Machine Learning is part of Artificial Intelligence, which both are sub categories of Data Science. Basically, it is all about the generation of artificial knowledge from the experience of a machine or a system. Based on existing data and algorithms, IT systems should recognize patterns and laws and independently develop adequate solutions.
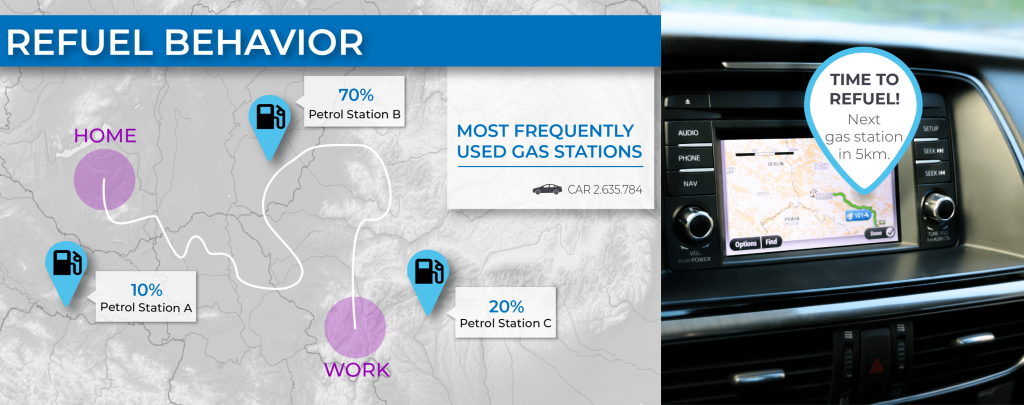
The driving-behaviour of a driver may indicate when he tends to refuel his car. Some people refuel when the fuel tank is empty – other customers already refuel again when the fuel gauge is set to “½”. So you can calculate an individual refuelling profile and use the monitor to suggest a cheap gas station nearby to the driver, to help him save money. In the long term, it would also be feasible to find local business partners and, for example, present their special offers to end-users. In this way, suggestions can be made for low-cost petrol stations or restaurants on the route to the revenue stream.
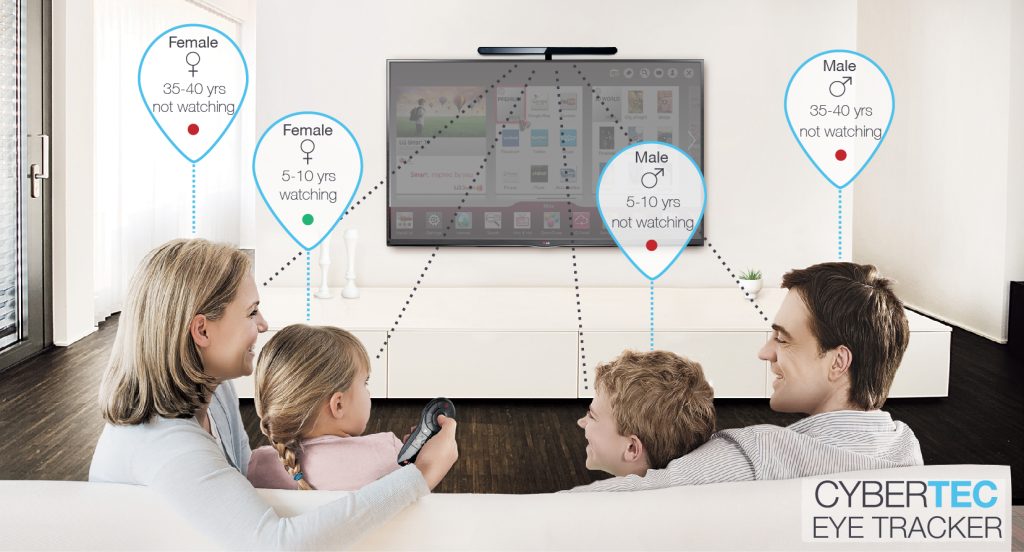
Modern technologies, such as machine learning, can be used to analyse the typical television behaviour of a family in depth. For example, a device is implemented in the television-set that uses eye tracking, to detect whether and how many consumers are actually watching actively and can determine the channel using sound recordings. Based on this collected data, patterns can be analyzed and used predictively for individual advertising broadcasts. So if only the 10-year-old daughter watches attentively anyway, why broadcast a detergent advertisement? In this case, advertising that targets specifically this younger target group would be much more effective, wouldn’t it?
When data is generated as in the examples described above, masses of data are collected. Often these huge amounts of data are simply “thrown” into a matrix and afterwards you would not only need a lot of time, but also a good memory to prepare these data sets for the machine learning process. So why not prepare the data in PostgreSQL right away? This saves time and money, is much more flexible and easier to implement.
You can read how to prepare your PostgreSQL database for machine learning in this blog post.
Learn more about how to run the Kmeans algorithm directly in your PostgreSQL database.
Reinforcement Learning: Read more about how RL algorithms work in this blog post.
Did you know that you can use machine learning in a PostgreSQL database to economically run backups? Learn more in our free white paper “Using Machine learning to back up data in a cost-effective way”!
If you would like to learn more about this topic, you can register for our five-day beginners course “Introduction to Machine Learning“. This course is intended for technical analysts or mid-level managers who are willing to do their first steps in Machine Learning.
Contact us today to discuss how CYBERTEC can help you implement PostgreSQL-based data science. We offer prompt delivery, professional work and 20 years of PostgreSQL experience.