
(Updated 2023-06-22) If you've heard about TCP keepalive but aren't sure what that is, read on. If you've ever been surprised by error messages like:
server closed the connection unexpectedlySSL SYSCALL error: EOF detectedunexpected EOF on client connectioncould not receive data from client: Connection reset by peerthen this article is for you.
There are several possible causes for broken connections:
The first two messages in the above list can be the consequence of a PostgreSQL server problem. If the server crashes for whatever reason, you'll see a message like that. To investigate whether there is a server problem, you should first look into the PostgreSQL log and see if you can find a matching crash report.
We won't deal with that case in the following, since it isn't a network problem.
If the client exits without properly closing the database connection, the server will get an end-of-file or an error while communicating on the network socket. With the new session statistics introduced in v14, you can track the number of such “abandoned” database connections in pg_stat_database.sessions_abandoned.
For example, if an application server fails and is restarted, it typically won't close the connections to the database server. This isn't alarming, and the database server will quickly detect it when the server tries to send data to the client. But if the database session is idle, the server process is waiting for the client to send the next statement (you can see the wait_event “ClientRead” in pg_stat_activity). Then the server won't immediately notice that the client is no longer there! Such lingering backend processes occupy a process slot and can cause you to exceed max_connections.
PostgreSQL v14 has introduced a new parameter idle_session_timeout which closes idle connections after a while. But that will terminate “healthy” idle connections as well, so it isn't a very good solution. TCP keepalive provides a much better solution to this problem.
Sometimes both ends of the database connection experience the same problem: each sees that the other end “hung up on them”. In that case, the problem lies somewhere between the database client and the server.
Network connections can get disconnected if there is a real connectivity problem. There's nothing you can do to change that on the software level. But very often, disconnections are caused by the way firewalls or routers are configured. The network component may have to “memorize” the state of each open connection, and the resources for that are limited. So it can seem expedient to “forget” and drop connections that have been idle for a longer time.
Since a lot of today's TCP traffic is via HTTP, and HTTP is stateless, that's not normally a problem. If your HTTP connection is broken, you simply establish a new connection for your next request, which isn't very expensive. But databases are different:
This is where TCP keepalive comes in handy as a way to keep idle connections open.
Keepalive is a functionality of the TCP protocol. When you set the SO_KEEPALIVE option on a TCP network socket, a timer will start running as soon as the socket becomes idle. When the keepalive idle time has expired without further activity on the socket, the kernel will send a “keepalive packet” to the communication partner. If the partner answers, the connection is considered good, and the timer starts running again.
If there is no answer, the kernel waits for the keepalive interval before sending another keepalive packet. This process is repeated until the number of keepalive packets sent reaches the keepalive count. After that, the connection is considered dead, and attempts to use the network socket will result in an error.
Note that it is the operating system kernel, not the application (database server or client) that sends keepalive messages. The application is not aware of this process.
TCP keepalive serves two purposes:
The default values for the keepalive parameters vary from operating system to operating system. On Linux and Windows, the default values are:
Thanks to Vahid Saber for the MacOS settings!
To keep firewalls and routers from closing an idle connection, we need a much lower setting for the keepalive idle time. Then keepalive packets get sent before the connection is closed. This will trick the offending network component into believing that the connection isn't idle, even if neither database client nor server send any data.
For this use case, keepalive count and keepalive interval are irrelevant. All we need is for the first keepalive packet to be sent early enough.
For this use case, reducing the keepalive idle time is often not enough. If the server sends nine keepalive packets with an interval of 75 seconds, it will take more than 10 minutes before a dead connection is detected. So we'll also reduce the keepalive count, or the keepalive interval, or both - as in this case.
There is still one missing piece to the puzzle: even if the operating system detects that a network connection is broken, the database server won't notice, unless it tries to use the network socket. If it's waiting for a request from the client, that will happen immediately. But if the server is busy executing a long-running SQL statement, it won't notice the dead connection until the query is done and it tries to send the result back to the client! To prevent this from happening, PostgreSQL v14 has introduced the new parameter client_connection_check_interval, which is currently only supported on Linux. Setting this parameter causes the server to “poll” the socket regularly, even if it has nothing to send yet. That way, it can detect a closed connection and interrupt the execution of the SQL statement.
The PostgreSQL server always sets SO_KEEPALIVE on TCP sockets to detect broken connections, but the default idle timeout of two hours is very long.
You can set the configuration parameters tcp_keepalives_idle, tcp_keepalives_interval and tcp_keepalives_count (the last one is not supported on Windows) to change the settings for all server sockets.
This is the most convenient way to configure TCP keepalive for all database connections, regardless of the client used.
The PostgreSQL client shared library libpq has the connection parameters keepalives_idle, keepalives_interval and keepalives_count (again, the latter is not supported on Windows) to configure keepalive on the client side.
These parameters can be used in PostgreSQL connection strings with all client interfaces that link with libpq, for example, Psycopg or PHP.
The PostgreSQL JDBC driver, which does not use libpq, only has a connection parameter tcpKeepAlive to enable TCP keepalive (it is disabled by default), but no parameter to configure the keepalive idle time and other keepalive settings.
Instead of configuring keepalive settings specifically for PostgreSQL connections, you can change the operating system default values for all TCP connections - which can be useful, if you are using a PostgreSQL client application that doesn't allow you to set keepalive connection parameters.
On Linux, this is done by editing the /etc/sysctl.conf file:
|
1 2 3 4 |
# detect dead connections after 70 seconds net.ipv4.tcp_keepalive_time = 60 net.ipv4.tcp_keepalive_intvl = 5 net.ipv4.tcp_keepalive_probes = 3 |
To activate the settings without rebooting the machine, run
|
1 |
sysctl -p |
On older MacOS versions, you can also edit /etc/sysctl.conf, but the parameters are different:
|
1 2 3 4 |
# detect dead connections after 70 seconds net.inet.tcp.keepidle = 60000 net.inet.tcp.keepintvl = 5000 net.inet.tcp.keepcnt = 3 |
On newer MacOS versions (tested on 13), create the file /Library/LaunchDaemons/sysctl.plist
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Label sysctl Program /usr/sbin/sysctl ProgramArguments /usr/sbin/sysctl net.inet.tcp.keepidle=60000 net.inet.tcp.keepintvl=5000 inet.inet.tcp.keepcnt=3 RunAtLoad |
You will have to reboot to activate the changes.
On Windows, you change the TCP keepalive settings by adding these registry keys:
|
1 2 |
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\KeepAliveTime HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\KeepAliveInterval |
As noted above, there is no setting for the number of keepalive probes, which is hard-coded to 10. The registry keys must be of type DWORD, and the values are in milliseconds rather than in seconds.
After changing these keys, restart Windows to activate them.
Configuring TCP keepalive can improve your PostgreSQL experience, either by keeping idle database connections open, or through the timely detection of broken connections. You can do configure keepalive on the PostgreSQL client, the server, or on the operating system.
In addition to configuring keepalive, set the new parameter client_connection_check_interval to cancel long-running queries when the client has abandoned the session.
To learn more about terminating database connections, see our blog post here.
If you would like to learn about connections settings, see my post about max_connections.

Both cursors and transactions are basic ingredients for developing a database application. This article describes how cursors and transactions interact and how WITH HOLD can work around their limitations. We will also see the dangers involved and how to properly use WITH HOLD cursors in a PL/pgSQL procedure.
When a query is ready for execution, PostgreSQL creates a portal from which the result rows can be fetched. During normal query execution, you receive the whole result set in one step. In contrast, a cursor allows you to fetch the result rows one by one. A cursor marks a position within a result set. Cursors are particularly useful in procedural code on the client or in the database, because they allow you to loop through the query results. Another advantage is that a cursor allows you to have more than one SQL statement running at the same time, which is normally not possible in a single database session.
A simple example for PL/pgSQL code that uses a cursor would be:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
DO LANGUAGE plpgsql $$DECLARE /* declare and open a cursor */ c CURSOR FOR SELECT table_schema, table_name FROM information_schema.tables WHERE table_schema = 'mydata' AND table_name LIKE 'old_%'; v_schema text; v_name text; BEGIN LOOP /* get next result row */ FETCH c INTO v_schema, v_name; /* system variable FOUND is set by FETCH */ EXIT WHEN NOT FOUND; /* avoid SQL injection */ EXECUTE format( 'DROP TABLE %I.%I', v_schema, v_name ); END LOOP; /* not necessary */ CLOSE c; END;$$; |
In this example, the SELECT is executed concurrently with the DROP TABLE statements.
The above is not the most readable way to write this in PL/pgSQL (you could have used “FOR v_schema, v_name IN SELECT ... LOOP ... END LOOP;”, which uses a cursor “under the hood”), but I wanted to make the cursor explicit.
Note that it is often possible to avoid a cursor loop by using a join in the database. Such a join is more efficient, because it does all the work in a single statement. However, we have to use a cursor in our case, since we need to execute a dynamic SQL statement inside the loop.
One basic property of a PostgreSQL cursor is that it only exists for the duration of a database transaction. That is not surprising, since a cursor is a single SQL statement, and an SQL statement is always part of one transaction. In the above example we had no problem, because a DO statement is always executed in a single transaction anyway.
Cursors are automatically closed at the end of a transaction, so it is usually not necessary to explicitly close them, unless they are part of a long-running transaction and you want to free the resources allocated by the statement.
A special feature of PostgreSQL is that you can use cursors in SQL. You create a cursor with the DECLARE statement:
|
1 2 |
DECLARE name [ BINARY ] [ ASENSITIVE | INSENSITIVE ] [ [ NO ] SCROLL ] CURSOR [ { WITH | WITHOUT } HOLD ] FOR query |
Here is a short description of the different options:
BINARY will fetch the results in the internal binary format, which may be useful if you want to read bytea columns and avoid the overhead of escaping them as stringsSCROLL means that you can move the cursor position backwards to fetch the same rows several timesWITH HOLD creates a cursor that is not automatically closed at the end of a transactionASENSITIVE and INSENSITIVE are redundant in PostgreSQL and are there for SQL standard compatibilityThere is also an SQL statement FETCH that is more powerful than its PL/pgSQL equivalent, in that it can fetch more than one row at a time. Like PL/pgSQL, SQL also has a MOVE statement that moves the cursor position without retrieving rows.
SQL cursors are closed with the CLOSE statement, or by the end of the transaction.
SCROLL cursorsSome execution plans, like a B-tree index scan or a sequential scan, can be executed in both directions. A cursor for a query with such an execution plan is implicitly scrollable, that is, you can move the cursor position backwards in the result set. PostgreSQL calculates query result rows “on demand” and streams them to the client, so scrollable cursors for such queries come with no extra cost.
Other, more complicated execution plans require the explicit keyword SCROLL for the cursor to become scrollable. Such cursors incur an overhead, because the server must cache the entire result set.
Here is a little example that showcases scrollable cursors:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
BEGIN; /* this cursor would be implicitly scrollable */ DECLARE c SCROLL CURSOR FOR SELECT * FROM generate_series(1, 10); FETCH 5 FROM c; generate_series ═════════════════ 1 2 3 4 5 (5 rows) MOVE BACKWARD 2 FROM c; FETCH BACKWARD 2 FROM c; generate_series ═════════════════ 2 1 (2 rows) /* sixth result row */ FETCH ABSOLUTE 6 FROM c; generate_series ═════════════════ 6 (1 row) FETCH ALL FROM c; generate_series ═════════════════ 7 8 9 10 (4 rows) COMMIT; |
The SQL standard distinguishes SENSITIVE, INSENSITIVE and ASENSITIVE cursors. A sensitive cursor reflects modifications of the underlying data; one consequence of this is that scrolling back to a previous row might fetch a different result. PostgreSQL does not implement sensitive cursors: that would be difficult, because a statement always sees a stable snapshot of the data in PostgreSQL.
PostgreSQL cursors are always insensitive, which means that changes in the underlying data after the cursor has started processing are not visible in the data fetched from the cursor. “Asensitive”, which means that the sensitivity is implementation dependent, is the same as “insensitive” in PostgreSQL.
Note that this insensitivity also applies if you modify a table via the special statements “UPDATE/DELETE ... WHERE CURRENT OF ”.
WITH HOLD corsorsSince WITH HOLD cursors live longer than a transaction, but statements don't, PostgreSQL must calculate the complete result set at COMMIT time and cache it on the server. This can result in COMMIT taking an unusually long time.
Moreover, WITH HOLD cursors are not automatically closed at the end of the transaction, so you must not forget to CLOSE them if you don't want the result set to hog server resources until the end of the database session.
Here is an example of a WITH HOLD cursor in action:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
BEGIN; DECLARE c CURSOR WITH HOLD FOR SELECT i FROM generate_series(1, 10) AS i; FETCH 3 FROM c; i ═══ 1 2 3 (3 rows) COMMIT; FETCH 3 FROM c; i ═══ 4 5 6 (3 rows) /* important */ CLOSE c; |
Cursors in PL/pgSQL are variables of the special data type refcursor. The value of such a variable is actually a string. That string is the name of the portal that is opened when a query is bound to the cursor variable and the cursor is opened.
Using refcursor variables, you can also pass cursors between PL/pgSQL functions or procedures:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
CREATE FUNCTION c_open(n integer) RETURNS refcursor LANGUAGE plpgsql AS $$DECLARE /* a query is bound to the cursor variable */ c CURSOR (x integer) FOR SELECT * FROM generate_series(1, x); BEGIN /* the cursor is opened */ OPEN c(n); RETURN c; END;$$; CREATE FUNCTION c_fetch(cur refcursor) RETURNS TABLE (r integer) LANGUAGE plpgsql AS $$BEGIN LOOP FETCH cur INTO r; EXIT WHEN NOT FOUND; RETURN NEXT; END LOOP; END;$$; SELECT c_fetch(c_open(5)); c_fetch ═════════ 1 2 3 4 5 (5 rows) |
Cursor declarations in PL/pgSQL support SCROLL, but not WITH HOLD, for the historical reason that PostgreSQL functions always run inside a single transaction. Also, you can only FETCH a single row at a time from a PL/pgSQL cursor.
WITH HOLD cursors in PL/pgSQL proceduresProcedures, introduced in PostgreSQL v11, support transaction commands like COMMIT and ROLLBACK under certain circumstances. Consequently, it would be useful to have WITH HOLD cursors in procedures. There are two ways to work around the lack of WITH HOLD cursors in PL/pgSQL:
refcursor argument to the procedureHere is sample code that illustrates the second technique:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
CREATE PROCEDURE del_old() LANGUAGE plpgsql AS $$DECLARE /* assign the portal name */ c refcursor := 'curs'; v_schema text; v_name text; BEGIN /* dynamic SQL to create the cursor */ EXECUTE $_$DECLARE curs CURSOR WITH HOLD FOR SELECT table_schema, table_name FROM information_schema.tables WHERE table_schema = 'mydata' AND table_name LIKE 'old_%'$_$; LOOP FETCH c INTO v_schema, v_name; EXIT WHEN NOT FOUND; /* * We need to make sure that the cursor is closed * in the case of an error. For that, we need an * extra block, because COMMIT cannot be used in * a block with an EXCEPTION clause. */ BEGIN /* avoid SQL injection */ EXECUTE format( 'DROP TABLE %I.%I', v_schema, v_name ); EXCEPTION WHEN OTHERS THEN CLOSE c; RAISE; WHEN query_canceled THEN CLOSE c; RAISE; END; /* reduce deadlock risk when dropping many tables */ COMMIT; END LOOP; /* we need to close the cursor */ CLOSE c; END;$$; |
Note how the code makes dead sure that the cursor cannot “leak” from the procedure!
Both cursors and transactions are well-known database features. Normally, cursors exist only within a single database transaction. But by using WITH HOLD, you can escape that limitation. Useful as this feature is, you have to be aware of the performance impact during COMMIT, and you have to make sure that you close the cursor to free the server's resources.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
In this article, I will answer the questions: why isn't there a SHOW TABLES command in PostgreSQL, when will SHOW TABLES in PostgreSQL be available, and how do I list tables with native PostgreSQL methods?
People who come from MySQL are always asking the same question: why doesn't the command SHOW TABLES work in PostgreSQL ?
|
1 2 |
postgres=> SHOW TABLES; ERROR: unrecognized configuration parameter 'tables' |
First of all, there is a SHOW command in PostgreSQL, but it's responsible for returning the value of a run-time parameter.
By the way, we have a comprehensive article on how to set PostgreSQL parameters.
But how can it be that the same command means opposite things in the two most popular open-source RDBMS? The answer is quite obvious: the SHOW command is not part of the SQL ISO or ANSI standard. That allows anybody to use it as an extension to standard SQL.
I would say never! First, the SHOW command has its own semantics in PostgreSQL. Second, it's not part of the SQL standard. And probably it never will be, because the standard committee decided to use a different approach, called the Information Schema. However, even now, information schema support is not at the appropriate level in most databases.
Answers to this question may be found in a lot of places. I will just repeat them here.
If you're using the psql command-line utility, then try the dt built-in command.
Mnemonic rule: dt = Describe Table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
-- list visible tables from search_path timetable=> dt List of relations Schema | Name | Type | Owner --------+-----------------+-------+----------- public | bar | table | scheduler public | foo | table | scheduler public | history_session | table | scheduler public | location | table | scheduler public | migrations | table | scheduler public | test | table | pasha (6 rows) -- list tables from 'timetable' schema timetable=> dt timetable.* List of relations Schema | Name | Type | Owner -----------+----------------+-------+----------- timetable | active_session | table | scheduler timetable | chain | table | scheduler timetable | chain_log | table | scheduler timetable | dummy_log | table | scheduler timetable | execution_log | table | scheduler timetable | log | table | scheduler timetable | migration | table | scheduler timetable | parameter | table | scheduler timetable | run_status | table | scheduler timetable | task | table | scheduler (10 rows) -- describe table 'bar' timetable=> dt bar List of relations Schema | Name | Type | Owner --------+------+-------+----------- public | bar | table | scheduler (1 row) -- describe table 'bar' with details timetable=> dt+ bar List of relations Schema | Name | Type | Owner | Persistence | Size | Description --------+------+-------+-----------+-------------+---------+------------- public | bar | table | scheduler | permanent | 0 bytes | (1 row) |
psql, then these SQLs are probably the best to show tables in PostgreSQL:|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
timetable=> SELECT n.nspname AS schema, t.relname AS table_name, t.relkind AS type, t.relowner::regrole AS owner FROM pg_class AS t JOIN pg_namespace AS n ON t.relnamespace = n.oid /* only tables and partitioned tables */ WHERE t.relkind IN ('r', 'p') /* exclude system schemas */ AND n.nspname !~~ ALL ('{pg_catalog,pg_toast,information_schema,pg_temp%}'); schema | table_name | type | owner --------------+-------------------+------+----------- timetable | chain_log | r | scheduler timetable | dummy_log | r | scheduler ... public | test | r | pasha public | location | r | scheduler (75 rows) timetable=> SELECT * FROM pg_catalog.pg_tables; schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity --------------------+-------------------------+------------+------------+------------+----------+-------------+------------- timetable | chain_log | scheduler | | t | f | f | f pg_catalog | pg_statistic | pasha | | t | f | f | f pg_catalog | pg_type | pasha | | t | f | f | f timetable | dummy_log | scheduler | | t | f | f | f ... (82 rows) |
But as you can see, they will list all the tables in the database, so you probably will need filtering anyway.
As I said, there is a SQL-standard way to show tables in PostgreSQL by querying information_schema:
|
1 2 3 4 5 6 7 8 9 10 |
timetable=> SELECT * FROM information_schema.tables WHERE table_type = 'BASE TABLE'; table_catalog | table_schema | table_name | table_type | self_referencing_column_name | reference_generation | user_defined_type_catalog | user_defined_type_schema | user_defined_type_name | is_insertable_into | is_typed | commit_action ---------------+--------------+------------------+------------+------------------------------+----------------------+---------------------------+--------------------------+------------------------+--------------------+----------+--------------- timetable | timetable | chain_log | BASE TABLE | | | | | | YES | NO | timetable | pg_catalog | pg_type | BASE TABLE | | | | | | YES | NO | timetable | timetable | dummy_log | BASE TABLE | | | | | | YES | NO | timetable | pg_catalog | pg_foreign_table | BASE TABLE | | | | | | YES | NO | timetable | timetable | migration | BASE TABLE | | | | | | YES | NO | ... (75 rows) |
There is no universal way of doing common things in all databases. Even though the SQL standard declares the Information Schema to be the proper way, not every database manufacturer implemented its support on a decent level. If you're using the native command-line psql tool, you will have built-in commands; otherwise, you need to query system tables and/or views. If you're using a GUI application, then you probably don't have this problem. Every known GUI application with PostgreSQL support allows you to list, filter, and find any objects.
In case you were wondering how to compare the content of two PostgreSQL tables, see Hans' post about creating checksums for tables.
In response to repeated customer requests seeking spatial datasets based on the OpenStreetMap service, CYBERTEC decided to start an initiative to address this demand.
CYBERTEC implemented a "download OpenStreetMap" service which periodically generates extracts of OpenStreetMap data in various forms, and outputs the data as an sql dump to streamline and simplify its usage. Extracts cover a particular region of interest-- typically, aligned with the boundaries of countries or continents. We already set extract imports’ parameters for your convenience. Import variants implicitly state how your dataset was imported into our database. New variants can be created according to your wishes, contact us for more details.
The main entry point of our service, which is free of charge, is located at https://gis.cybertec-postgresql.com/.
Importing OpenStreetMap data into PostGIS can be a hard and time-consuming task. To simplify this process and speed up the import, we decided to kick off a service offering two dataset types, periodically served as sql dumps.
pbfs.The first type of import variant is drawn from the main objective of OpenStreetMap, which is to solve spatial questions by analyzing and visualizing spatial data. There are endless ways to import and map OSM data to PostGIS in order to serve this purpose. To support most typical use cases while retaining flexibility, we decided to implement a generic import like that of OpenStreetMap Carto (https://github.com/gravitystorm/openstreetmap-carto). Incidentally, this enables us to use this dump seamlessly as a source for tiling services, such as https://switch2osm.org/serving-tiles/ or https://github.com/Overv/openstreetmap-tile-server.
A brief description of the import chain can be found at https://gis.cybertec-postgresql.com/osmtile/readme.txt.
The second type of import variant addresses the demand to solve various kinds of routing-related questions. This time, import native datasets utilizing osm2po (https://osm2po.de/), a great java application which turns pure OpenStreetMap data into a routable graph. Ideally, the resulting table will be used together with pgRouting (https://pgrouting.org/), another terrific extension which brings geospatial routing functionality to PostgreSQL.
Checkout the import chain at https://gis.cybertec-postgresql.com/osmrouting/readme.txt.
CYBERTEC offers extracts for the whole world. Since we don't see the need to re-invent the wheel, we align datasets' spatial extents with the boundaries of countries or continents. To simplify access and downloads, we structured the datasets hierarchically, as stated in figure 1.
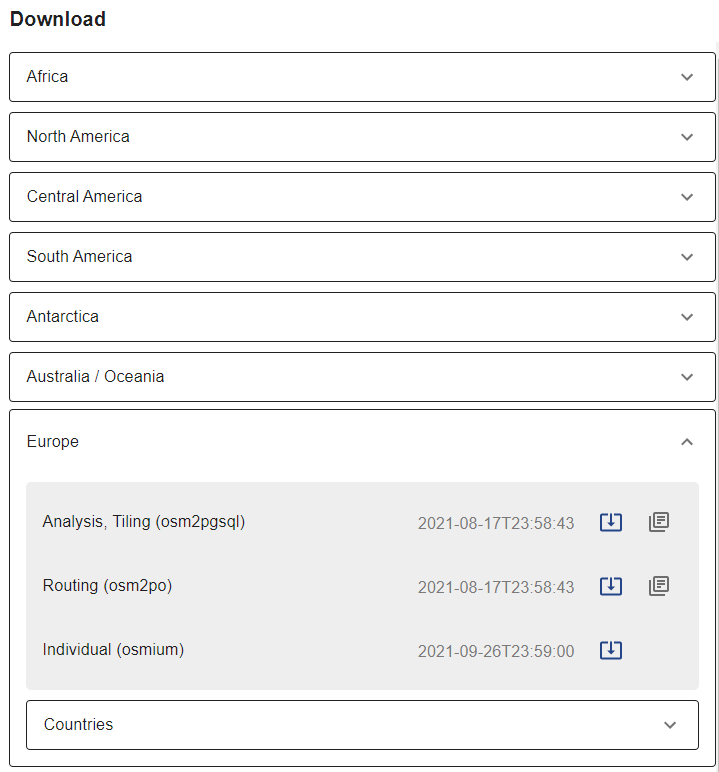
Dataset hierarchy
How often will our datasets be generated? We generate native extracts (pbfs) daily, and produce dumps 1 to 2 times per month. Currently, we try to optimize the whole process to provide more frequent current dumps for our customers.
So how can customers use our service? Let’s go through a typical customer scenario.
A customer plans to set up a tiling server which offers raster data covering Austria. Let’s assume tiling infrastructure is already up and running, however the missing link is a database containing OpenStreetMap data. Instead of utilizing osm2pgsql to import the dataset, the customer can take a nice shortcut and directly download the appropriate sql dump from our service ????.
First, head to https://gis.cybertec-postgresql.com/ and choose your region of interest. Figure 2 shows available datasets for Austria at the present time. Since we want to setup a tiling service, our dataset import variant of choice is “Analysis, Tiling”. Let’s download the latest dump for this region from https://gis.cybertec-postgresql.com/osmtile/europe/austria/osmtile_europe_austria_latest_compressed.dump
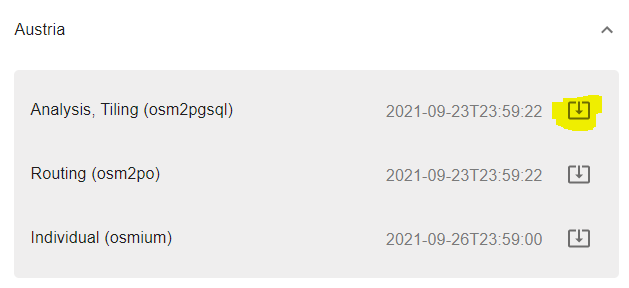
Dataset download, restore instructions
You can see instructions beside each published dump as readme.txt. For Austria, instructions can be accessed at https://gis.cybertec-postgresql.com/osmtile/europe/austria/readme.txt.
Let’s quickly look at the instructions to better understand how we must proceed. As a requirement, you must prepare the database with the extensions PostGIS and hstore enabled.
|
1 2 3 4 5 6 7 8 9 |
postgres=# create database tilingdb; CREATE DATABASE postgres=# c tilingdb psql (13.3 (Ubuntu 13.3-1.pgdg20.04+1), server 13.4 (Ubuntu 13.4-1.pgdg20.04+1)) You are now connected to database 'tilingdb' as user 'postgres'. tilingdb=# create extension postgis; CREATE EXTENSION tilingdb=# create extension hstore; CREATE EXTENSION |
Finally, the dump can be restored by executing
|
1 2 |
pg_restore -j 4 --no-owner -d tilingdb osmtile_europe_austria_latest_compressed.dump |
This results in a new database schema osmtile_europe_austria.
|
1 2 3 4 5 6 7 |
tilingdb=# dn List of schemas Name | Owner ------------------------+---------- osmtile_europe_austria | postgres public | postgres (2 rows) |
The listing below shows the tables generated within our schema.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
tilingdb=# dt+ osmtile_europe_austria. List of relations Schema | Name | Type | Owner | Persistence | Size | Description ------------------------+--------------------+-------+----------+-------------+---------+------------- osmtile_europe_austria | planet_osm_line | table | postgres | permanent | 1195 MB | osmtile_europe_austria | planet_osm_nodes | table | postgres | permanent | 3088 MB | osmtile_europe_austria | planet_osm_point | table | postgres | permanent | 323 MB | osmtile_europe_austria | planet_osm_polygon | table | postgres | permanent | 1865 MB | osmtile_europe_austria | planet_osm_rels | table | postgres | permanent | 102 MB | osmtile_europe_austria | planet_osm_roads | table | postgres | permanent | 130 MB | osmtile_europe_austria | planet_osm_ways | table | postgres | permanent | 1996 MB | (7 rows) |
This article briefly introduces CYBERTEC's brand new OpenStreetMap download service. The service has been released recently, and we are very curious what customers think about it. Please leave a message to give us feedback, discuss further dataset import variants, or in case you need assistance. Check out this post if you want to know how to start out with PostgreSQL and PostGIS.
Please leave your comments below. In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.