Last time we imported OpenStreetMap datasets from Iceland to PostGIS. To quickly visualize our OSM data results, we will now use QGIS to render our datasets and generate some nice maps on the client.
Let’s start with our prerequisites:
QGIS supports PostgreSQL/PostGIS out of the box.
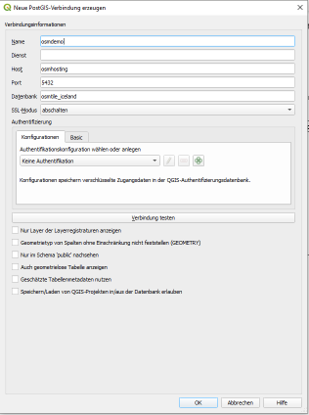
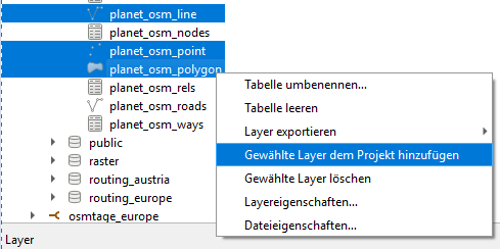
We can import our datasets by defining our database connection (1), showing up the db catalog (2) and adding datasets of interest (3) to our workspace.
| Step 1 | Step 2 | Step 3 |
 |  |  |
QGIS will automatically apply basic styles for the given geometry types and will start loading features of the current viewport and extent. Herby the tool will use information from PostGIS’s geometry_column view to extract geometry column, geometry type, spatial reference identifier and number of dimensions. To check what PostGIS is offering to QGIS, let’s query this view:
|
1 2 3 |
select f_table_name as tblname, f_geometry_column as geocol, coord_dimension as geodim, srid, type from geometry_columns where f_table_schema = 'osmtile_iceland'; |
This brings up the following results:
| tblname | geocol | geodim | srid | type |
| planet_osm_point | way | 2 | 3857 | POINT |
| planet_osm_line | way | 2 | 3857 | LINESTRING |
| planet_osm_polygon | way | 2 | 3857 | GEOMETRY |
| planet_osm_roads | way | 2 | 3857 | LINESTRING |
For type geometry, QGIS uses geometrytype to finally assess geometry’s type modifier.
select distinct geometrytype(way) from planet_osm_polygon;
As mentioned before, QGIS applies default styles to our datasets after being added to the QGIS workspace. Figure 1 gives a first impression on how points and lines from OpenStreetMap are visualized this way.
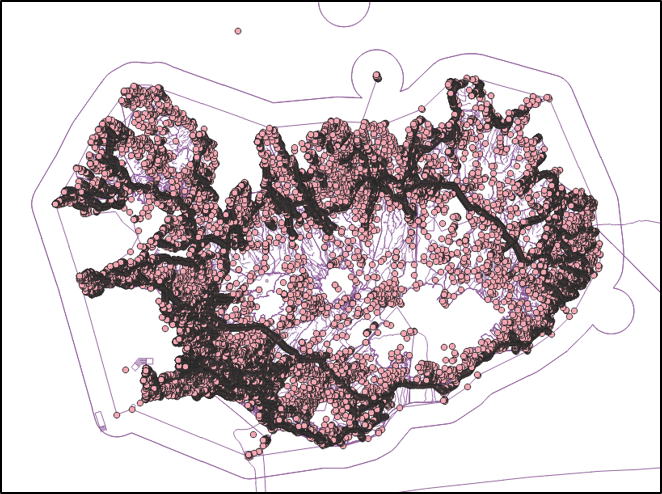
It’s now up to the user the define further styling rules to turn this basic map into a readable and performant map.
As a quick reminder - we imported our osm dump utilizing osm2pgsql with a default-style and no transformations into PostGIS. This resulted in three major tables for points, lines and polygons. It’s now up to the map designer to filter out relevant objects, such as amenities represented as points within the GIS client, to apply appropriate styling rules. Alternatively, it’s a good practice to the parametrize osm2pgsql during import or set up further views to normalize the database model.
Back to our styling task - how can we turn this useless map into something useable?
Please find below some basic rules to start with:
Let me present this approach on amenities and pick some representative amenity types.
|
1 |
select amenity, count(amenity) as amenityCount from planet_osm_point group by amenity order by amenityCount desc; |
| amenity | count |
| waste_basket | 1346 |
| bench | 1285 |
| parking | 479 |
| … |
To style osm_points and apply individual styles for waste_basket, bench and parking we open up the layer properties, click on symbology and finally select rule-based styling as demonstrated in the pictures below.
For each amenity type then, we set up an individual rule by
| Step 1 | Step 2 | Step 3 |
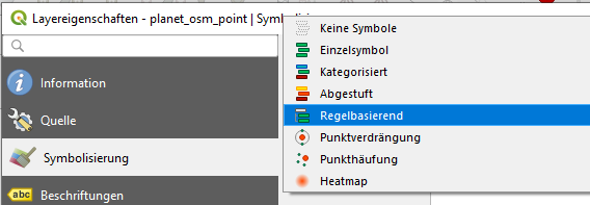 | 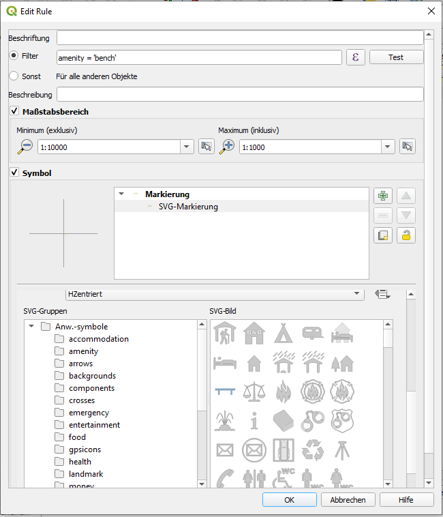 | 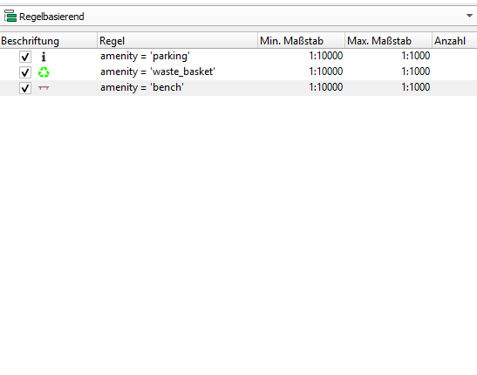 |
After zooming in, your map shows your styled amenities like below.
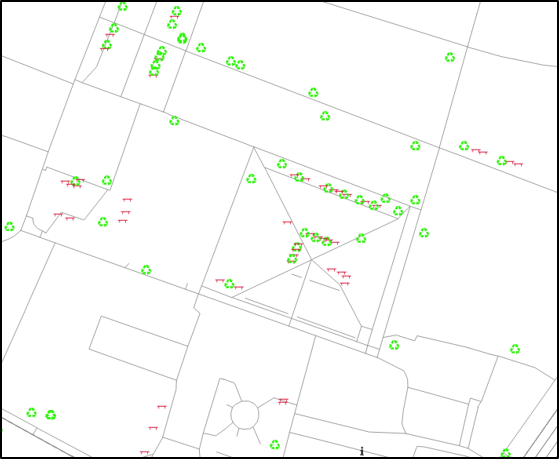
Well, better but not really appealing you might think, and you are absolutely right.
Luckily, we don’t have to start from scratch, and we can apply given styles to achieve better results.
But wait – we are not done. Let’s see what QGIS is requesting from the database to understand how actions in the map are converted to SQL statements. To do that, let’s enable LogCollector in postgres.conf and monitor the log file to grab the current sql statements. Subsequently this enables us to execute the query with explain analyse in the console to start with possible optimizations.
|
1 2 3 4 5 6 |
EXPLAIN analyse SELECT st_asbinary("way", 'NDR'), ctid, "amenity"::text FROM "osmtile_iceland"."planet_osm_point" WHERE ("way" && st_makeenvelope(-2393586.56126631051301956, 9304920.7589644268155098, -2320619.86041467078030109, 9356509.49658409506082535, 3857)) AND (((("amenity" = 'parking') OR ("amenity" = 'waste_basket')) OR ("amenity" = 'wrench'))) |
The resulting explain plan draws attention to a possibly useful, but missing index on column amenity, which has not been created by default by osm2pgsql. Additionally, the explain plain highlights the utilization of planet_osm_point_way_idx, an index on geometry column way, which is being used to quickly identify features, whose bounding boxes intersect with our map extent.
|
1 2 3 4 5 6 7 8 9 10 11 |
Bitmap Heap Scan on planet_osm_point (cost=136.95..2272.97 rows=47 width=47) (actual time=0.537..1.239 rows=10 loops=1) Recheck Cond: (way && '0103000020110F000001000000050000001093D747F94242C1C46F49186BBF61411093D747F94242C15404E4AF9BD86141641122EE75B441C15404E4AF9BD86141641122EE75B441C1C46F49186BBF61411093D747F94242C1C46F49186BBF6141'::geometry) Filter: ((amenity = 'parking'::text) OR (amenity = 'waste_basket'::text) OR (amenity = 'wrench'::text)) Rows Removed by Filter: 4096 Heap Blocks: exact=74 Buffers: shared hit=115 -> Bitmap Index Scan on planet_osm_point_way_idx (cost=0.00..136.94 rows=3821 width=0) (actual time=0.495..0.495 rows=4106 loops=1) Index Cond: (way && '0103000020110F000001000000050000001093D747F94242C1C46F49186BBF61411093D747F94242C15404E4AF9BD86141641122EE75B441C15404E4AF9BD86141641122EE75B441C1C46F49186BBF61411093D747F94242C1C46F49186BBF6141'::geometry) Buffers: shared hit=41 Planning Time: 0.301 ms Execution Time: 1.276 ms |
At this point it’s worth to mention auto_explain, a PostgreSQL extension which is logging execution plans for slow running queries automatically. As shortcut, checkout Kareel’s post about this great extension.
Let’s import layer settings on our datasets. For this demo I downloaded layer settings from https://github.com/yannos/Beautiful_OSM_in_QGIS, which result in a typical OpenStreetMap rendering view.
For each layer (point, line and polygon), open up the layer properties, go to symbology and load the individual layer settings file.
| Step 1 | Step 2 |
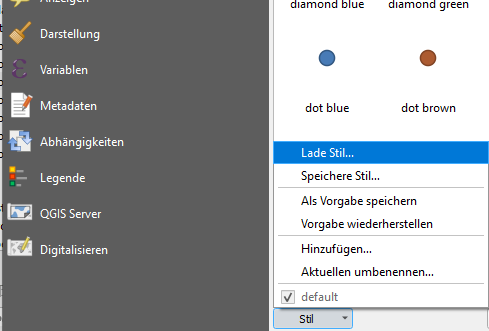 | 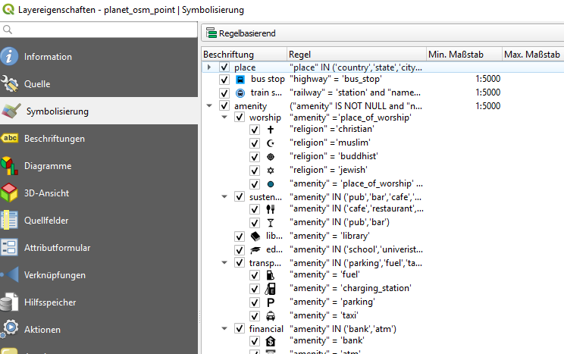 |
Figure 3 shows the resulting map, which serves as good foundation for further adoptions.
It should be stressed that adding styling complexity is not free in terms of computational resources.
Slow loading maps on the client side are mostly caused by missing scale boundaries, expensive expressions leading to complex queries and missing indices on your backend, just to mention some of those traps.
OSM’s common style (https://www.openstreetmap.org) is generally very complex resulting in a resource-intensive rendering.
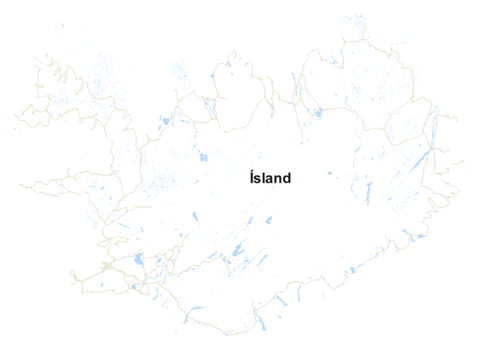 | 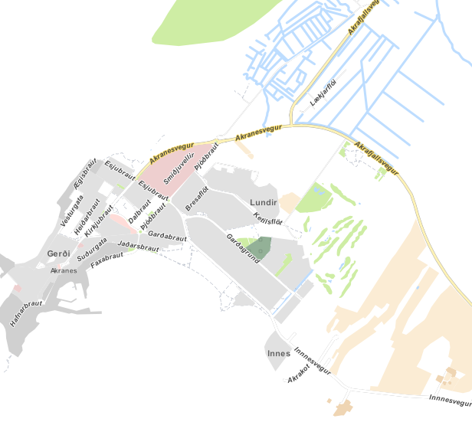 |
Figure 3 Customized QGIS Styling Yannos, https://github.com/yannos/Beautiful_OSM_in_QGIS
This time I briefly discussed how spatial data can be easily added from PostGIS to QGIS to ultimately create a simple visualization. This particular post emphasizes style complexity and finally draws attention to major pitfalls leading to slow rendering processes.
The PostgreSQL caching system has always been a bit of a miracle to many people and many have asked me during consulting or training sessions: How can I figure out what the PostgreSQL I/O cache really contains? What is in shared buffers and how can one figure out? This post will answer this kind of question and we will dive into the PostgreSQL cache.
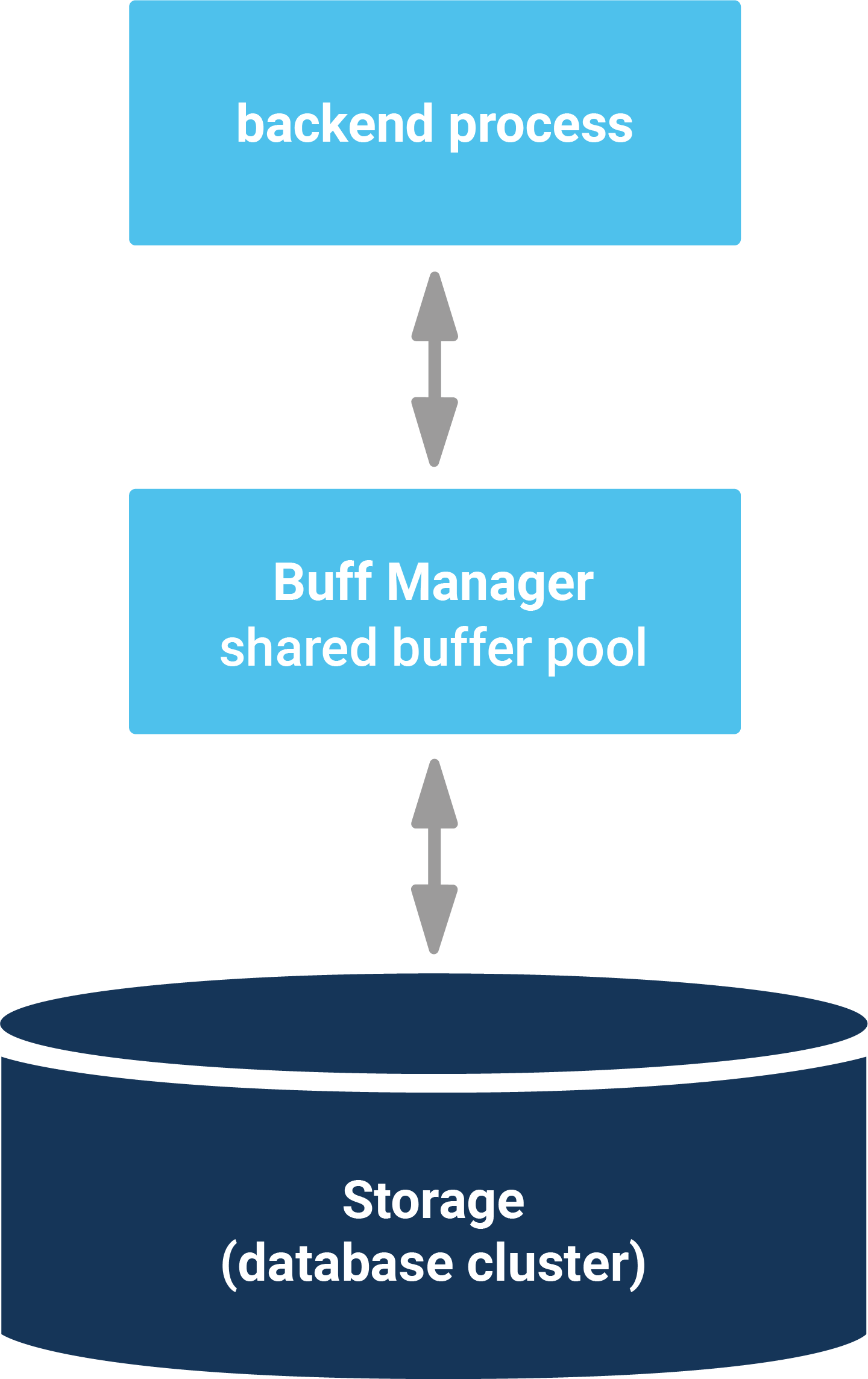
Before we can inspect shared_buffers, we have to create a little database:
|
1 |
hs@hansmacbook ~ % createdb test |
To keep it simple I have created a standard pgbench database containing 1 million rows, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
hs@hansmacbook ~ % pgbench -i -s 10 test dropping old tables... NOTICE: table 'pgbench_accounts' does not exist, skipping NOTICE: table 'pgbench_branches' does not exist, skipping NOTICE: table 'pgbench_history' does not exist, skipping NOTICE: table 'pgbench_tellers' does not exist, skipping creating tables... generating data... 100000 of 1000000 tuples (10%) done (elapsed 0.14 s, remaining 1.25 s) 200000 of 1000000 tuples (20%) done (elapsed 0.27 s, remaining 1.10 s) 300000 of 1000000 tuples (30%) done (elapsed 0.41 s, remaining 0.95 s) 400000 of 1000000 tuples (40%) done (elapsed 0.61 s, remaining 0.91 s) 500000 of 1000000 tuples (50%) done (elapsed 0.79 s, remaining 0.79 s) 600000 of 1000000 tuples (60%) done (elapsed 0.92 s, remaining 0.62 s) 700000 of 1000000 tuples (70%) done (elapsed 1.09 s, remaining 0.47 s) 800000 of 1000000 tuples (80%) done (elapsed 1.23 s, remaining 0.31 s) 900000 of 1000000 tuples (90%) done (elapsed 1.37 s, remaining 0.15 s) 1000000 of 1000000 tuples (100%) done (elapsed 1.49 s, remaining 0.00 s) vacuuming... creating primary keys... done. |
Deploying 1 million rows is pretty fast. In my case it took around 1.5 seconds (on my laptop).
Now that we have some data, we can install the pg_buffercache extension, which is ideal if you want to inspect the content of the PostgreSQL I/O cache:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
test=# CREATE EXTENSION pg_buffercache; CREATE EXTENSION test=# d pg_buffercache View 'public.pg_buffercache' Column | Type | Collation | Nullable | Default -------------------+----------+-----------+----------+--------- bufferid | integer | | | relfilenode | oid | | | reltablespace | oid | | | reldatabase | oid | | | relforknumber | smallint | | | relblocknumber | bigint | | | isdirty | boolean | | | usagecount | smallint | | | pinning_backends | integer | | | |
pg_buffercache will return one row per 8k block in shared_buffers. However, to make sense out of the data one has to understand the meaning of those OIDs in the view. To make it easier for you I have created some simple example.
Let us take a look at the sample data first:
|
1 2 3 4 5 6 7 8 9 10 |
test=# d+ List of relations Schema | Name | Type | Owner | Size | Description --------+------------------+-------+-------+---------+------------- public | pg_buffercache | view | hs | 0 bytes | public | pgbench_accounts | table | hs | 128 MB | public | pgbench_branches | table | hs | 40 kB | public | pgbench_history | table | hs | 0 bytes | public | pgbench_tellers | table | hs | 40 kB | (5 rows) |
My demo database consists of 4 small tables.
Often the question is how much data from which database is currently cached. While this sounds simple you have to keep some details in mind:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT CASE WHEN c.reldatabase IS NULL THEN '' WHEN c.reldatabase = 0 THEN '' ELSE d.datname END AS database, count(*) AS cached_blocks FROM pg_buffercache AS c LEFT JOIN pg_database AS d ON c.reldatabase = d.oid GROUP BY d.datname, c.reldatabase ORDER BY d.datname, c.reldatabase; database | cached_blocks ---------------+--------------- postgres | 67 template1 | 67 test | 526 | 25 | 15699 (5 rows) |
The reldatabase column contains the object ID of the database a block belongs to. However, there is a “special” thing here: 0 does not represent a database but rather the pg_global schema. Some objects in PostgreSQL such as the list of databases, the list of tablespaces or the list of users are not stored in a database – this information is global. Therefore “0” needs some special treatment here. Otherwise, the query is pretty straightforward. To figure out how much RAM is currently not empty, we have to go and count the empty entries which have no counterpart in pg_database. In my example, the cache is not really fully populated, but mostly empty. On a real server with real data and real load, the cache is almost always 100% in use (unless your configuration is dubious).
There is one more question many people are interested in: What does the cache know about my database? To answer that question, I will access an index to make sure some blocks will be held in shared_buffers:
|
1 2 3 4 5 |
test=# SELECT count(*) FROM pgbench_accounts WHERE aid = 4; count ------- 1 (1 row) |
The following SQL statement will calculate how many blocks from which table (r) respectively index (relkind = i) are currently cached:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
test=# SELECT c.relname, c.relkind, count(*) FROM pg_database AS a, pg_buffercache AS b, pg_class AS c WHERE c.relfilenode = b.relfilenode AND b.reldatabase = a.oid AND c.oid >= 16384 AND a.datname = 'test' GROUP BY 1, 2 ORDER BY 3 DESC, 1; relname | relkind | count -----------------------+---------+------- pgbench_accounts | r | 2152 pgbench_branches | r | 5 pgbench_tellers | r | 5 pgbench_accounts_pkey | i | 4 (4 rows) |
We deliberately exclude all relations with object ID below 16384, because these low IDs are reserved for system objects. That way, the output only contains data for user tables.
As you can see, the majority of blocks in memory originate from pgbench_accounts. This query is therefore a nice way to instantly find out what is in cache and what is not. There is a lot more information to be extracted, but for most use cases those two queries will answer the most pressing questions.
If you want to know more about PostgreSQL and performance in general, I suggest checking out one of our other posts in PostgreSQL performance issues, or take a look at our most recent performance blogs.
When migrating from MS SQL to PostgreSQL, one of the first things people notice is that in MS SQL, object names such as tables and columns all appear in uppercase. While that is possible on the PostgreSQL side as well it is not really that common. The question therefore is: How can we rename all those things to lowercase - easily and fast?
The first question is: How can you find the tables which have to be renamed? In PostgreSQL, you can make use of a system view (pg_tables) which has exactly the information you need:
|
1 2 3 4 |
SELECT 'ALTER TABLE public.'' || tablename || '' RENAME TO ' || lower(tablename) FROM pg_tables WHERE schemaname = 'public' AND tablename <> lower(tablename); |
This query does not only return a list of tables which have to be renamed. It also creates a list of SQL commands.
If you happen to use psql directly it is possible to call ...
|
1 |
gexec |
… directly after running the SQL above. gexec will take the result of the previous statement and consider it to be SQL which has to be executed. In short: PostgreSQL will already run the ALTER TABLE statements for you.
The commands created by the statement will display a list of instructions to rename tables:
|
1 2 3 4 |
?column? ------------------------------------------ ALTER TABLE public.'AAAA' RENAME TO aaaa (1 row) |
However, the query I have just shown has a problem: It does not protect us against SQL injection. Consider the following table:
|
1 2 |
test=# CREATE TABLE 'A B C' ('D E' int); CREATE TABLE |
In this case the name of the table contains blanks. However, it could also contain more evil characters, causing security issues. Therefore it makes sense to adapt the query a bit:
|
1 2 3 4 5 |
test=# SELECT 'ALTER TABLE public.' || quote_ident(tablename) || ' RENAME TO ' || lower(quote_ident(tablename)) FROM pg_tables WHERE schemaname = 'public' AND tablename <> lower(tablename); |
The quote_ident function will properly escape the list of objects as shown in the listing below:
|
1 2 3 4 5 |
?column? ---------------------------------------------- ALTER TABLE public.'AAAA' RENAME TO 'aaaa' ALTER TABLE public.'A B C' RENAME TO 'a b c' (2 rows) |
gexec can be used to execute this code directly.
After renaming the list of tables, you can turn your attention to fixing column names. In the previous example, I showed you how to get a list of tables from pg_tables. However, there is a second option to extract the name of an object: The regclass data type. Basically regclass is a nice way to turn an OID to a readable string.
The following query makes use of regclass to fetch the list of tables. In addition, you can fetch column information from pg_attribute:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
test=# SELECT 'ALTER TABLE ' || a.oid::regclass || ' RENAME COLUMN ' || quote_ident(attname) || ' TO ' || lower(quote_ident(attname)) FROM pg_attribute AS b, pg_class AS a, pg_namespace AS c WHERE relkind = 'r' AND c.oid = a.relnamespace AND a.oid = b.attrelid AND b.attname NOT IN ('xmin', 'xmax', 'oid', 'cmin', 'cmax', 'tableoid', 'ctid') AND a.oid > 16384 AND nspname = 'public' AND lower(attname) != attname; ?column? -------------------------------------------------- ALTER TABLE 'AAAA' RENAME COLUMN 'B' TO 'b' ALTER TABLE 'A B C' RENAME COLUMN 'D E' TO 'd e' (2 rows) gexec |
gexec will again run the code we have just created, and fix column names.
As you can see, renaming tables and columns in PostgreSQL is easy. Moving from MS SQL to PostgreSQL is definitely possible - and tooling is more widely available nowadays than it used to be. If you want to read more about PostgreSQL, checkout our blog about moving from Oracle to PostgreSQL.