As far as PostgreSQL is concerned, GIN means an access method (index type) rather than a drink. The acronym stands for Generalized Inverted Index. This article tries to explain how data is organized in the GIN index and how search works.
Table of Contents
The current implementation of GIN index has much to do with B-tree, so let's look at B-tree first.
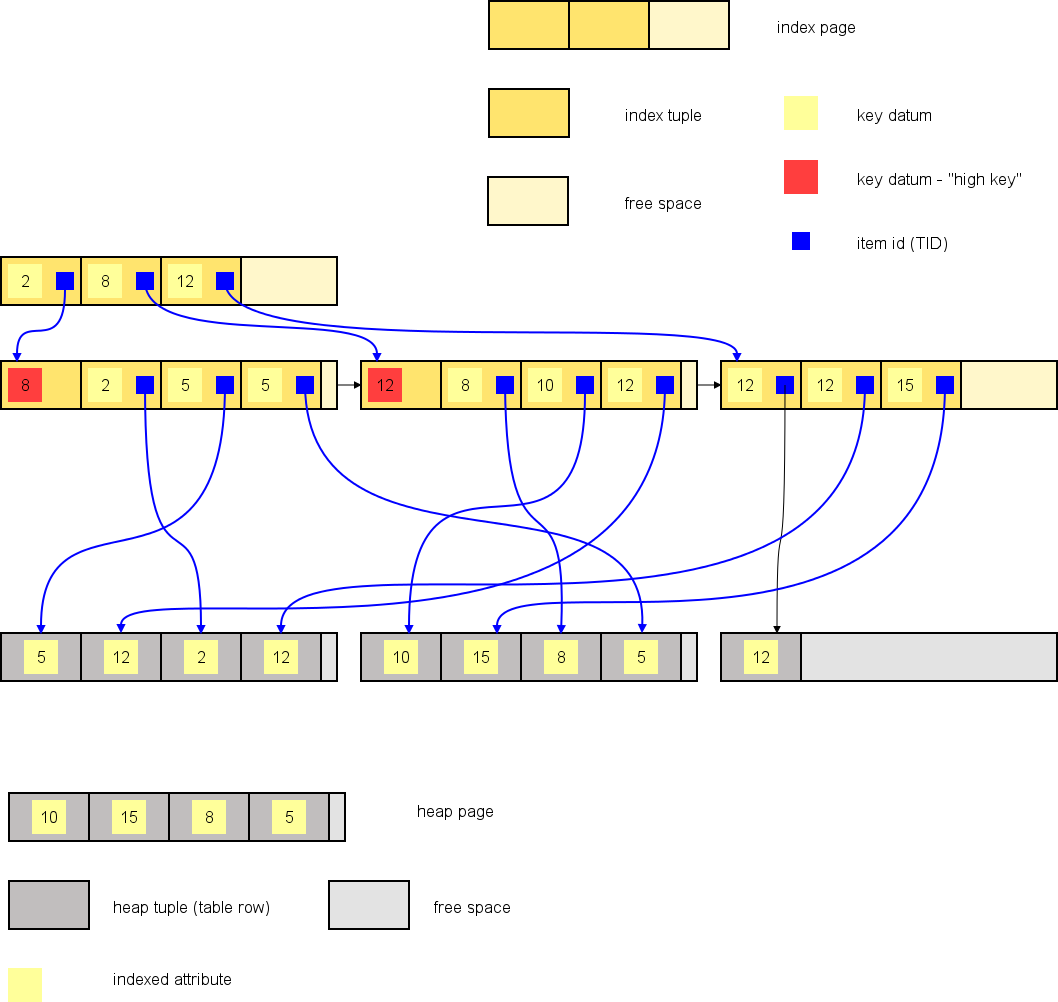
The index consists of pages, each containing as many index tuples as space allows. Index tuple is a structure containing:
(A high key is a special case of an index tuple. It merely contains a key value such that all tuples on the page are lower than or equal to it. It does not point to any other index tuple.)
Tuple Identifier (TID) (sometimes called item pointer) is a structure pointing to the physical location of data on a disk. It tells on which page within a table or index the tuple is located, and where exactly on that page it is.
A new index tuple must be inserted into the tree for each table row that we index, even if another row having the same key value already has been indexed. Such an insertion can possibly cause page split, affecting one or more pages of the index.
As for the internal pages, there's no meaningful difference between B-tree and GIN. What makes the difference are leaf pages. Depending on the number of entries which have the same key value, one of the following takes place.
The first kind of GIN index leaf page is one containing a posting list.
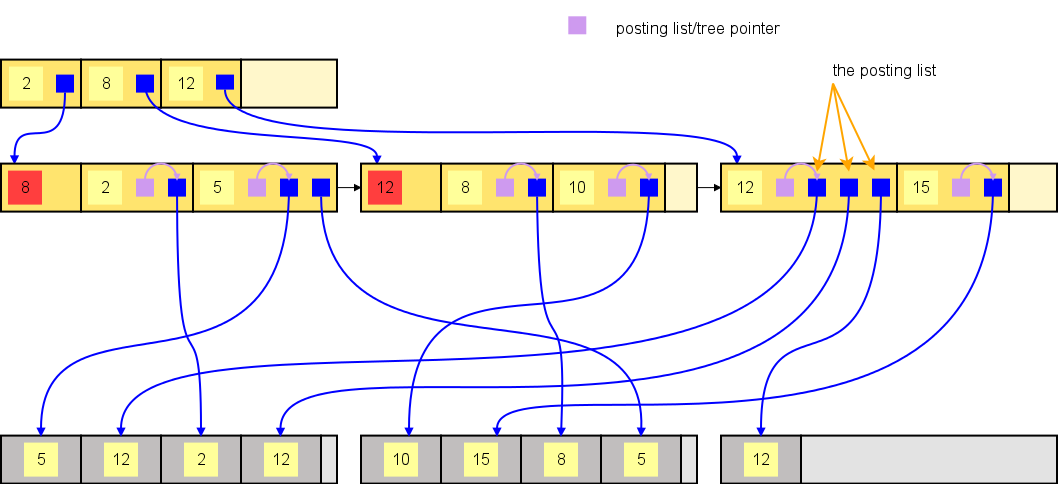
A single index tuple exists for each key entry (i.e. unique key value) on the index leaf page. That index tuple does not point directly to the corresponding row(s). Instead it points to a posting list, which is a list of pointers (TIDs) to all rows containing the appropriate key value. In order to index a new row that already has a key entry in the tree for the indexed attribute (column), we only need to find the entry, and add the TID of the new row to the posting list. This does not trigger any page split in the index tree.
The items in a posting list are sorted by the TID in ascending order. In other words, arrows from the TIDs of a particular posting list do not cross each other.
If too many rows which all have the same value of the indexed attribute are inserted, multiple pages are allocated for the TIDs and these constitute a so-called posting tree.

The posting tree is a separate B-tree structure stored on pages of the GIN index, where the TID of the indexed row is used as a key - this way we can easily maintain the TIDs sorted, as we do in a posting list.
Exactly one index tuple of the entry tree (i.e. the "main tree") points to a particular posting tree. That means there can be many posting trees in a single GIN index, each representing a specific key value. A specific feature of the GIN index is that a single table row can be referenced by multiple (or many) TIDs, each located in a different posting list/tree.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.