Foreign data wrappers are one of the most widely used feature in PostgreSQL. People simply like foreign data wrappers and we can expect that the community will add even more features as we speak. As far as the postgres_fdw is concerned there are some hidden tuning options which are not widely known by users. So let's see how we can speed up the PostgreSQL foreign data wrapper.
Table of Contents
To show how things can be improved we first have to create some sample data in “adb”, which can then be integrated into some other database:
|
1 2 3 4 5 |
adb=# CREATE TABLE t_local (id int); CREATE TABLE adb=# INSERT INTO t_local SELECT * FROM generate_series(1, 100000); INSERT 0 100000 |
In this case I have simply loaded 100.000 rows into a very simple table. Let us now create the foreign data wrapper (or “database link” as Oracle people would call it). The first thing to do is to enable the postgres_fdw extension in “bdb”.
|
1 2 |
bdb=# CREATE EXTENSION postgres_fdw; CREATE EXTENSION |
In the next step we have to create the “SERVER”, which points to the database containing our sample table. CREATE SERVER works like this:
|
1 2 3 4 |
bdb=# CREATE SERVER some_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'localhost', dbname 'adb'); CREATE SERVER |
Once the foreign server is created the users we need can be mapped:
|
1 2 3 4 |
bdb=# CREATE USER MAPPING FOR current_user SERVER some_server OPTIONS (user 'hs'); CREATE USER MAPPING |
In this example the user mapping is really easy. We simply want the current user to connect to the remote database as “hs” (which happens to be my superuser).
Finally, we can link the tables. The easiest way to do that is to use “IMPORT FOREIGN SCHEMA”, which simply fetches the remote data structure and turns everything into a foreign table.
|
1 2 3 4 5 6 7 8 9 |
bdb=# h IMPORT Command: IMPORT FOREIGN SCHEMA Description: import table definitions from a foreign server Syntax: IMPORT FOREIGN SCHEMA remote_schema [ { LIMIT TO | EXCEPT } ( table_name [, ...] ) ] FROM SERVER server_name INTO local_schema [ OPTIONS ( option 'value' [, ... ] ) ] |
The command is really easy and shown in the next listing:
|
1 2 3 4 |
bdb=# IMPORT FOREIGN SCHEMA public FROM SERVER some_server INTO public; IMPORT FOREIGN SCHEMA |
As you can see PostgreSQL has nicely created the schema for us and we are basically ready to go.
|
1 2 3 4 5 6 |
bdb=# d List of relations Schema | Name | Type | Owner --------+---------+---------------+------- public | t_local | foreign table | hs (1 row) |
When we query our 100.000 row table we can see that the operation can be done in roughly 7.5 milliseconds:
|
1 2 3 4 5 6 7 8 |
adb=# explain analyze SELECT * FROM t_local ; QUERY PLAN ---------------------------------------------------------------------------------- Seq Scan on t_local (cost=0.00..1443.00 rows=100000 width=4) (actual time=0.010..7.565 rows=100000 loops=1) Planning Time: 0.024 ms Execution Time: 12.774 ms (3 rows) |
Let us connect to “bdb” now and see, how long the other database needs to read the data:
|
1 2 3 4 5 6 7 8 9 |
adb=# c bdb bdb=# explain analyze SELECT * FROM t_local ; QUERY PLAN -------------------------------------------------------------------------------------- Foreign Scan on t_local (cost=100.00..197.75 rows=2925 width=4) (actual time=0.322..90.743 rows=100000 loops=1) Planning Time: 0.043 ms Execution Time: 96.425 ms (3 rows) |
In this example you can see that 90 milliseconds are burned to do the same thing. So why is that? Behind the scenes the foreign data wrapper creates a cursor and fetches data in really small chunks. By default, only 50 rows are fetched at a time. This translates to thousands of network requests. If our two database servers would be further away, things would take even longer – A LOT longer. Network latency plays a crucial role here and performance can really suffer.
One way to tackle the problem is to fetch larger chunks of data at once to reduce the impact of the network itself. ALTER SERVER will allow us to set the “fetch_size” to a large enough value to reduce network issues without increasing memory consumption too much. Here is how it works:
|
1 2 3 |
bdb=# ALTER SERVER some_server OPTIONS (fetch_size '50000'); ALTER SERVER |
Let us run the test and see, what will happen:
|
1 2 3 4 5 6 7 8 |
bdb=# explain analyze SELECT * FROM t_local; QUERY PLAN --------------------------------------------------------------------------------------- Foreign Scan on t_local (cost=100.00..197.75 rows=2925 width=4) (actual time=17.367..40.419 rows=100000 loops=1) Planning Time: 0.036 ms Execution Time: 45.910 ms (3 rows) |
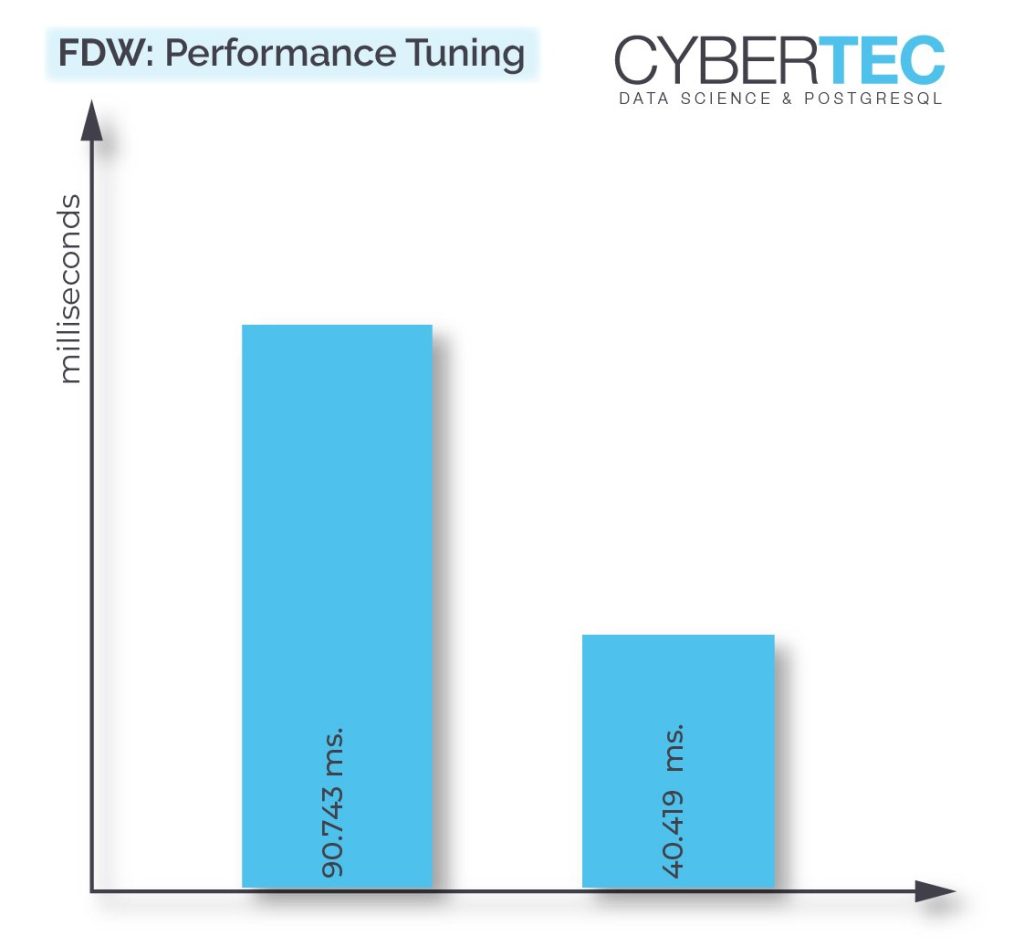
Wow, we have managed to more than double the speed of the query. Of course, the foreign data wrapper is still slower than a simple local query. However, the speedup is considerable and it definitely makes sense to toy around with the parameters to tune it.
If you want to learn more about Foreign Data Wrappers, performance and monitoring, check out one of our other blog posts.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
What a fantastic "hidden" option! Shame that it only works with
postgres_fdw& not all FDWs.It depends on the data source what is possible. For file_fdw, it would not make sense. In oracle_fdw, there is the
prefetchoption.Amazing tip! Use of big external tables joined with local tables is really slow... Do you have a better solution to access tables from other databases in same server?
That is unavoidable. To join tables that reside in different systems, you have to ship a semi-join from one to the other. If the tables are big, that is expensive.
I guess my advice is to stay away from architectures that require joining big tables on different servers frequently.
Hi Laurenz, this is great help for my team!
My question is does fetch size have a limit?
Oh and another one, I read somewhere that this fetch_size can be specified for server or foreign table. Should we do both for better performance?
Thank you!
The limit for
fetch_sizeis how much RAM you have on the client side to buffer results. But then the size of network packets is limited, so you will not gain performance beyond a certain value.It does not matter if you set it on the table or the server — setting it on the server only means that it is set on all tables that belong to that server (unless explicitly overridden on the table level).
Landed out on this page after googling for FWD chunk size. And that's it. 🙂
Thank you so much!
thank you for your feedback 🙂 share the news :). i hope your posts are useful 🙂