We recently published a patch to provide full database encryption for PostgreSQL. Many business-critical applications require full encryption to match legal or business requirements. As more and more customers asked for this, we decided to tackle this important issue. The idea behind our patch is to store data on disk in encrypted format and decrypt blocks as they are read from disk into shared buffers. As soon as a block is written to disk again, it will be encrypted automatically. Note that the entire instance is encrypted.
Table of Contents
Our patch can be downloaded here.
The idea is to make the setup process easy to understand. In addition to that it has to be secure. For our WIP patch we decided to use environment variables to store the key itself:
|
1 2 |
export PGENCRYPTIONKEY=abcdef initdb -k -K pgcrypto /data/dbencrypt/ |
The key has to be provided before initdb otherwise the instance cannot be created.
While database side encryption makes sure that data is stored safely on the node, it does have some impact on performance. To figure out how large the impact might be I decided to run some simple tests showing what is going on.
For a start I decided to try the normal pgbench stuff on my laptop. This should be enough to get an overall idea. Here is what I did:
|
1 2 |
createdb test pgbench -s 10 -i test |
First of all I created a database and a test database containing 1 million rows. To make sure that disk flushes don't destroy our data I set synchronous_commit to off. This should greatly reduce the number of disk flushes so we should get a clear picture:
|
1 2 3 |
test=# ALTER DATABASE test SET synchronous_commit TO off; ALTER DATABASE |
I ran the following benchmark to compare the results:
|
1 |
pgbench -c 4 -T 60 -S test |
4 concurrent threads hammered the database for a minute (read only). As expected the results depend very much on the configuration of PostgreSQL. Remember, a block has to be encrypted when it goes to disk and decrypted when it is fetched from the kernel. Naturally small values for shared_buffers tend to ruin performance while large shared_buffers settings tend to be very beneficial for encryption.
Here are the results:
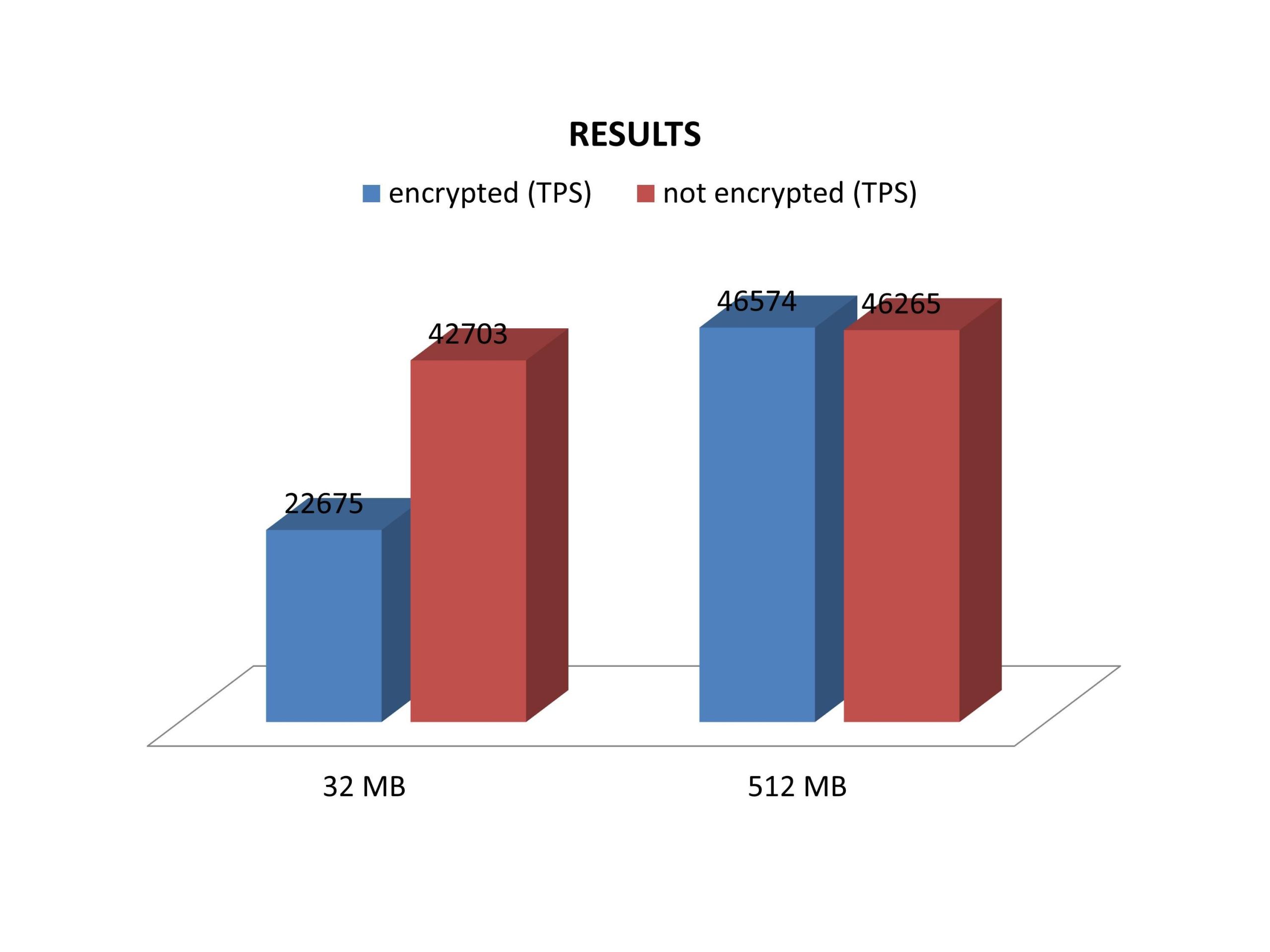
The data set we are using here is around 130 MB in size, so that quite some time is wasted during encryption and decryption. Naturally the difference decreases as more memory is added. As soon as the entire database fits into memory the performance difference will drop to close to zero as expected.
The current AES-implementation is not too great, however.
We have a prototype AES-NI implementation that does 3GB/s per core on a Haswell based system (1.25 B/cycle). Intel offers some very nice hardware support for encryption, so this is surely the way to go.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
Hello, I read this post yesterday and today I saw that ChaCha20 is now and official symmetric cipher for TLS/SSL because "it is significantly faster than AES on architectures that do not support AES-NI". It's already in libcrypto from OpenSSL, so maybe this is an alternative when AES-NI is missing?
Well, this is part of the answer. That means the data is NOT encrypted everywhere else, especially in memory, swap, client sessions, etc etc.
So far, the only way to keep data encrypted from disk to client side is to use pgcrypto and deal with it on the application side...
Sure, but e.g. Oracle TDE also provides data-at-rest encryption only. I assume that this is a feature people looking at modern alternatives to the red evil thing keep asking for because some company regulation requires it, helpful or not.