Checkpoints are a core concept in PostgreSQL. However, many people don’t know what they actually are, nor do they understand how to tune checkpoints to reach maximum efficiency. This post will explain both checkpoints and checkpoint tuning, and will hopefully shed some light on these vital database internals.
Table of Contents
Before we talk about checkpoints in more detail, it is important to understand how PostgreSQL writes data. Let’s take a look at the following image:
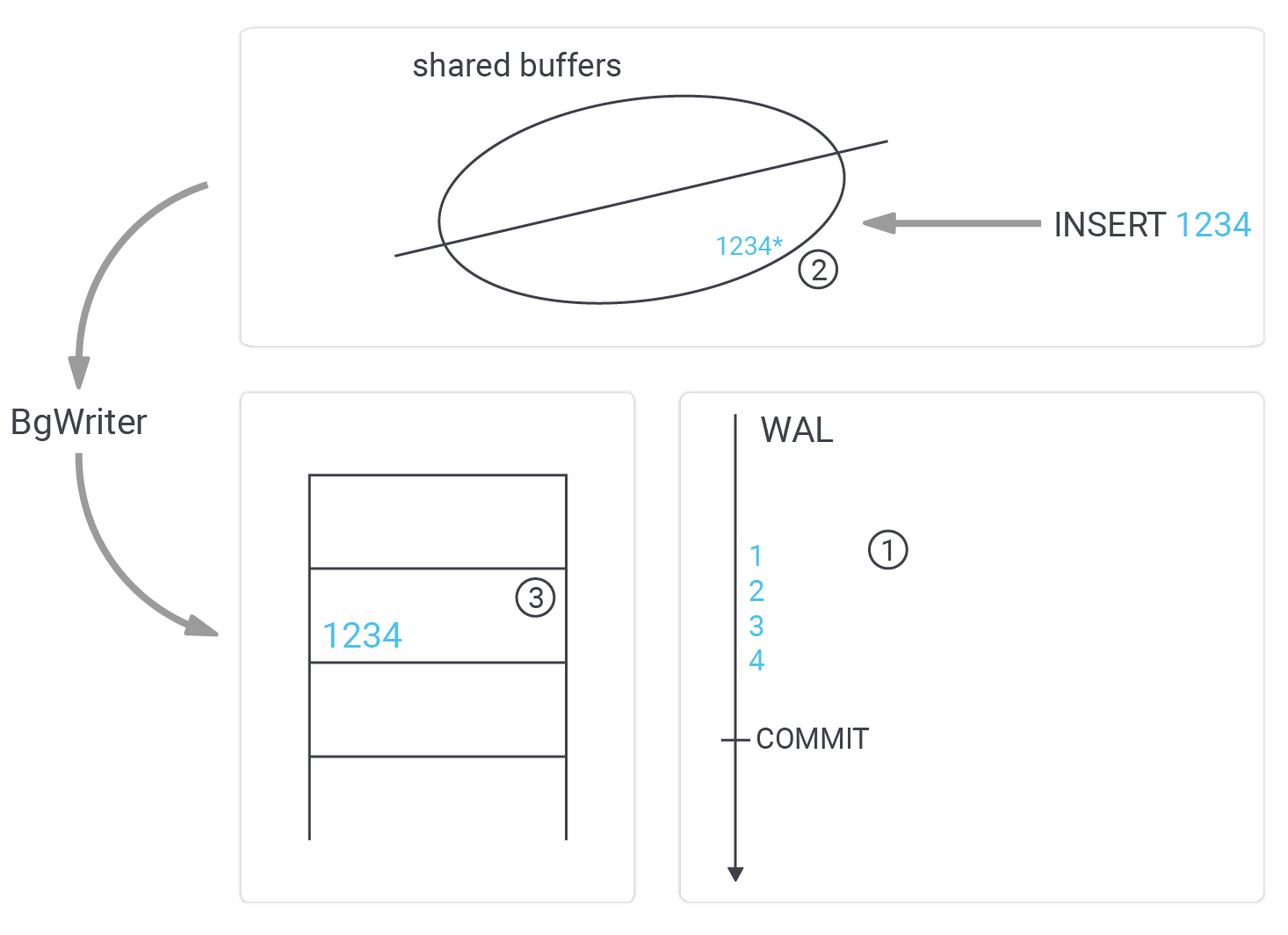
The most important thing is that we have to assume a crash could happen at any time. Why is that relevant? Well, we want to ensure that your database can never become corrupted. The consequence is that we cannot write data to the data files directly. Why is that? Suppose we wanted to write “1234” to the data file. What if we crashed after “12”? The result would be a broken row somewhere in the table. Perhaps index entries would be missing, and so on - we have to prevent that at all costs.
Therefore, a more sophisticated way to write data is necessary. How does it work? The first thing PostgreSQL does is to send data to the WAL ( = Write Ahead Log). The WAL is just like a paranoid sequential tape containing binary changes. If a row is added, the WAL might contain a record indicating that a row in a data file has to be changed, it might contain a couple of instructions to change the index entries, maybe an additional block has to be written and so on. It simply contains a stream of changes.
Once data is sent to the WAL, PostgreSQL will make changes to the cached version of a block in shared buffers. Note that data is still not in the datafiles. We now have got WAL entries as well as changes made to the shared buffers. If a read request comes in, it will not make it to the data files anyway - because the data is found in the cache.
At some point, those modified in-memory pages are written to disk by the background writer. The important thing here is that data might be written out of order, which is no problem. Bear in mind that if a user wants to read data, PostgreSQL will check shared buffers before asking the operating system for the block. The order in which dirty blocks are written is therefore not so relevant. It even makes sense to write data a bit later, to increase the odds of sending many changes to disk in a single I/O request.
However, we cannot write data to the WAL indefinitely. At some point, space has to be recycled. This is exactly what a checkpoint is good for.
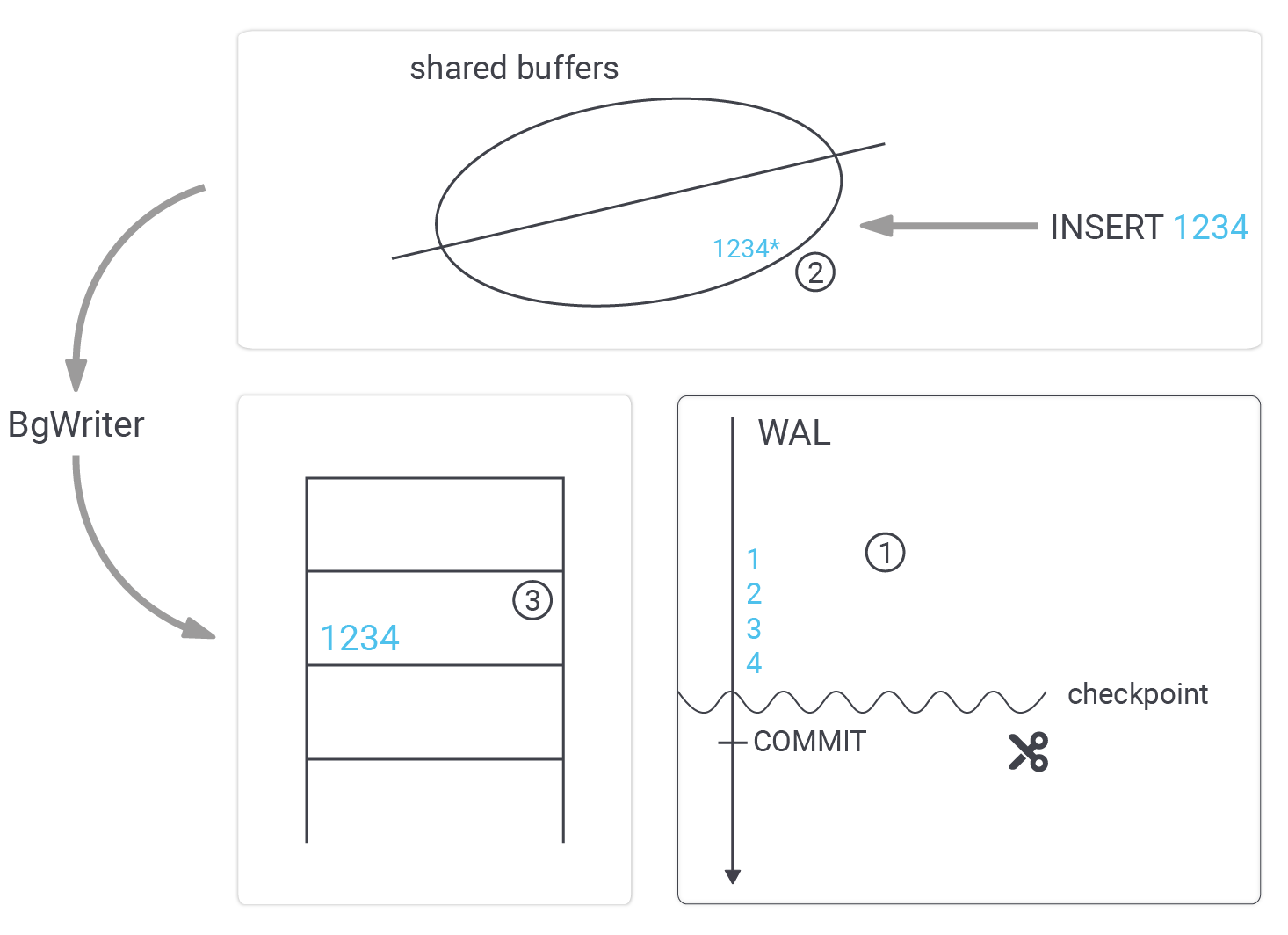
The purpose of a checkpoint is to ensure that all the dirty buffers created up to a certain point are sent to disk so that the WAL up to that point can be recycled. The way PostgreSQL does that is by launching a checkpointer process which writes those missing changes to the disk. However, this process does not send data to disk as fast as possible. The reason is that we want to flatten out the I/O curve to guarantee stable response times.
The parameter to control spreading the checkpoint is …
|
1 2 3 4 5 |
test=# SHOW checkpoint_completion_target; checkpoint_completion_target ------------------------------ 0.5 (1 row) |
The idea is that a checkpoint is finished halfway before the next checkpoint is expected to kick in. In real life, a value of 0.7 - 0.9 seems to be the best choice for most workloads, but feel free to experiment a bit.
NOTE: In PostgreSQL 14 this parameter will most likely not exist anymore. The hardcoded value will be 0.9 which will make it easier for end users.
The next important question is: When does a checkpoint actually kick in? There are some parameters to control this behavior:
|
1 2 3 4 5 |
test=# SHOW checkpoint_timeout; checkpoint_timeout -------------------- 5min (1 row) |
|
1 2 3 4 5 |
test=# SHOW max_wal_size; max_wal_size -------------- 1GB (1 row) |
If the load on your system is low, checkpoints happen after a certain amount of time. The default value is 5 minutes. However, we recommend increasing this value to optimize write performance.
NOTE: Feel free to change these values. They impact performance but they will NOT endanger your data in any way. Apart from performance, no data will be at risk.
max_wal_size is a bit more tricky: first of all, this is a soft limit - not a hard limit. So, be prepared. The amount of WAL can exceed this number. The idea of the parameter is to tell PostgreSQL how much WAL it might accumulate, and adjust checkpoints accordingly. The general rule is: increasing this value will lead to more space consumption, but improve write performance at the same time.
So why not just set max_wal_size to infinity? The first reason is obvious: you will need a lot of space. However, there is more-- in case your database crashes, PostgreSQL has to repeat all changes since the last checkpoint. In other words, after a crash, your database might take longer to recover - due to insanely large amounts of WAL accrued since the last checkpoint. On the up side, performance does improve if checkpoint distances are increased - however, there is a limit to what can be done and achieved. At some point, throwing more storage at the problem does not change anything anymore.
The background writer writes some dirty blocks to the disk. However, in many cases a lot more work is done by the checkpoint process itself. It therefore makes sense to focus more on checkpointing than on optimizing the background writer.
People (from training sessions, or PostgreSQL 24x7 support clients) often ask about the meaning of min_wal_size and max_wal_size. There is a lot of confusion out there regarding these two parameters. Let me try to explain what is going on here. As stated before, PostgreSQL adjusts its checkpoint distances on its own. It tries to keep the WAL below max_wal_size. However, if your system is idle, PostgreSQL will gradually reduce the amount of WAL again all the way down to min_wal_size. This is not a quick process - it happens gradually, over a prolonged period of time.
Let us assume a simple scenario to illustrate the situation. Suppose you have a system that is under a heavy write load during the week, but idles on the weekend. Friday afternoon, the size of the WAL is therefore large. However, over the weekend PostgreSQL will gradually reduce the size of the WAL. When the load picks up again on Monday, those missing WAL files will be recreated (which can be an issue, performance-wise).
It might therefore be a good idea not to set min_wal_size too low (compared to max_wal_size) to reduce the need to create new WAL files when the load picks up again.
Checkpoints are an important topic and they are vital to achieving good performance. However, if you want to learn more about other vital topics, check out our article about PostgreSQL upgraded, which can be found here: Upgrading and updating PostgreSQL
Even though higher min_wal_size can improve the recycling of WAL segment files, There is a flip side to it.
after some times the old WAL segement will be out of linux page cache, that need to be reread to memory for recycling again. This can become costlier than creating a new one.