UPDATED August 2023: Functions defined as SECURITY DEFINER are a powerful, but dangerous tool in PostgreSQL.
The documentation warns of the dangers:
Because a
SECURITY DEFINERfunction is executed with the privileges of the user that owns it, care is needed to ensure that the function cannot be misused. For security,search_pathshould be set to exclude any schemas writable by untrusted users. This prevents malicious users from creating objects (e.g., tables, functions, and operators) that mask objects intended to be used by the function.
This article describes such an attack, in the hope to alert people that this is no idle warning.
SECURITY DEFINER good for?By default, PostgreSQL functions are defined as SECURITY INVOKER. That means that they are executed with the User ID and security context of the user that calls them. SQL statements executed by such a function run with the same permissions as if the user had executed them directly.
A SECURITY DEFINER function will run with the User ID and security context of the function owner.
This can be used to allow a low privileged user to execute an operation that requires high privileges in a controlled fashion: you define a SECURITY DEFINER function owned by a privileged user that executes the operation. The function restricts the operation in the desired way.
For example, you can allow a user to use COPY TO, but only to a certain directory. The function has to be owned by a superuser (or, from v11 on, by a user with the pg_write_server_files role).
Of course, such functions have to be written very carefully to avoid software errors that could be abused.
But even if the code is well-written, there is a danger: unqualified access to database objects from the function (that is, accessing objects without explicitly specifying the schema) can affect other objects than the author of the function intended. This is because the configuration parameter search_path can be modified in a database session. This parameter governs which schemas are searched to locate the database object.
The documentation has an example where search_path is used to have a password checking function inadvertently check a temporary table for passwords.
You may think you can avoid the danger by using the schema name in each table access, but that is not good enough.
SECURITY DEFINER functionConsider this seemingly harmless example of a SECURITY DEFINER function that does not control search_path properly:
|
1 2 3 |
CREATE FUNCTION public.harmless(integer) RETURNS integer LANGUAGE sql SECURITY DEFINER AS 'SELECT $1 + 1'; |
Let's assume that this function is owned by a superuser.
Now this looks pretty safe at first glance: no table or view is used, so nothing can happen, right? Wrong!
The attack depends on two things:
public) where the attacker can create objects.The malicious database user “meany” can simply run the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
/* * SQL functions can run several statements, the result of the * last one is the function result. * The 'OPERATOR' syntax is necessary to schema-qualify an operator * (you can't just write '$1 pg_catalog.+ $2'). */ CREATE FUNCTION public.sum(integer, integer) RETURNS integer LANGUAGE sql AS 'ALTER ROLE meany SUPERUSER; SELECT $1 OPERATOR(pg_catalog.+) $2'; CREATE OPERATOR public.+ ( FUNCTION = public.sum, LEFTARG = integer, RIGHTARG = integer ); /* * By default, 'pg_catalog' is added to 'search_path' in front of * the schemas that are specified. * We have to put it somewhere else explicitly to change that. */ SET search_path = public,pg_catalog; SELECT public.harmless(41); harmless ---------- 42 (1 row) du meany List of roles Role name | Attributes | Member of -----------+------------+----------- meany | Superuser | {} |
The function was executed with superuser permissions. search_path was set to find the (unqualified!) “+” operator in schema public rather than in pg_catalog. So, the user-defined function public.sum was executed with superuser privileges and turned the attacker into a superuser.
If the attacker had called the function public.sum himself (or issued the ALTER ROLE statement), it would have caused a “permission denied” error. But since the SELECT statement inside the function ran with superuser permissions, so did the operator function.
In theory you can schema-qualify everything, including operators, inside the function body, but the risk that you forget a harmless “+” or “=” is just too big. Besides, that would make your code hard to read, which is not good for software quality.
Therefore, you should take the following measures:
search_path on a SECURITY DEFINER function. Apart from the schemas that you need in the function, put pg_temp on the list as the last element.CREATE privilege. In particular, remove the default public CREATE privilege from the public schema.EXECUTE privilege on all SECURITY DEFINER functions and grant it only to those users that need it.In SQL:
|
1 2 3 4 5 6 |
ALTER FUNCTION harmless(integer) SET search_path = pg_catalog,pg_temp; REVOKE CREATE ON SCHEMA public FROM PUBLIC; REVOKE EXECUTE ON FUNCTION harmless(integer) FROM PUBLIC; |
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.

PostgreSQL commit 74dfe58a5927b22c744b29534e67bfdd203ac028 has added “support functions”. This exciting new functionality that allows the optimizer some insight into functions. This article will discuss how this will improve query planning for PostgreSQL v12. If you are willing to write C code, you can also use this functionality for your own functions.
Up to now, the PostgreSQL optimizer couldn't really do a lot about functions. No matter how much it knew about the arguments of a function, it didn't have the faintest clue about the function result. This also applied to built-in functions: no information about them was “wired into” the optimizer.
Let's look at a simple example: language="sql"
|
1 2 3 4 5 6 |
EXPLAIN SELECT * FROM unnest(ARRAY[1,2,3]); QUERY PLAN ------------------------------------------------------------- Function Scan on unnest (cost=0.00..1.00 rows=100 width=4) (1 row) |
PostgreSQL knows exactly that the array contains three elements. Still, it has no clue how many rows unnest will return, so it estimates an arbitrary 100 result rows. If this function invocation is part of a bigger SQL statement, the wrong result count can lead to a bad plan. The most common problem is that PostgreSQL will select bad join strategies based on wrong cardinality estimates. If you have ever waited for a nested loop join to finish that got 10000 instead of 10 rows in the outer relation, you know what I'm talking about.
There is the option to specify COST and ROWS on a function to improve the estimates. But you can only specify a constant there, which often is not good enough.
There were many other ways in which optimizer support for functions was lacking. This situation has been improved with support functions.
The CREATE FUNCTION statement has been extended like this:
|
1 2 3 |
CREATE FUNCTION name (...) RETURNS ... SUPPORT supportfunction AS ... |
This way a function gets a “support function” that knows about the function and can help the optimizer produce a better plan. Only a superuser can use the SUPPORT option.
Such a support function must have the signature
|
1 |
supportfunction(internal) RETURNS internal |
“internal” means that the function argument and return code are pointers to some C structure. That means that the function has to be written in C and is not callable from SQL.
When the optimizer considers some optimization for a function call, it invokes the support function. If the support function returns NULL to indicate it cannot help with that request, the optimizer goes ahead and plans as usual.
The optimizer can pass different C structures to the support function, depending on the optimization it considers. See src/include/nodes/supportnodes.h in the PostgreSQL source for details.
A support function can provide some or all of the following features:
This in only called for functions that return boolean and are at the top level of a WHERE or JOIN condition, for example
|
1 |
SELECT ... FROM a JOIN b ON func(a.x, b.y) |
or
|
1 |
SELECT ... FROM a WHERE func(a.x, a.y, a.z) |
Sometimes it may be possible to replace the function call with an identical expression that can use an index scan. A trivial example would be int4eq(x, 42), which could be replaced by x = 42. Usually, though, the indexable expressions will not be able to replace the function call, but it can be useful as a “lossy” filter that significantly reduces the number of function calls that have to be performed.
One well-known example of such a lossy filter are LIKE expressions:
|
1 2 3 4 5 6 7 8 |
EXPLAIN SELECT * FROM person WHERE name LIKE 'alb%t'; QUERY PLAN ------------------------------------------------------------------------------- Index Scan using person_name_idx on person (cost=0.29..8.31 rows=9 width=11) Index Cond: ((name ~>=~ 'alb'::text) AND (name ~<~ 'alc'::text)) Filter: (name ~~ 'alb%t'::text) (3 rows) |
The two (byte-wise) comparisons can use an index scan, and they narrow down the search space. An additional filter removes the false positives.
Up to PostgreSQL v11, the optimizer had this knowledge wired in. From v12 on, the functions that implement the LIKE operator have support functions that contain this knowledge.
However, the main use case for this kind of support function will be PostGIS, and support functions were introduced specifically to help PostGIS. Up to now, functions like ST_Intersects() or ST_DWithin() used a trick to get index support: they were defined as SQL functions with a (lossy, but indexable) boundary box operator and an exact function. PostGIS relied on “function inlining” to get PostgreSQL to use an index. This was an ugly hack that caused problems, particularly with parallel queries. With PostgreSQL v12, PostGIS can use support functions to do this correctly.
With a “set-returning function”, PostgreSQL calls the support function to get an estimate for the number of rows. This has been implemented for unnest in v12, so the example from the beginning will get the correct estimate:
|
1 2 3 4 5 6 |
EXPLAIN SELECT * FROM unnest(ARRAY[1,2,3]); QUERY PLAN ----------------------------------------------------------- Function Scan on unnest (cost=0.00..0.03 rows=3 width=4) (1 row) |
This provides a smarter alternative to the ROWS clause of CREATE FUNCTION.
Similar to the above, a support function can also provide a smarter alternative to the COST clause of CREATE FUNCTION.
There is no example of such a function if the PostgreSQL v12 code base, except in the regression tests, but maybe there will be more in future releases.
WHERE conditionAs we saw before, a function that returns a boolean can appear at the top level of a WHERE condition. An example would be
|
1 |
SELECT ... FROM a WHERE starts_with(a.x, 'alb') |
Up to now, PostgreSQL had no idea how selective this condition is, so it simply estimated that it would filter out two thirds of the rows.
With PostgreSQL v12, you can define a support function that provides a better estimate for the selectivity of such a condition. Again, so far the only example for such a function is in the PostgreSQL regression tests.
This kind of support function is called when the optimizer simplifies constant expressions, so it could be used to replace a function call with a simpler expression if one or more of its arguments are constants.
For example, an expression like x + 0 (which internally calls the function int4pl) could be replaced with x.
PostgreSQL already had such a feature (called transform functions), but that was not exposed at the SQL level. The place where this was used in the code (simplification of some type casts) has been changed to use a support function in v12.
Support functions open the field for much better optimizer support for functions. I imagine that they will prove useful for PostgreSQL's built-in functions, as well as for third-party extensions.
There is a lot of low hanging fruit which might be harvested by beginners who want to get involved with PostgreSQL hacking:
generate_series functions, generate_subscripts, jsonb_populate_recordset and other JSON functionsstarts_with could be supported by indexes, and the selectivity estimates could be improved, quite similar to LIKEPostgreSQL offers powerful means to create users/ roles and enables administrators to implement everything from simple to really complex security concepts. However, if the PostgreSQL security machinery is not used wisely, things might become a bit rough.
This fairly short post will try to shed some light on this topic.
The most important thing you must remember is the following: You cannot drop a user unless there are no more permissions, objects, policies, tablespaces, etc. are assigned to it. Here's an example how to create users:
|
1 2 3 4 5 6 |
test=# CREATE TABLE a (aid int); CREATE TABLE test=# CREATE USER joe; CREATE ROLE test=# GRANT SELECT ON a TO joe; GRANT |
As you can see “joe” has a single permission and there is no way to kill the user without revoking the permission first:
|
1 2 3 |
test=# DROP USER joe; ERROR: role 'joe' cannot be dropped because some objects depend on it DETAIL: privileges for table a |
Note that there is no such thing as “DROP USER … CASCADE” - it does not exist. The reason for that is that users are created at the instance level. A user can therefore have rights in potentially dozens of PostgreSQL databases. If you drop a user you cannot just blindly remove objects from other databases. It is therefore necessary to revoke all permissions first before a user can be removed. That can be a real issue if your deployments grow in size.
One thing we have seen over the years is: Tasks tend to exist longer than staff. Even after hiring and firing cleaning staff for your office 5 times the task is still the same: Somebody is going to clean your office twice a week. It can therefore make sense to abstract the tasks performed by “cleaning_staff” in a role, which is then assigned to individual people.
|
1 2 3 4 5 6 |
test=# CREATE ROLE cleaning_staff NOLOGIN; CREATE ROLE test=# GRANT SELECT ON a TO cleaning_staff; GRANT test=# GRANT cleaning_staff TO joe; GRANT ROLE |
First we create a role called “cleaning_staff” and assign whatever permissions to that role. In the next step the role is assigned to “joe” to make sure that joe has all the permissions a typical cleaning person usually has. If only roles are assigned to real people such as joe, it is a lot easier to remove those people from the system again.
If you want to take a look at how permissions are set on your system, consider checking out pg_permission, which is available for free on our GitHub page: https://github.com/cybertec-postgresql/pg_permission
Just do a …
|
1 |
SELECT * FROM all_permissions; |
… and filter for the desired role. You can then see at a glance which permissions are set at the moment. You can also run UPDATE on this view and PostgreSQL will automatically generate the necessary GRANT / REVOKE commands to adjust the underlying ACLs.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
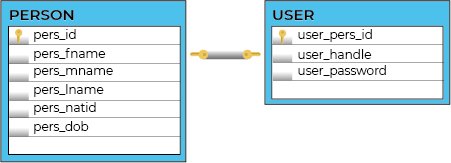
Years ago I wrote this post describing how to implement 1-to-1 relationship in PostgreSQL. The trick was simple and obvious:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE UserProfiles ( UProfileID BIGSERIAL PRIMARY KEY, ... ); CREATE TABLE Users ( UID BIGSERIAL PRIMARY KEY, UProfileID int8 NOT NULL, ... UNIQUE(UProfileID), FOREIGN KEY(UProfileID) REFERENCES Users(UProfileID) ); |
You put a unique constraint on a referenced column and you're fine. But then one of the readers noticed, that this is the 1-to-(0..1) relationship, not a true 1-to-1. And he was absolutely correct.
A lot of time is gone and now we can do this trick much simpler using modern features or PostgreSQL. Let's check:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
BEGIN; CREATE TABLE uProfiles ( uid int8 PRIMARY KEY, payload jsonb NOT NULL ); CREATE TABLE Users ( uid int8 PRIMARY KEY, uname text NOT NULL, FOREIGN KEY (uid) REFERENCES uProfiles (uid) ); ALTER TABLE uProfiles ADD FOREIGN KEY (uid) REFERENCES Users (uid); INSERT INTO Users VALUES (1, 'Pavlo Golub'); INSERT INTO uProfiles VALUES (1, '{}'); COMMIT; |
Things are obvious. We create two tables and reference each other using the same columns in both ways.
Moreover, in such model both our foreign keys are automatically indexed!
Seems legit, but executing this script will produce the error:
|
1 2 3 |
SQL Error [23503]: ERROR: insert or update on table "users" violates foreign key constraint "users_uid_fkey" Detail: Key (uid)=(1) is not present in table "uprofiles". |
Oops. And that was the pitfall preventing the easy solutions years ago during my first post.
UPD: Andrew commented that DEFERRABLE was in PostgreSQL for ages. My bad. I got it mixed up. Thanks for pointing this out!
But now we have DEFERRABLE constraints:
This controls whether the constraint can be deferred. A constraint that is not deferrable will be checked immediately after every command. Checking of constraints that are deferrable can be postponed until the end of the transaction (using the SET CONSTRAINTS command). NOT DEFERRABLE is the default. Currently, only UNIQUE, PRIMARY KEY, EXCLUDE, and REFERENCES (foreign key) constraints accept this clause. NOT NULL and CHECK constraints are not deferrable. Note that deferrable constraints cannot be used as conflict arbitrators in an INSERT statement that includes an ON CONFLICT DO UPDATE clause.
So, the trick is we do not check data consistency till the end of the transaction. Let's try!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
BEGIN; CREATE TABLE uProfiles ( uid int8 NOT NULL PRIMARY KEY, payload jsonb NOT NULL ); CREATE TABLE Users ( uid int8 NOT NULL PRIMARY KEY, uname text NOT NULL ); ALTER TABLE Users ADD FOREIGN KEY (uid) REFERENCES uProfiles (uid) DEFERRABLE INITIALLY DEFERRED; ALTER TABLE uProfiles ADD FOREIGN KEY (uid) REFERENCES Users (uid) DEFERRABLE INITIALLY DEFERRED; INSERT INTO Users VALUES (1, 'Pavlo Golub'); INSERT INTO uProfiles VALUES (1, '{}'); COMMIT; |
Neat! Works like a charm!
|
1 |
SELECT * FROM Users, uProfiles; |
|
1 2 3 |
uid|uname |uid|payload| ---|-----------|---|-------| 1|Pavlo Golub| 1|{} | |
I am still eager to see the real-life situation where such a 1-to-1 model is necessary. From my perspective, this method may help in splitting wide tables into several narrow, where some columns are heavily read. If you have any other thoughts on your mind, shoot them up!
May ACID be with you!