After testing shared_buffers recently, I decided to do a little more testing on our new office desktop PC (8 core AMD CPU, 4 GHZ, 8 GB RAM and a nice 128 GB Samsung 840 SSD). All tests were conducted on the SSD drive.
This time I tested the impact of maintenance_work_mem on indexing speed. To get started I created half a billion rows using the following simple code snippet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
BEGIN; DROP SEQUENCE IF EXISTS seq_a; CREATE SEQUENCE seq_a CACHE 10000000; CREATE TABLE t_test ( id int4 DEFAULT nextval('seq_a'), name text ); INSERT INTO t_test (name) VALUES ('hans'); DO $ DECLARE i int4; BEGIN i := 0; WHILE i < 29 LOOP i := i + 1; INSERT INTO t_test (name) SELECT name FROM t_test; END LOOP; END; $ LANGUAGE 'plpgsql'; SELECT count(*) FROM t_test; COMMIT; VACUUM t_test; |
Once the data is loaded we can check the database size. The goal of the data set is to clearly exceed the size of RAM so that we can observe more realistic results.
In our case we got 24 GB of data:
|
1 2 3 4 5 |
test=# SELECT pg_size_pretty(pg_database_size('test')); pg_size_pretty ---------------- 24 GB (1 row) |
The number of rows is: 536870912
The point is that our data set has an important property: We have indexed the integer column. This implies that the input is already sorted.
Each index is built like that:
|
1 2 3 4 5 |
DROP INDEX idx_id; CHECKPOINT; SET maintenance_work_mem TO '32 MB'; CREATE INDEX idx_id ON t_test (id); |
We only measure the time of indexing. A checkpoint is requested before we start building the index to make sure that stuff is forced to disk before, and no unexpected I/O load can happen while indexing.
The results are as follows:
1 MB: 516 sec
32 MB: 605 sec
128 MB: 641 sec
512 MB: 671 sec
1 GB: 688 sec
2 GB: 704 sec
4 GB: 709 sec
The interesting part here is that we can see the top performing index creating with very little memory. This is not totally expected but it makes sense given the way things work. We see a steady decline, given more memory.
Let us repeat the test using unsorted data now.
We create ourselves a new table containing completely random order of the same data:
|
1 2 |
test=# CREATE TABLE t_random AS SELECT * FROM t_test ORDER BY random(); SELECT 536870912 |
Let us run those index creations again:
1 MB: 1810 sec
32 MB: 1176 sec
128 MB: 1130 sec
512 MB: 1244 sec
1 GB: 1315 sec
2 GB: 1385 sec
4 GB: 1411 sec
As somewhat expected, the time needed to create indexes has risen. But: In this case we cannot see the best performer on the lower or the upper edge of the spectrum but somewhere in the middle at 128 MB of RAM. Once the system gets more memory than that, we see a decline, which is actually quite significant, again.
From my point of view this is a clear statement that being too generous is clearly not the best strategy.
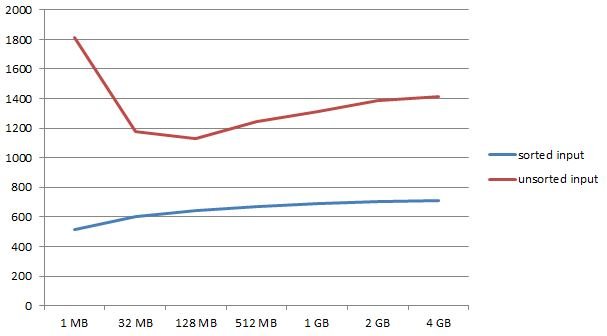
Of course, results will be different on different hardware and things depend on the nature of data as well as on the type of index (Gist and GIN would behave differently) in use. However, for btrees the picture seems clear.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
A lot has been said about PostgreSQL shared buffers and performance. As my new desktop box has arrived this week I decided to give it a try and see, how a simple benchmark performs, given various settings of shared_buffers.
The first thing to run the test is to come up with a simple test database. I decided to use a pgbench with a scale factor of 100. This gives a total of 10 mio rows and a database size of roughly 1.5 GB:
|
1 2 3 4 5 |
test=# select pg_size_pretty(pg_database_size('test')); pg_size_pretty ---------------- 1502 MB (1 row) |
The test box we are running on is an AMD FX-8350 (8 cores) with 16 GB of RAM and a 256 GB Samsung 840 SSD.
A simple shell script is used to conduct the test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/bin/sh PGDATA=/home/hs/db CONNS=32 T=1200 DB=test for x in 1024 4096 16384 65536 131072 262144 524288 1048576 do pg_ctl -D $PGDATA -o "-B $x" -l /dev/null start > /dev/null sleep 2 echo trying with: $x buffers pgbench -j 16 -M simple -S -T $T $DB -c $CONNS 2> /dev/null | grep tps | grep includ pgbench -j 16 -M prepared -S -T $T $DB -c $CONNS 2> /dev/null | grep tps | grep includ pg_ctl -D $PGDATA -o "$x" -m fast -l /dev/null stop > /dev/null echo done |
The goal of the test is to see if the amount of shared memory does have an impact on the performance of the system.
NOTE: In our test the benchmarking program is running on the same node sucking up around 1.5 CPU cores. So, the tests we have here can basically just use up the remaining 6.5 cores. While this does not give performance data, it is still enough to see, which impact changing the size of the shared buffers have.
Here are the results. Buffers are in 8 blocks:
| Buffers | TPS simple | TPS prepared |
| 1024 | 80529,33 | 120403,43 |
| 4096 | 80496,44 | 119709,02 |
| 16384 | 82487,12 | 124697,52 |
| 65536 | 87791,88 | 139695,82 |
| 131072 | 92086,75 | 150641,91 |
| 262144 | 94760,85 | 155698,34 |
| 524288 | 94708,02 | 155766,49 |
| 1048576 | 94676,83 | 156040,41 |
What we see is a steady increase of the database throughput roughly up to the size of the database itself. Then the curve is flattening out as expected:
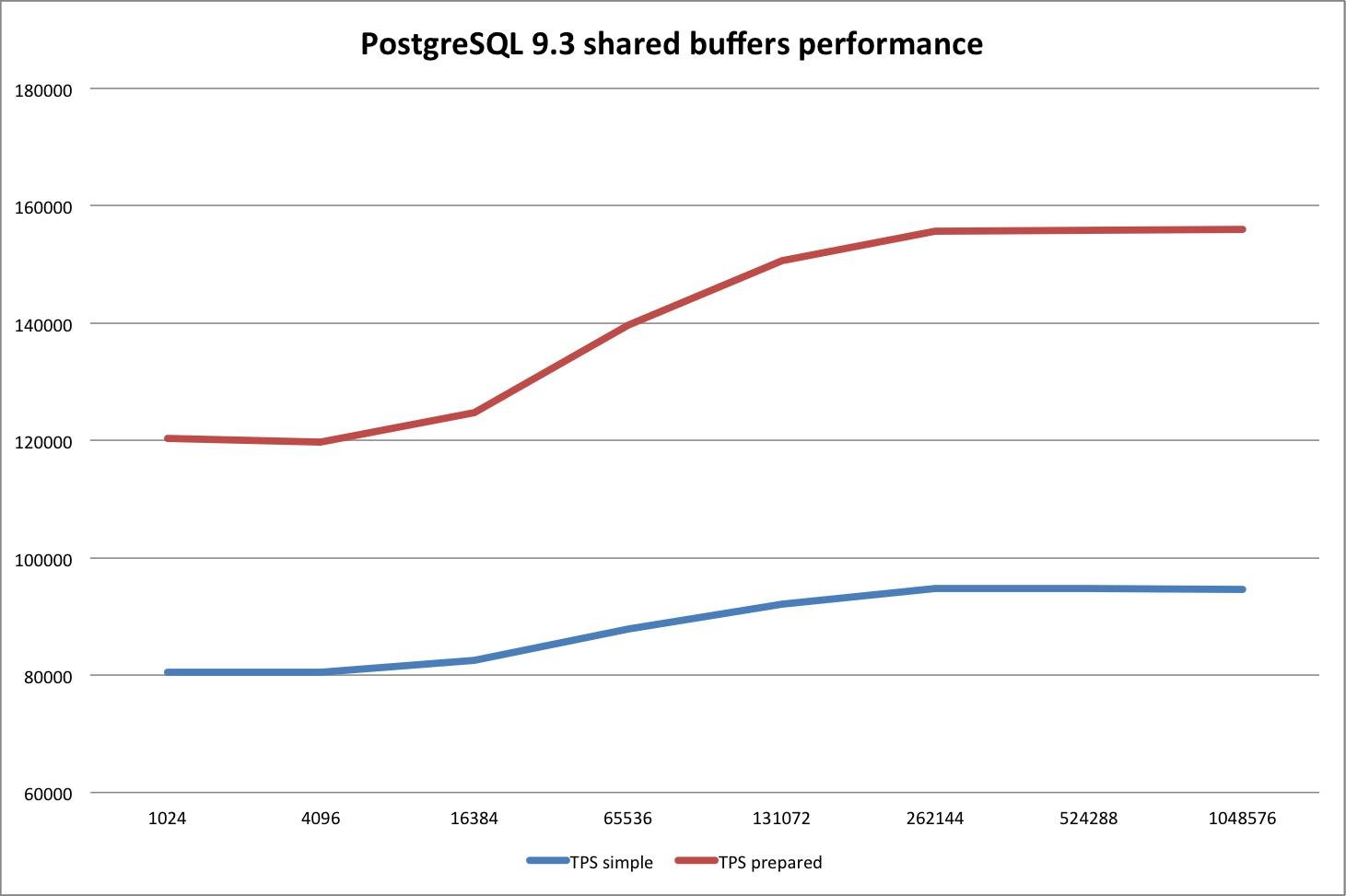
It is interesting to see that the impact of not having to ask the operating system for each and every block is actually quite significant.
The same can be said about prepared queries. Avoiding parsing does have a serious impact on performance - especially on short reading transactions. Close to 160k reads to find data in 10 mio rows is actually quite a lot given the fact that we are talking about hardware, which is ways around 1.000 euros including VAT.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.