Have you ever heard about cursors in PostgreSQL or in SQL in general? If not you should definitely read this article in depth and learn how to reduce memory consumption in PostgreSQL easily. Cursors have been around for many years and are in my judgement one of the most underappreciated feature of all times. Therefore, it makes sense to take a closer look at cursors and see what they can be used for.
Table of Contents
Consider the following example:
|
1 2 3 4 5 |
test=# CREATE TABLE t_large (id int); CREATE TABLE test=# INSERT INTO t_large SELECT * FROM generate_series(1, 10000000); INSERT 0 10000000 |
I have created a table, which contains 10 million rows so that we can play with the data. Let us run a simple query now:
|
1 2 3 4 5 6 7 |
test=# SELECT * FROM t_large; id ---------- 1 2 3 … |
The first thing you will notice is that the query does not return immediately. There is a reason for that: PostgreSQL will send the data to the client and the client will return as soon as ALL the data has been received. If you happen to select a couple thousand rows, life is good, and everything will be just fine. However, what happens if you do a “SELECT * ...” on a table containing 10 billion rows? Usually the client will die with an “out of memory” error and your applications will simply die. There is no way to keep such a large table in memory. Throwing even more RAM at the problem is not feasible either.
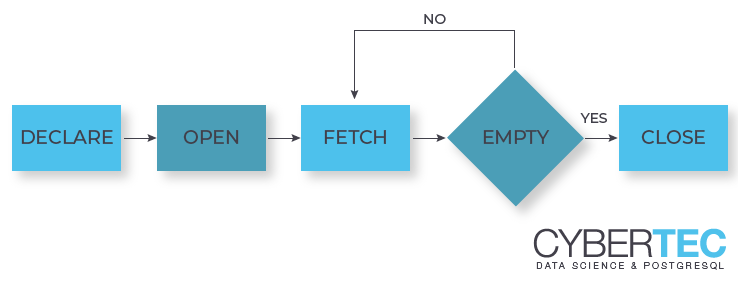
DECLARE CURSOR and FETCH can come to the rescue. What is the core idea? We can fetch data in small chunks and only prepare the data at the time it is fetched - not earlier. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=# BEGIN; BEGIN test=# DECLARE mycur CURSOR FOR SELECT * FROM t_large WHERE id > 0; DECLARE CURSOR test=# FETCH NEXT FROM mycur; id ---- 1 (1 row) test=# FETCH 4 FROM mycur; id ---- 2 3 4 5 (4 rows) test=# COMMIT; COMMIT |
The first important thing to notice is that a cursor can only be declared inside a transaction. However, there is more: The second important this is that DECLARE CURSOR itself is lightning fast. It does not calculate the data yet but only prepares the query so that your data can be created when you call FETCH. To gather all the data from the server you can simply run FETCH until the resultset is empty. At the you can simply commit the transaction.
Note that a cursor is closed on commit as you can see in the next listing:
|
1 2 3 |
test=# FETCH 4 FROM mycur; ERROR: cursor 'mycur' does not exist test |
The FETCH command is ways more powerful than most people think. It allows you to navigate in your resultset and fetch rows as desired:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=# h FETCH Command: FETCH Description: retrieve rows from a query using a cursor Syntax: FETCH [ direction [ FROM | IN ] ] cursor_name where direction can be empty or one of: NEXT PRIOR FIRST LAST ABSOLUTE count RELATIVE count count ALL FORWARD FORWARD count FORWARD ALL BACKWARD BACKWARD count BACKWARD ALL |
Cursors are an easy and efficient way to retrieve data from the server. However, you have to keep one thing in mind: Latency. Asking the network for one row at a time will add considerable network overhead (latency). It therefore makes sense to fetch data in reasonably large chunks. I found it useful to fetch 10.000 rows at a time. 10.000 can still reside in memory easily while still ensuring reasonably low networking overhead. Of course, I highly encourage you to do your own experience to see, what is best in your specific cases.
Cursors are treated by the optimizer in a special way. If you are running a “normal” statement PostgreSQL will optimize for total runtime. It will assume that you really want all the data and optimize accordingly. However, in case of a cursor it assumes that only a fraction of the data will actually be consumed by the client. The following example shows, how this works:
|
1 2 3 4 5 6 7 8 |
test=# CREATE TABLE t_random AS SELECT random() AS r FROM generate_series(1, 1000000); SELECT 1000000 test=# CREATE INDEX idx_random ON t_random (r); CREATE INDEX test=# ANALYZE ; ANALYZE |
I have created a table, which contains 1 million random rows. Finally, I have created a simple index. To make sure that the example works I have told the optimizer that indexes are super expensive (random_page_cost):
|
1 2 |
test=# SET random_page_cost TO 100; SET |
Let us take a look at an example now: If the query is executed as cursor you will notice that PostgreSQL goes for an index scan to speed up the creation of the first 10% of the data. If the entire resultset is fetched, PostgreSQL will go for a sequential scan and sort the data because the index scan is considered to be too expensive:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
test=# BEGIN; BEGIN test=# explain DECLARE cur CURSOR FOR SELECT * FROM t_random ORDER BY r; QUERY PLAN ------------------------------------------------------------------------------------------- Index Only Scan using idx_random on t_random (cost=0.42..732000.04 rows=1000000 width=8) (1 row) test=# explain SELECT * FROM t_random ORDER BY r; QUERY PLAN ------------------------------------------------------------------------------------- Gather Merge (cost=132326.50..229555.59 rows=833334 width=8) Workers Planned: 2 -> Sort (cost=131326.48..132368.15 rows=416667 width=8) Sort Key: r -> Parallel Seq Scan on t_random (cost=0.00..8591.67 rows=416667 width=8) (5 rows) test=# COMMIT; COMMIT |
The main question arising now is: How does the optimizer know that the first 10% should be fast and that we are not looking for the entire resultset? A runtime setting is going to control this kind of behavior: cursor_tuple_fraction will configure this kind of behavior:
|
1 2 3 4 5 |
test=# SHOW cursor_tuple_fraction; cursor_tuple_fraction ----------------------- 0.1 (1 row) |
The default value is 0.1, which means that PostgreSQL optimizes for the first 10%. The parameter can be changed easily in postgresql.conf just for your current session.
So far you have seen that a cursor can only be used inside a transaction. COMMIT or ROLLBACK will destroy the cursor. However, in some (usually rare) cases it can be necessary to have cursors, which actually are able to survive a transaction. Fortunately, PostgreSQL has a solution to the problem: WITH HOLD cursors.
Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 |
test=# BEGIN; BEGIN test=# DECLARE cur CURSOR WITH HOLD FOR SELECT * FROM t_random ORDER BY r; DECLARE CURSOR test=# timing Timing is on. test=# COMMIT; COMMIT Time: 651.211 ms |
As you can see the WITH HOLD cursor has been declared just like a normal cursor. The interesting part is the COMMIT: To make sure that the data can survive the transaction PostgreSQL has to materialize the result. Therefore, the COMMIT takes quite some time. However, the FETCH can now happen after the COMMIT:
|
1 2 3 4 5 6 7 8 |
test=# FETCH 4 FROM cur; r ---------------------- 2.76602804660797e-07 6.17466866970062e-07 3.60095873475075e-06 4.77954745292664e-06 (4 rows) |
If you are making use of WITH HOLD cursors you have to keep in mind that the cursor has to be closed as well. Otherwise your connection will keep accumulating new cursors and store the result.
|
1 2 3 4 5 |
test=# h CLOSE Command: CLOSE Description: close a cursor Syntax: CLOSE { name | ALL } |
Do you want to learn more about PostgreSQL and the optimizer in general consider? Check out one of our blog posts right now.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.

The problem in general is using a cursor across pooled connections. Nowadays web applications need to use a connection pool and the requirement would be to open a cursor on one connection and then fetch from it on another one and close it on another. What we need is some sort of handle to the cursor that is independent from the connection that created it. Lacking this we need to implement this functionality in client code which is in general suboptimal. The result is most programmers resort to keysets or LIMIT OFFSET clauses, repeating the whole query every time and losing consistency.
This won't be efficient for all queries, but typically with keyset pagination and the proper index you don't have to repeat the whole query, ony a query that specifically gets the required rows and can be fast. True, you don't get a consistent snapshot of the database.
I agree but this is application code. Wouldn't it be better if ithis was a functionality exposed by the RDBMS engine? Considering the quality of the MVCC implementation in Postgres it could be possibile to hold on a query result for a significant amount of time without query materialization, which is another possibility you have if the RDBMS prefers this route. This would be very useful for interactively paged datasets and it may be possibile to build additional functionality on top of it like filtering and sorting.
Of course you'd use keyset pagination in application code - where else?
Given the PostgreSQL architecture, it is virtually impossible to implement a cursor that is shared by several database sessions. Each session has its own backend process, and query execution and cursors are in process private memory, not in shared memory.
I understand it is probably very difficult. But I was expressing a requirement from a user standpoint and not from an implementer one. Still I think it may not be impossibile. Impossible is an ultimate word and nothing in software is really ultimate.
I understand your concern.
A "cursor" like you imagine it is pretty much like a table. So why not just use a table? Fill it with the query result, add numbering and read your data from there.
If your complaint with this solution is that several such things need to exist in parallel and it is annoying to have to assign a globally unique name to them, you'd have the same problem with a "cursor" that is visible in all database sessions.
Actually I've been doing this sometimes. The problem is actually you need so many tables as you said and they are visible as schema objects while the idea of a cursor was to be a hidden object that is only accessible through a "handle" and when the handle is closed it goes away, like a temporary file. Also using a table requires you to write the full query result to it while a cursor can be more efficient and access the data on demand as clearly described in the post.