In the PostgreSQL world, as well as in order database systems, data types play a crucial role in ensuring optimal performance, efficiency, as well as semantics. Moreover, some data types are inherently easier and faster to index than others. Many people are not aware of the fact that indexes indeed make a difference, so let us take a look and see how long it takes to index the very same data using different
types.
Table of Contents
To show which differences a data type makes, we first have to create some sample table. In this case, it contains 5 data types that we want to inspect to understand how they behave:
|
1 2 3 4 5 6 7 8 |
blog=# CREATE TABLE t_demo ( v1 int, v2 int8, v3 float, v4 numeric, v5 text ); CREATE TABLE |
Finally, we use our good old friend (the generate_series function), which has served me very well over the years:
|
1 2 3 4 5 6 |
blog=# INSERT INTO t_demo SELECT x, x, x, x, x FROM ( SELECT (random()*10000000)::int4 AS x FROM generate_series(1, 50000000) ) AS y; INSERT 0 50000000 |
What this does is generate 50 million random rows and put them into my table. Note that all column entries are identical to ensure fairness for our index creation.
The data might look as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
blog=# SELECT * FROM t_demo LIMIT 10; v1 | v2 | v3 | v4 | v5 ---------+---------+---------+---------+--------- 9443332 | 9443332 | 9443332 | 9443332 | 9443332 2220480 | 2220480 | 2220480 | 2220480 | 2220480 1328189 | 1328189 | 1328189 | 1328189 | 1328189 4506728 | 4506728 | 4506728 | 4506728 | 4506728 8148249 | 8148249 | 8148249 | 8148249 | 8148249 74086 | 74086 | 74086 | 74086 | 74086 4160715 | 4160715 | 4160715 | 4160715 | 4160715 9193039 | 9193039 | 9193039 | 9193039 | 9193039 4062983 | 4062983 | 4062983 | 4062983 | 4062983 7609357 | 7609357 | 7609357 | 7609357 | 7609357 (10 rows) |
Note that PostgreSQL does not necessarily write data to disk immediately. In addition to that, there is a thing known as "hint bits", which can impact performance. We want to ensure that we can compare the time needed to create those indexes, so we VACUUM the table (for hint bits) and force a checkpoint to force everything to disk:
|
1 2 3 4 |
blog=# VACUUM ANALYZE; VACUUM blog=# CHECKPOINT; CHECKPOINT |
In this example, all tests are using the default settings of PostgreSQL, which are of course suboptimal and can be tuned as described in one of our more successful blog posts about CREATE INDEX.
One of the key settings (to be found in postgresql.conf) controlling indexing speed is maintenance_work_mem. For this quick benchmark, we kept the standard setting of 64 MB:
|
1 2 3 4 5 6 7 8 9 |
blog=# \timing Timing is on. blog=# SHOW maintenance_work_mem; maintenance_work_mem ---------------------- 64MB (1 row) Time: 1.701 ms |
Let us create the index on the integer column first:
|
1 2 3 |
blog=# CREATE INDEX ON t_demo (v1); CREATE INDEX Time: 15477.821 ms (00:15.478) |
As we can see, this is the fastest process we can expect - indexing integer is really quick because CPUs are made to handle numbers. For 64 bit integers, we see similarly good results:
|
1 2 3 |
blog=# CREATE INDEX ON t_demo (v2); CREATE INDEX Time: 16391.599 ms (00:16.392) |
However, the story starts to change if we move from integer numbers to floating point values. The process starts to be slower:
|
1 2 3 |
blog=# CREATE INDEX ON t_demo (v3); CREATE INDEX Time: 22631.174 ms (00:22.631) |
While native CPU floating point numbers (we are using ARM chips here) are still reasonably okay, we will see a massive slowdown compared to integer values when we move to "numeric":
|
1 2 3 |
blog=# CREATE INDEX ON t_demo (v4); CREATE INDEX Time: 26433.571 ms (00:26.434) |
What is the purpose of "numeric" anyway? The answer is: Accounting. Floating point numbers have different precision depending on the magnitude of the number. "numeric" ensures that the precision is exactly the way we want it to be, regardless of small or large values. Therefore, we should always use "numeric" for money, accounting, and so on. One thing has to be kept in mind at all times:
The result has to always be correct - even if it takes longer to calculate it. Therefore, one should never use "float" to handle currency.
Obviously, the by far most expensive data type is "text". Here are the numbers:
|
1 2 3 |
blog=# CREATE INDEX ON t_demo (v5); CREATE INDEX Time: 42028.606 ms (00:42.029) |
Obviously, one would not want to store numbers as text anyway, but I decided to put the value here for comparison.
After running those tests, we can compare the results and see what happens. The following graph visualizes the results:
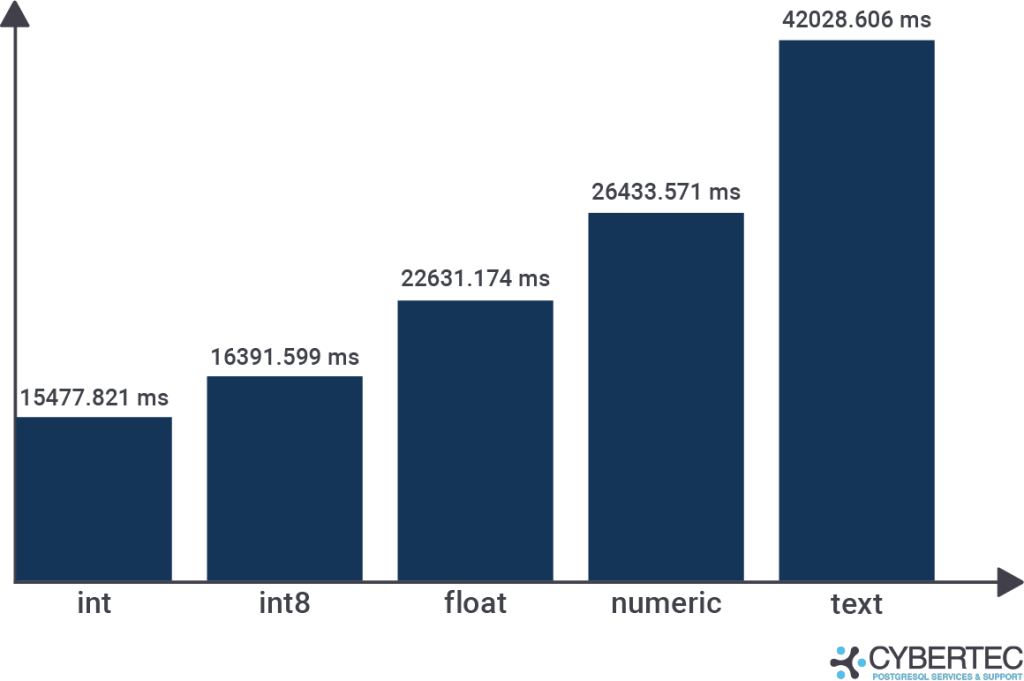
What is interesting here is that the difference in speed is quite substantial. Most people greatly underestimate those changes in performance and thus it makes sense to spread some awareness among readers.

Tried to reproduce and got interesting side-effects (only partly reproducing your numbers). Especially because indexes are typically created only once, and that's it (summary at the end):
VACUUM ANALYZE;
CHECKPOINT;
CREATE INDEX ON t_demo (v1);
Time: 49167.688 ms (00:49.168)
CREATE INDEX ON t_demo (v2);
Time: 40263.288 ms (00:40.263)
CREATE INDEX ON t_demo (v3);
Time: 58812.693 ms (00:58.813)
CREATE INDEX ON t_demo (v4);
Time: 56302.695 ms (00:56.303)
CREATE INDEX ON t_demo (v5);
Time: 133345.734 ms (02:13.346)
DROP INDEX t_demo_v1_idx;
DROP INDEX t_demo_v2_idx;
DROP INDEX t_demo_v3_idx;
DROP INDEX t_demo_v4_idx;
DROP INDEX t_demo_v5_idx;
VACUUM ANALYZE;
CHECKPOINT;
CREATE INDEX ON t_demo (v5);
Time: 119213.866 ms (01:59.214)
CREATE INDEX ON t_demo (v4);
Time: 53486.847 ms (00:53.487)
CREATE INDEX ON t_demo (v3);
Time: 49539.559 ms (00:49.540)
CREATE INDEX ON t_demo (v2);
Time: 32803.024 ms (00:32.803)
CREATE INDEX ON t_demo (v1);
Time: 33744.911 ms (00:33.745)
DROP INDEX t_demo_v1_idx;
DROP INDEX t_demo_v2_idx;
DROP INDEX t_demo_v3_idx;
DROP INDEX t_demo_v4_idx;
DROP INDEX t_demo_v5_idx;
VACUUM ANALYZE;
CHECKPOINT;
CREATE INDEX ON t_demo (v1);
Time: 30534.489 ms (00:30.534)
CREATE INDEX ON t_demo (v2);
Time: 33775.389 ms (00:33.775)
CREATE INDEX ON t_demo (v3);
Time: 47776.601 ms (00:47.777)
CREATE INDEX ON t_demo (v4);
Time: 59156.192 ms (00:59.156)
CREATE INDEX ON t_demo (v5);
Time: 124224.454 ms (02:04.224)
DROP INDEX t_demo_v1_idx;
DROP INDEX t_demo_v2_idx;
DROP INDEX t_demo_v3_idx;
DROP INDEX t_demo_v4_idx;
DROP INDEX t_demo_v5_idx;
VACUUM ANALYZE;
CHECKPOINT;
CREATE INDEX ON t_demo (v5);
Time: 119638.285 ms (01:59.638)
CREATE INDEX ON t_demo (v4);
Time: 56985.595 ms (00:56.986)
CREATE INDEX ON t_demo (v3);
Time: 49229.118 ms (00:49.229)
CREATE INDEX ON t_demo (v2);
Time: 32311.887 ms (00:32.312)
CREATE INDEX ON t_demo (v1);
Time: 33835.165 ms (00:33.835)
Summary:
v1: 0:49.168 0:33.745 0:30.534 0:33.835
v2: 0:40.263 0:32.803 0:33.775 0:32.312
v3: 0:58.813 0:49.540 0:47.777 0:49.229
v4: 0:56.303 0:53.487 0:59.156 0:56.986
v5: 2:13.346 1:59.214 2:04.224 1:59.638
select version();
PostgreSQL 16.8 (Ubuntu 16.8-0ubuntu0.24.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0, 64-bit
Any explanation?
Those numbers seem to confirm that
textis the most expensive data type to index.The differences in the measurements are perhaps due to different hardware, software or operating system.
Benchmarks are difficult to generalize...
1. INDEX SIZE:
I expected index on text should be the biggest, but it is not:
SELECT indexrelname as index_name, pg_size_pretty(pg_relation_size(indexrelid)) as index_size FROM pg_stat_all_indexes i JOIN pg_class c ON i.relid=c.oid WHERE i.relname='t_demo';
index_name | index_size
---------------+------------
t_demo_v1_idx | 562 MB
t_demo_v2_idx | 562 MB
t_demo_v3_idx | 1072 MB
t_demo_v4_idx | 1072 MB
t_demo_v5_idx | 562 MB
2. QUERY SPEEDS
It is advisable to use integer or bigint for primary keys instead of e.g. text data fields. It would be nice to see what is query execution speed difference using those types.
Interesting about the size. I'd have expected
int8to be bigger thanint. I recommend examining the indexes with thebt_page_items()function from the pageinspect extension. That should make everything clear.I wouldn't expect a big difference for an index scan, but in general it is commendable to use the best matching type (in this case,
integerorbigint).