When people are talking about database performance monitoring, they usually think of inspecting one PostgreSQL database server at a time. While this is certainly useful, it can also be quite beneficial to inspect the status of an entire database cluster or to inspect a set of servers working together at once. Fortunately, there are easy means to achieve that with PostgreSQL. How this works can be outlined in this post.
If you want to take a deep look at PostgreSQL performance, there is really no way around pg_stat_statements. It offers a lot of information and is really easy to use.
To install pg_stat_statements, the following steps are necessary:
Once this is done, PostgreSQL will already be busy collecting data on your database hosts. However, how can we create a “clusterwide pg_stat_statements” view so that we can inspect an entire set of servers at once?
Our goal is to show data from a list of servers in a single view. One way to do that is to make use of PostgreSQL’s foreign data wrapper infrastructure. We can simply connect to all servers in the cluster and unify the data in a single view.
Let us assume we have 3 servers, a local machine, “a_server”, and “b_server”. Let us get started by connecting to the local server to run the following commands:
|
1 2 3 |
CREATE USER dbmonitoring LOGIN PASSWORD 'abcd' SUPERUSER; GRANT USAGE ON SCHEMA pg_catalog TO dbmonitoring; GRANT ALL ON pg_stat_statements TO dbmonitoring; |
In the first step I created a simple user to do the database monitoring. Of course you can handle users and so on differently, but it seems like an attractive idea to use a special user for that purpose.
The next command enables the postgres_fdw extension, which is necessary to connect to those remote servers we want to access:
|
1 |
CREATE EXTENSION postgres_fdw; |
Then we can already create “foreign servers”.
|
1 2 3 4 |
CREATE SERVER pg1 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'a_server', dbname 'a'); CREATE SERVER pg2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'b_server', dbname 'b'); |
Just replace the hostnames and the database names with your data and run those commands. The next step is already about user mapping: It might easily happen that local users are not present on the other side, so it is necessary to create some sort of mapping between local and remote users:
|
1 2 3 4 5 6 7 |
CREATE USER MAPPING FOR public SERVER pg1 OPTIONS (user 'postgres', password 'abcd'); CREATE USER MAPPING FOR public SERVER pg2 OPTIONS (user 'postgres', password 'abcd'); |
In this case we will login as user “postgres”. Now that two servers and the user mappings are ready, we can import the remote schema into a local schema:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE SCHEMA monitoring_a; IMPORT FOREIGN SCHEMA public LIMIT TO (pg_stat_statements) FROM SERVER pg1 INTO monitoring_a; CREATE SCHEMA monitoring_b; IMPORT FOREIGN SCHEMA public LIMIT TO (pg_stat_statements) FROM SERVER pg2 INTO monitoring_b; |
For each schema there will be a separate schema. This makes it very easy to drop things again and to handle various incarnations of the same data structure.
The last thing to do in our main database, is to connect those remote tables with our local data. The easiest way to achieve that is to use a simple view:
|
1 2 3 4 5 6 7 8 9 |
CREATE VIEW monitoring_performance AS SELECT 'localhost'::text AS node, * FROM pg_stat_statements UNION ALL SELECT 'server a'::text AS node, * FROM monitoring_a.pg_stat_statements UNION ALL SELECT 'server b'::text AS node, * FROM monitoring_b.pg_stat_statements; |
The view will simply unify all the data and add an additional column at the beginning.
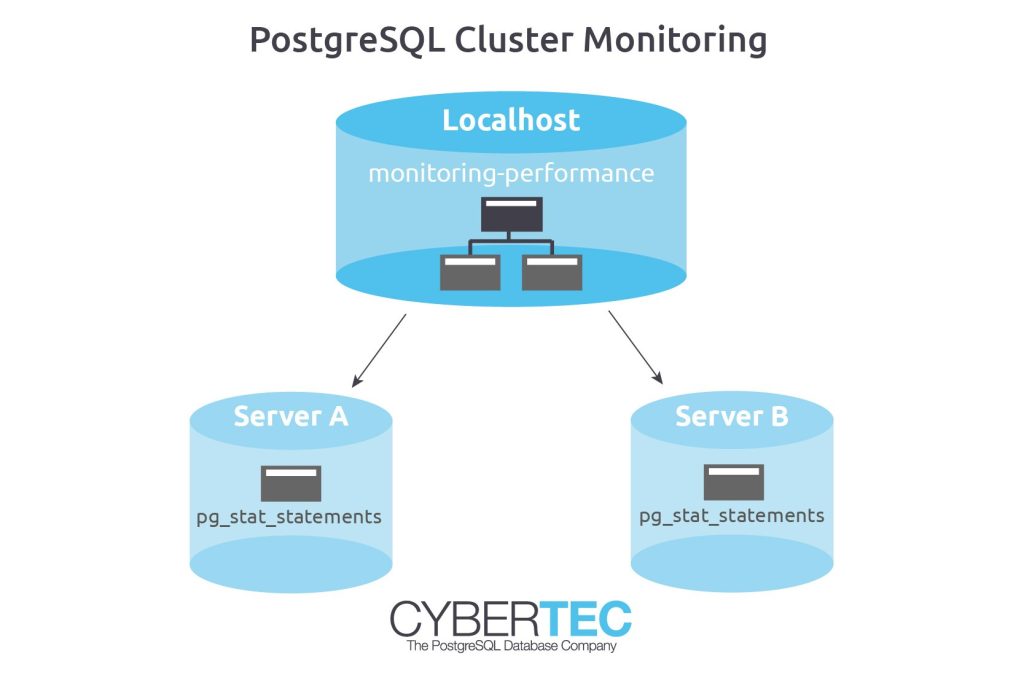
Our system is now ready to use, and we can already start to run useful analysis:
|
1 2 3 4 5 6 7 8 |
SELECT *, sum(total_time) OVER () AS cluster_total_time, sum(total_time) OVER (PARTITION BY node) AS node_total_time, round((100 * total_time / sum(total_time) OVER ())::numeric, 4) AS percentage_total, round((100 * total_time / sum(total_time) OVER (PARTITION BY node))::numeric, 4) AS percentage_node FROM monitoring_performance LIMIT 10; |
The query will return all the raw data and add some percentage numbers on top of this data.
If you are interested in further information on pg_state_statements consider reading the following blog post too: /en/pg_stat_statements-the-way-i-like-it/
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.

We all know that you have to pay a price for a new index you create — data modifying operations will become slower, and indexes use disk space. That's why you try to have no more indexes than you actually need.
But most people think that SELECT performance will never suffer from a new index. The worst that can happen is that the new index is not used.
However, this is not always true, as I have seen more than once in the field. I'll show you such a case and tell you what you can do about it.
We will experiment with this table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE skewed ( sort integer NOT NULL, category integer NOT NULL, interesting boolean NOT NULL ); INSERT INTO skewed SELECT i, i%1000, i>50000 FROM generate_series(1, 1000000) i; CREATE INDEX skewed_category_idx ON skewed (category); VACUUM (ANALYZE) skewed; |
We want to find the first twenty interesting rows in category 42:
|
1 2 3 4 5 |
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM skewed WHERE interesting AND category = 42 ORDER BY sort LIMIT 20; |
This performs fine:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
QUERY PLAN -------------------------------------------------------------------- Limit (cost=2528.75..2528.80 rows=20 width=9) (actual time=4.548..4.558 rows=20 loops=1) Buffers: shared hit=1000 read=6 -> Sort (cost=2528.75..2531.05 rows=919 width=9) (actual time=4.545..4.549 rows=20 loops=1) Sort Key: sort Sort Method: top-N heapsort Memory: 25kB Buffers: shared hit=1000 read=6 -> Bitmap Heap Scan on skewed (cost=19.91..2504.30 rows=919 width=9) (actual time=0.685..4.108 rows=950 loops=1) Recheck Cond: (category = 42) Filter: interesting Rows Removed by Filter: 50 Heap Blocks: exact=1000 Buffers: shared hit=1000 read=6 -> Bitmap Index Scan on skewed_category_idx (cost=0.00..19.68 rows=967 width=0) (actual time=0.368..0.368 rows=1000 loops=1) Index Cond: (category = 42) Buffers: shared read=6 Planning time: 0.371 ms Execution time: 4.625 ms |
PostgreSQL uses the index to find the 1000 rows with category 42, filters out the ones that are not interesting, sorts them and returns the top 20. 5 milliseconds is fine.
Now we add an index that can help us with sorting. That is definitely interesting if we often have to find the top 20 results:
|
1 |
CREATE INDEX skewed_sort_idx ON skewed (sort); |
And suddenly, things are looking worse:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
QUERY PLAN ------------------------------------------------------------- Limit (cost=0.42..736.34 rows=20 width=9) (actual time=21.658..28.568 rows=20 loops=1) Buffers: shared hit=374 read=191 -> Index Scan using skewed_sort_idx on skewed (cost=0.42..33889.43 rows=921 width=9) (actual time=21.655..28.555 rows=20 loops=1) Filter: (interesting AND (category = 42)) Rows Removed by Filter: 69022 Buffers: shared hit=374 read=191 Planning time: 0.507 ms Execution time: 28.632 ms |
PostgreSQL thinks that it will be faster if it examines the rows in sort order using the index until it has found 20 matches. But it doesn't know how the matching rows are distributed with respect to the sort order, so it is not aware that it will have to scan 69042 rows until it has found its 20 matches (see Rows Removed by Filter: 69022 in the above execution plan).
PostgreSQL v10 has added extended statistics to track how the values in different columns are correlated, but that does not track the distributions of the values, so it will not help us here.
There are two workarounds:
OFFSET 0:
|
1 2 3 4 5 6 |
SELECT * FROM (SELECT * FROM skewed WHERE interesting AND category = 42 OFFSET 0) q ORDER BY sort LIMIT 20; |
This makes use of the fact that OFFSET and LIMIT prevent a subquery from being “flattened”, even if they have no effect on the query result.
|
1 2 3 4 |
SELECT * FROM skewed WHERE interesting AND category = 42 ORDER BY sort + 0 LIMIT 20; |
This makes use of the fact that PostgreSQL cannot deduce that sort + 0 is the same as sort. Remember that PostgreSQL is extensible, and you can define your own + operator!
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
By Kaarel Moppel - In my last post I described what to expect from simple PL/pgSQL triggers in performance degradation sense, when doing some inspection/changing on the incoming row data. The conclusion for the most common “audit fields” type of use case was that we should not worry about it too much and just create those triggers. But in which use cases would it make sense to start worrying a bit?
So, to get more insights I conjured up some more complex trigger use cases and again measured transaction latencies on them for an extended period of time. Please read on for some extra info on the performed tests or just jump to the concluding results table at end of article.
This was the initial test that I ran for the original blog post - default pgbench transactions, with schema slightly modified to include 2 auditing columns for all tables being updated, doing 3 updates, 1 select, 1 insert (see here to see how the default transaction looks like) vs PL/PgSQL audit triggers on all 3 tables getting updates. The triggers will just set the last modification timestamp to current time and username to current user, if not already specified in the incoming row.
Results: 1.173ms vs 1.178ms i.e. <1% penalty for the version with triggers.
With multi statement transactions a lot of time is actually spent on communication over the network. To get rid of that the next test consisted of just a single update on the pgbench_accounts table (again 2 audit columns added to the schema). And then again the same with an PL/pgSQL auditing trigger enabled that sets the modification timestamp and username if left empty.
Results: 0.390ms vs 0.405ms ~ 4% penalty for the trigger version. Already a bit visible, but still quite dismissible I believe.
|
1 2 3 4 |
/* script file used for pgbench */ set aid random(1, 100000 * :scale) set delta random(-5000, 5000) UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid; |
But what it the above 4% performance degradation is not acceptable and it sums up if we are actually touching a dozen of tables (ca 60% hit)? Can we somehow shave off some microseconds?
Well one could try to write triggers in the Postgres native language of “C”! As well with optimizing normal functions it should help with triggers. But hughh, “C” you think...sounds daunting? Well...sure, it’s not going to be all fun and play, but there a quite a lot of examples actually included in the Postgres source code to get going, see here for example.
So after some tinkering around (I'm more of a Python / Go guy) I arrived at these numbers: 0.405ms for PL/pgSQL trigger vs 0.401ms for the “C” version meaning only ~ +1% speedup! So in short – absolutely not worth the time for such simple trigger functionality. But why so little speedup against an interpreted PL language you might wonder? Yes, PL/pgSQL is kind of an interpreted language, but with a good property that execution plans and resulting prepared statements actually stay cached within one session. So if we’d use pgbench in "re-connect" mode I’m pretty sure we’d see some very different numbers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
... // audit field #1 - last_modified_on attnum = SPI_fnumber(tupdesc, 'last_modified_on'); if (attnum <= 0) ereport(ERROR, (errcode(ERRCODE_TRIGGERED_ACTION_EXCEPTION), errmsg('relation '%d' has no attribute '%s'', rel->rd_id, 'last_modified_on'))); valbuf = (char*)SPI_getvalue(rettuple, tupdesc, attnum); if (valbuf == NULL) { newval = GetCurrentTimestamp(); rettuple = heap_modify_tuple_by_cols(rettuple, tupdesc, 1, &attnum, &newval, &newnull); } ... |
See here for my full “C” code.
Here things get a bit incomparable actually as we’re adding some new data, which is not there in the “un-triggered” version. So basically I was doing from the trigger the same as the insert portion (into pgbench_history) from the default pgbench transaction. Important to note though - although were seeing some slowdown...it’s most probably still faster that doing that insert from the user transaction as we can space couple of network bytes + the parsing (in our default pgbench case statements are always re-parsed from text vs pl/pgsql code that are parsed only once (think “prepared statements”). By the way, to test how pgbench works with prepared statements (used mostly to test max IO throughput) set the “protocol” parameter to “prepared“.
Results - 0.390ms vs 0.436ms ~ 12%. Not too bad at all given we double the amount of data!
Here we basically double the amount of data written – all updated tables get a logging entry (including pgbench_accounts, which actually gets an insert already as part on normal transaction). Results - 1.173 vs 1.285 ~ 10%. Very tolerable penalties again – almost doubling the dataset here and only paying a fraction of the price! This again shows that actually the communication latency and transaction mechanics together with the costly but essential fsync during commit have more influence than a bit of extra data itself (given we don’t have tons of indexes on the data of course). For reference - full test script can be found here if you want to try it out yourself.
| Use Case | Latencies (ms) | Penalty per TX (%) |
|---|---|---|
| Pgbench default vs with audit triggers for all 3 updated tables | 1.173 vs 1.178 | 0.4% |
| Single table update (pgbench_accounts) vs with 1 audit trigger | 0.390 vs 0.405 | 3.9% |
| Single table update (pgbench_accounts) vs with 1 audit trigger written in “C” | 0.390 vs 0.401 | 2.8% |
| Single table update vs with 1 “insert logging” trigger | 0.390 vs 0.436 | 11.8% |
| Pgbench default vs with 3 “insert logging” triggers on updated tables | 1.173 vs 1.285 | 9.6% |
Did you know that in Postgres one can also write DDL triggers so that you can capture/reject/log structural changes for all kinds of database objects? Most prominent use case might be checking for full table re-writes during business hours.