo]$ pwd /home/hs/db13/base/undo [hs@hs-MS-7817 undo]$ ls -l | tail -n 10 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003EC00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003ED00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003EE00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003EF00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F000000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F100000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F200000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F300000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F400000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F500000 |
The undo area contains a couple of files (1 MB each) holding the undo data which is necessary to handle rollback properly (= putting the old data back into the table).
In other words: Being able to handle transactions is not free - the space needed to do that is simply handled in a different way.
If you are using a normal heap ROLLBACK is basically free because a transaction can simply leave all its obsolete trash behind. Not so if you are using zheap to store data.
Let us compare and see:
|
1 2 3 4 5 6 7 8 9 |
test=# BEGIN; BEGIN Time: 0.309 ms test=*# UPDATE h1 SET id = id - 1 WHERE id < 100000; UPDATE 99999 Time: 741.518 ms test=*# ROLLBACK; ROLLBACK Time: 0.181 ms |
As you can see the ROLLBACK is really quick - it does basically nothing. The situation is quite different in case of zheap
|
1 2 3 4 5 6 7 8 9 |
test=# BEGIN; BEGIN Time: 0.151 ms test=*# UPDATE z1 SET id = id - 1 WHERE id < 100000; UPDATE 99998 Time: 1066.378 ms (00:01.066) test=*# ROLLBACK; ROLLBACK Time: 41.539 ms |
41 milliseconds is not much but it is still a lot more than a fraction of a millisecond. Of course, things are slower but the main issue is that zheap is all about table bloat. Avoiding table bloat has major advantages in the long run. One should therefore see this performance data in a different light. One should also keep in mind that COMMIT is (in most cases) ways more likely than ROLLBACK. Thus putting a price tag on ROLLBACK might not be so problematic after all.
If you want to give zheap a try we suggest taking a look at our Github repo. All the code is there. At the moment we have not prepared binaries yet. We will soon release Docker containers to make it easier for users to try out this awesome new technology.
We again want to point out that zheap is still in development - it is not production-ready. However, this is a really incredible technology and we again want to thank Heroic Labs for the support we are receiving. We also want to thank EDB for the work on zheap they have done over the years.
If you want to learn more about storage efficiency, alignment etc. we recommend checking out my blog post about column order. In addition, if you want to know more about specific aspects of zheap feel free to leave a comment below so that we can maybe address those issues in the near future and dedicate entire articles to it.
Temporary tables have been around forever and are widely used by application developers. However, there is more to temporary tables than meets the eye. PostgreSQL allows you to configure the lifespan of a temporary table in a nice way and helps to avoid some common pitfalls.
By default, a temporary table will live as long as your database connection. It will be dropped as soon as you disconnect. In many cases this is the behavior people want:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
tmp=# CREATE TEMPORARY TABLE x (id int); CREATE TABLE tmp=# d List of relations Schema | Name | Type | Owner -----------+------+-------+------- pg_temp_3 | x | table | hs (1 row) tmp=# q iMac:~ hs$ psql tmp psql (12.3) Type 'help' for help. tmp=# d Did not find any relations. |
Once we have reconnected, the table is gone for good. Also, keep in mind that the temporary table is only visible within your session. Other connections are not going to see the table (which is, of course, the desired behavior). This also implies that many sessions can create a temporary table having the same name.
However, a temporary table can do more. The most important thing is the ability to control what happens on commit:
|
1 |
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] |
As you can see, there are three options. "PRESERVE ROWS" is the behavior you have just witnessed. Sometimes you don't want that. It is therefore also possible to empty a temporary table on commit:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
tmp=# BEGIN; BEGIN tmp=# CREATE TEMP TABLE x ON COMMIT DELETE ROWS AS SELECT * FROM generate_series(1, 5) AS y; SELECT 5 tmp=# SELECT * FROM x; y --- 1 2 3 4 5 (5 rows) tmp=# COMMIT; COMMIT tmp=# SELECT * FROM x; y --- (0 rows) |
In this case, PostgreSQL simply leaves us with an empty table as soon as the transaction ends. The table itself is still around and can be used.
Let's drop the table for now:
|
1 2 |
tmp=# DROP TABLE x; DROP TABLE |
|
1 2 3 4 5 6 7 8 9 10 |
tmp=# BEGIN; BEGIN tmp=# CREATE TEMP TABLE x ON COMMIT DROP AS SELECT * FROM generate_series(1, 5) AS y; SELECT 5 tmp=# COMMIT; COMMIT tmp=# SELECT * FROM x; ERROR: relation 'x' does not exist LINE 1: SELECT * FROM x; |
PostgreSQL will throw an error because the table is already gone. What is noteworthy here is that you can still use WITH HOLD cursors as shown in the next example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
tmp=# BEGIN; BEGIN tmp=# CREATE TEMP TABLE x ON COMMIT DROP AS SELECT * FROM generate_series(1, 5) AS y; SELECT 5 tmp=# DECLARE mycur CURSOR WITH HOLD FOR SELECT * FROM x; DECLARE CURSOR tmp=# COMMIT; COMMIT tmp=# FETCH ALL FROM mycur; y --- 1 2 3 4 5 (5 rows) |
The table itself is still gone, but the WITH HOLD cursors will ensure that the "content" of the cursor will survive the end of the transaction. Many people don't expect this kind of behavior, but it makes sense and can come in pretty handy.
If you are using temporary tables, it makes sense to keep them relatively small. In some cases, however, a temporary table might be quite large for whatever reason. To ensure that performance stays good, you can tell PostgreSQL to keep more of a temporary table in RAM. temp_buffers is the parameter in postgresql.conf you should be looking at in this case:
|
1 2 3 4 5 |
tmp=# SHOW temp_buffers; temp_buffers -------------- 8MB (1 row) |
The default value is 8 MB. If your temporary tables are large, increasing this value certainly makes sense.
If you want to find out more about PostgreSQL database performance in general, consider checking out my post about three ways to detect and fix slow queries.
Is your database growing at a rapid rate? Does your database system slow down all the time? And maybe you have trouble understanding why this happens? Maybe it is time to take a look at pg_squeeze and fix your database once and for all. pg_squeeze has been designed to shrink your database tables without downtime. No more need for VACUUM FULL - pg_squeeze has it all.
The first question any PostgreSQL person will ask is: Why not use VACUUM or VACUUM FULL? There are various reasons: A normal VACUUM does not really shrink the table in disk. Normal VACUUM will look for free space, but it won’t return this space to the operating system. VACUUM FULL does return space to the operating system but it needs a table lock. In case your table is small this usually does not matter. However, what if your table is many TBs in size? You cannot simply lock up a large table for hours just to shrink it after table bloat has ruined performance. pg_squeeze can shrink large tables using only a small, short lock.
However, there is more. The following listing contains some of the operations pg_squeeze can do with minimal locking:
After this basic introduction it is time to take a look and see how pg_squeeze can be installed and configured.
pg_squeeze can be downloaded for free from our GitHub repository. However, binary packages are available for most Linux distributions. If you happen to run Solar, AIX, FreeBSD or some other less widespread operating system just get in touch with us. We are eager to help.
After you have compiled pg_squeeze or installed the binaries some changes have to be made to postgresql.conf:
|
1 2 3 |
wal_level = logical max_replication_slots = 10 # minimum 1 shared_preload_libraries = 'pg_squeeze' |
The most important thing is to set the wal_level to logical. Internally, pg_squeeze works as follows: It creates a new datafile (snapshot) and then applies changes made to the table while this snapshot is copied over. This is done using logical decoding. Of course logical decoding needs replication slots. Finally the library has to be loaded when PostgreSQL is started. This is basically it - pg_squeeze is ready for action.
Before we dive deeper into pg_squeeze it is important to understand table bloat in general. Let us take a look at the following example:
|
1 2 3 4 5 6 7 8 9 10 |
test=# CREATE TABLE t_test (id int); CREATE TABLE test=# INSERT INTO t_test SELECT * FROM generate_series(1, 2000000); INSERT 0 2000000 test=# SELECT pg_size_pretty(pg_relation_size('t_test')); pg_size_pretty ---------------- 69 MB (1 row) |
Once we have imported 2 million rows the size of the table is 69 MB. What happens if we update these rows and simply add one?
|
1 2 3 4 5 6 7 |
test=# UPDATE t_test SET id = id + 1; UPDATE 2000000 test=# SELECT pg_size_pretty(pg_relation_size('t_test')); pg_size_pretty ---------------- 138 MB (1 row) |
The size of the table is going to double. Remember, UPDATE has to duplicate the row which of course eats up some space. The most important observation, however, is: If you run VACUUM the size of the table on disk is still 138 MB - storage IS NOT returned to the operating system. VACUUM can shrink tables in some rare instances. However, in reality the table is basically never going to return space to the filesystem which is a major issue. Table bloat is one of the most frequent reasons for bad performance, so it is important to either prevent it or make sure the table is allowed to shrink again.
If you want to use pg_squeeze you have to make sure that a table has a primary key. It is NOT enough to have unique indexes - it really has to be a primary key. The reason is that we use replica identities internally, so we basically suffer from the same restrictions as other tools using logical decoding.
Let us add a primary key and squeeze the table:
|
1 2 3 4 5 6 |
test=# ALTER TABLE t_test ADD PRIMARY KEY (id); ALTER TABLE test=# SELECT squeeze.squeeze_table('public', 't_test', null, null, null); squeeze_table --------------- (1 row) |
Calling pg_squeeze manually is one way to handle a table. It is the preferred method if you want to shrink a table once. As you can see the table is smaller than before:
|
1 2 3 4 5 |
test=# SELECT pg_size_pretty(pg_relation_size('t_test')); pg_size_pretty ---------------- 69 MB (1 row) |
The beauty is that minimal locking was needed to do that.
pg_squeeze has a builtin job scheduler which can operate in many ways. It can tell the system to squeeze a table within a certain timeframe or trigger a process in case some thresholds have been reached. Internally pg_squeeze uses configuration tables to control its behavior. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
test=# d squeeze.tables Table 'squeeze.tables' Column | Type | Collation | Nullable | Default ------------------+------------------+-----------+----------+-------------------------------------------- id | integer | | not null | nextval('squeeze.tables_id_seq'::regclass) tabschema | name | | not null | tabname | name | | not null | clustering_index | name | | | rel_tablespace | name | | | ind_tablespaces | name[] | | | free_space_extra | integer | | not null | 50 min_size | real | | not null | 8 vacuum_max_age | interval | | not null | '01:00:00'::interval max_retry | integer | | not null | 0 skip_analyze | boolean | | not null | false schedule | squeeze.schedule | | not null | Indexes: 'tables_pkey' PRIMARY KEY, btree (id) 'tables_tabschema_tabname_key' UNIQUE CONSTRAINT, btree (tabschema, tabname) Check constraints: 'tables_free_space_extra_check' CHECK (free_space_extra >= 0 AND free_space_extra < 100) 'tables_min_size_check' CHECK (min_size > 0.0::double precision) Referenced by: TABLE 'squeeze.tables_internal' CONSTRAINT 'tables_internal_table_id_fkey' FOREIGN KEY (table_id) REFERENCES squeeze.tables(id) ON DELETE CASCADE TABLE 'squeeze.tasks' CONSTRAINT 'tasks_table_id_fkey' FOREIGN KEY (table_id) REFERENCES squeeze.tables(id) ON DELETE CASCADE Triggers: tables_internal_trig AFTER INSERT ON squeeze.tables FOR EACH ROW EXECUTE FUNCTION squeeze.tables_internal_trig_func() |
The last column here is worth mentioning: It is a custom data type capable of holding cron-style scheduling information. The custom data type looks as follows:
|
1 2 3 4 5 6 7 8 9 |
test=# d squeeze.schedule Composite type 'squeeze.schedule' Column | Type | Collation | Nullable | Default ---------------+------------------+-----------+----------+--------- minutes | squeeze.minute[] | | | hours | squeeze.hour[] | | | days_of_month | squeeze.dom[] | | | months | squeeze.month[] | | | days_of_week | squeeze.dow[] | | | |
If you want to make sure that pg_squeeze takes care of a table simple insert the configuration into the table:
|
1 2 |
test=# INSERT INTO squeeze.tables (tabschema, tabname, schedule) VALUES ('public', 't_test', ('{30}', '{22}', NULL, NULL, '{3, 5}')); INSERT 0 1 |
In this case public.t_test will be squeezed at 22:30h in the evening every 3rd and 5th day of the week. The main question is: When is that? In our setup days 0 and 7 are sundays. So 3 and 5 means wednesday and friday at 22:30h.
Let us check what the configuration looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
test=# x Expanded display is on. test=# SELECT *, (schedule).* FROM squeeze.tables; -[ RECORD 1 ]----+---------------------- id | 1 tabschema | public tabname | t_test clustering_index | rel_tablespace | ind_tablespaces | free_space_extra | 50 min_size | 8 vacuum_max_age | 01:00:00 max_retry | 0 skip_analyze | f schedule | ({30},{22},,,'{3,5}') minutes | {30} hours | {22} days_of_month | months | days_of_week | {3,5} |
Once this configuration is in place, pg_squeeze will automatically take care of things. Everything is controlled by configuration tables so you can easily control and monitor the inner workings of pg_squeeze.
If pg_squeeze decides to take care of a table it can happen that the reorg process actually fails. Why is that the case? One might drop a table and recreate it, the structure might change or pg_squeeze might not be able to get the brief lock at the end. Of course it is also possible that the tablespace you want to move a table too does not have enough space. There are many issues which can lead to errors. Therefore one has to track those reorg processes.
The way to do that is to inspect squeeze.errors:
|
1 2 3 4 |
test=# SELECT * FROM squeeze.errors; id | occurred | tabschema | tabname | sql_state | err_msg | err_detail ----+----------+-----------+---------+-----------+---------+------------ (0 rows) |
This log table contains all the relevant information needed to track things fast and easily.
pg_squeeze is not the only Open Source tool we have published for PostgreSQL. If you are looking for a cutting edge scheduler we recommend taking a look at what pg_timetable has to offer.
In PostgreSQL table bloat has been a primary concern since the original MVCC model was conceived. Therefore we have decided to do a series of blog posts discussing this issue in more detail. What is table bloat in the first place? Table bloat means that a table and/or indexes are growing in size even if the amount of data stored in the database does not grow at all. If one wants to support transactions it is absolutely necessary not to overwrite data in case it is modified because one has to keep in mind that people might want to read an old row while it is modified or rollback a transaction.
Therefore bloat is an intrinsic thing related to MVCC in PostgreSQL. However, the way PostgreSQL stores data and handles transactions is not the only way a database can handle transactions and concurrency. Let us see which other options there are:
In MS SQL you will find a thing called tempdb while Oracle and MySQL put old versions into the redo log. As you might know PostgreSQL copies rows on UPDATE and stores them in the same table. Firebird is also storing old row versions inline.
There are two main points I want to make here:
Getting rid of rows is definitely an issue. In PostgreSQL removing old rows is usually done by VACUUM. However, in some cases VACUUM cannot keep up or space is growing for some other reasons (usually long transactions). We at CYBERTEC have blogged extensively about that scenario.
“No solution is without tradeoffs” is also an important aspect of storage. There is no such thing as a perfect storage engine - there are only storage engines serving a certain workload well. The same is true for PostgreSQL: The current table format is ideal for many workloads. However, there is also a dark side which leads us back to where we started: Table bloat. If you are running UPDATE-intense workloads it happens more often than not that the size of a table is hard to keep under control. This is especially true if developers and system administrators are not fully aware of the inner workings of PostgreSQL in the first place.
zheap is a way to keep table bloat under control by implementing a storage engine capable of running UPDATE-intense workloads a lot more efficiently. The project has originally been started by EnterpriseDB and a lot of effort has been put into the project already.
To make zheap ready for production we are proud to announce that our partners at Heroic Labs have committed to fund the further development of zheap and release all code to the community. CYBERTEC has decided to double the amount of funding and to put up additional expertise and manpower to move zheap forward. If there are people, companies, etc. who are also interested in helping us move zheap forward we are eager to team up with everybody willing to make this great technology succeed.
Let us take a look at the key design goals:
So let us see how those goals can be achieved in general.
zheap is a completely new storage engine and it therefore makes sense to dive into the basic architecture. Three essential components have to work together:
Let us take a look at the layout of a zheap page first. As you know PostgreSQL typically sees tables as a sequence of 8k blocks, so the layout of a page is definitely important:
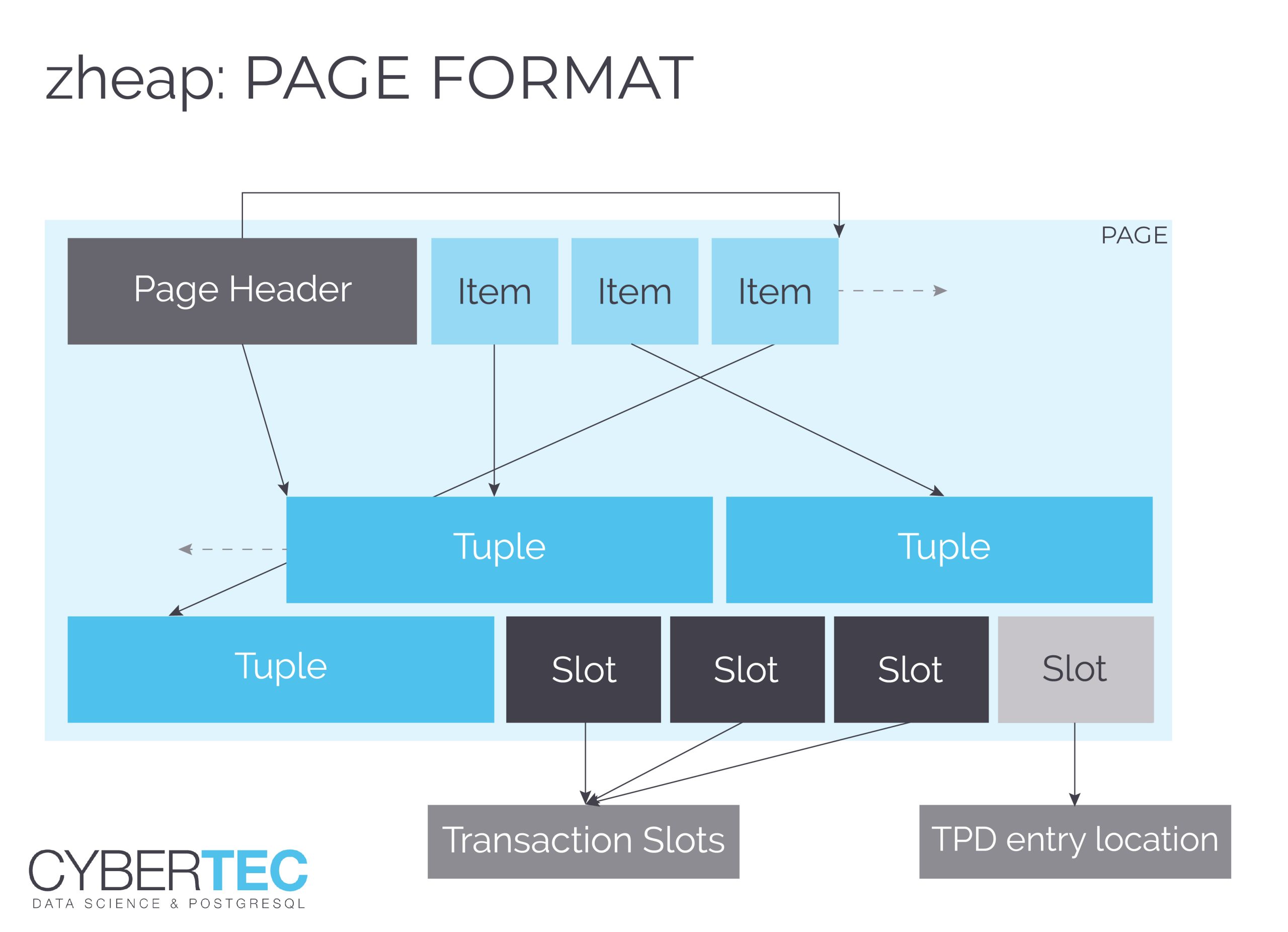
At first glance, this image looks almost like a standard PostgreSQL 8k page but in fact it is not. The first thing you might notice is that tuples are stored in the same order as item entries at the beginning of the page to allow for faster scans. The next thing we see here is the presence of “slot” entries at the end of the page. In a standard PostgreSQL table visibility information is stored as part of the row which needs a lot of space. In zheap transaction information has been moved to the page which significantly reduces the size of data (which in turn translates to better performance).
A transaction occupies 16 bytes of storage and contains the following information: transaction id, epoch and the latest undo record pointer of that transaction. A row points to a transaction slot. The default number of transaction slots in the table is 4 which is usually ok for big tables. However, sometimes more transaction slots are needed. In this case, zheap has something called “TPD” which is nothing more than an overflow area to store additional transaction information as needed.
Here is the basic layout:
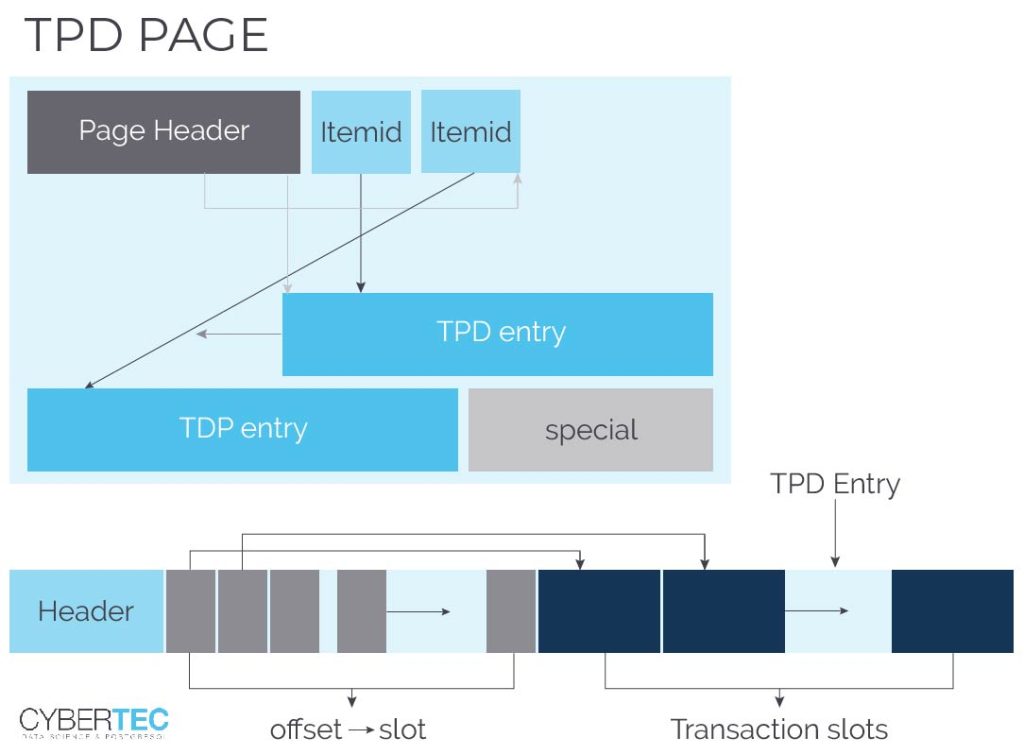
Sometimes many transaction slots are needed for a single page. TPD offers a flexible way to handle that. The question is: Where does zheap store TPD data? The answer is: These special pages are interleaved with the standard data pages. They are just marked in a special way to ensure that sequential scans won’t touch them. To track these special purpose pages zheap uses a meta page to track them:

TDP is simply a way to make transaction slots more scalable. Having some slots in the block itself reduces the need to excessively touch pages. If more are needed TPD is an elegant way out. In a way it is the best of both worlds.
Transaction slots can be reused after a transaction ends.
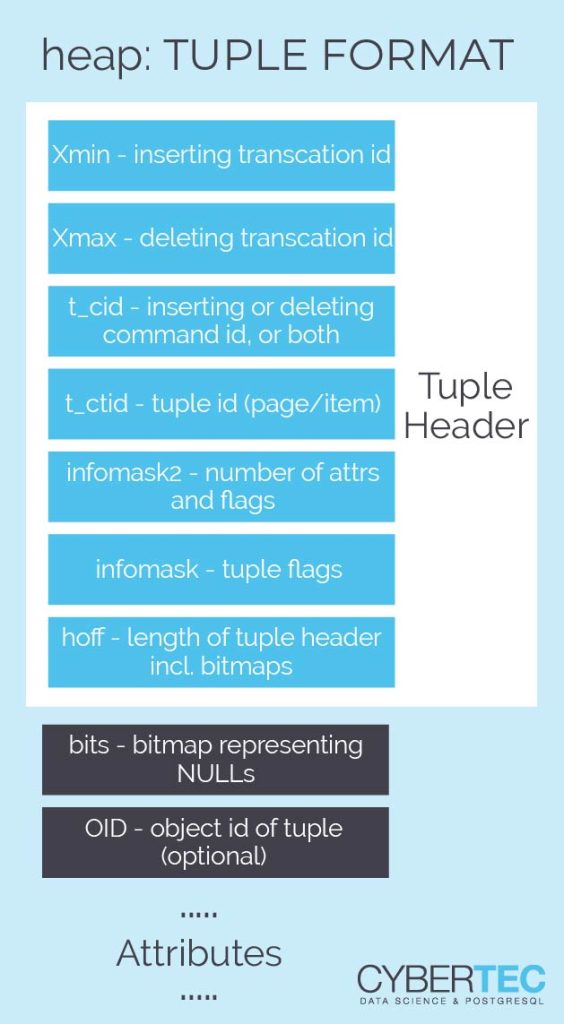
The next important part of the puzzle is the layout of a single tuple: In PostgreSQL a standard heap tuple has a 20+ byte header because all the transactional information is stored in a tuple. Not so in this case. All transactional information has been moved to page level structures (transaction slots). This is super important: The header has therefore been reduced to merely 5 bytes. But there are more optimizations going on here: A standard tuple has to use CPU alignment (padding) between the tuple header and the real data in the row. This can burn some bytes for every single row in the table. zheap doesn't do that, which leads to more tightly packed storage.
Additional space is saved by removing the padding from pass-by-value data types. All those optimizations mean that we can save valuable space in every single row of the table. URSELOCATIONSTARTENDTIMELANGUAGE
| Here is what a standard PostgreSQL tuple header looks like:
|
Now let us compare this to a zheap tuple:
|
As you can see a zheap tuple is a lot smaller than a normal heap tuple. As the transactional information has been unified in the transaction slot machinery, we don’t have to handle visibility on the row level anymore but can do it more efficiently on the page level.
By shrinking the storage footprint zheap will contribute to good performance.
One of the most important things when talking about zheap is the notion of “undo”. What is the purpose of this thing in the first place? Let us take a look and see: Consider the following operation:
|
1 2 3 4 |
BEGIN; UPDATE tab SET x = 7 WHERE x = 5; … COMMIT / ROLLBACK; |
To ensure that transactions can operate correctly UPDATE cannot just overwrite the old value and forget about it. There are two reasons for that: First of all, we want to support concurrency. Many users should be able to read data while it is modified. The second problem is that updating a row does not necessarily mean that it will be committed. Thus we need a way to handle ROLLBACK in a useful way. The classical PostgreSQL storage format will simply copy the row INSIDE standard heap which leads to all those bloat related issues we have discussed on our blog already.
The way zheap approaches things here is a bit different: In case a modification is made the system writes “undo” information to fix it in case the transaction has to be aborted for whatever reason. This is the fundamental concept applicable to INSERT, UPDATE, and DELETE. Let us go through those operations one by one and see how it works:
In case of INSERT zheap has to allocate a transaction slot and then emit an undo entry to fix things on error. In case of INSERT the TID is the most relevant information needed by undo. Space can be reclaimed instantly after an INSERT has been rolled back which is a major difference between zheap and standard heap tables in PostgreSQL.
An UPDATE statement is far more complicated: There are basically two cases:
In case the old row is shorter than the new one we can simply overwrite it and emit an undo entry holding the complete old row. In short: We hold the new row in zheap and a copy of the old row in undo so that we can copy it back to the old structure in case it is needed.
What happens if the new row does not fit in? In this case performance will be worse because zheap essentially has to perform a DELETE / INSERT operation which is of course not as efficient as an in-place UPDATE.
Space can instantly be reclaimed in the following cases:
Finally there is DELETE. To handle the removal of a row zheap has to emit an undo record to put the old row back in place in case of ROLLBACK. The row has to be removed from the zheap during DELETE.
Up to now we have spoken quite a bit about undo and rollback. However, let us dive a bit deeper and see how undo, rollback, and so on interact with each other.
In case a ROLLBACK happens the undo has to make sure that the old state of the table is restored. Thus the undo action we have scheduled before has to be executed. In case of errors the undo action is applied as part of a new transaction to ensure success.
Ideally, all undo action associated with a single page is applied at once to cut down on the amount of WAL that has to be written. A nice side effect of this strategy is also that we can reduce page-level locking to the absolute minimum which reduces contention and therefore helps contribute to good performance.
So far this sounds easy but let us consider an important use case: What happens in the event of a really long transaction? What happens if a terabyte of data has to be rolled back at once? End users certainly don’t appreciate never-ending rollbacks. It is also worth keeping in mind that we must also be prepared for a crash during rollback.
What happens is that if undo action is larger than a certain configurable threshold the job is done by a background worker process. This is a really elegant solution that helps to maintain a good end-user experience.
Undo itself can be removed in three cases:
Let us take a look at a basic architecture diagram:
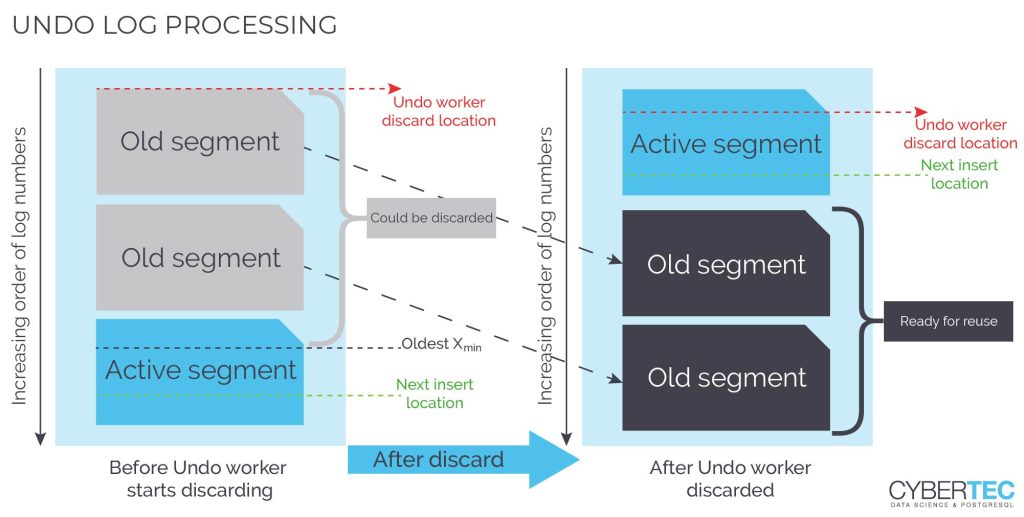

As you can see the process is quite sophisticated.
To ensure that zheap is a drop-in replacement for the current heap it is important to keep the indexing code untouched. Zheap can work with PostgreSQL’s standard access methods. There is of course room to make things even more efficient. However, at this point no changes to the indexing code are needed. This also implies that all index types available in PostgreSQL are fully available without known restrictions.
Currently zheap is still under development and we are glad for the contributions made by Heroic Labs to develop this technology further. So far we have already implemented logical decoding for zheap and added support for PostgreSQL. We will continue to allocate more resources to push the tool to make it production-ready.
If you want to read more about PostgreSQL and VACUUM right now consider checking our previous posts on the subject. In addition, we also want to invite you to keep visiting our blog on a regular basis to learn more about it and other interesting technologies.
+43 (0) 2622 93022-0
office@cybertec.at
You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from X. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information