BY Kaarel Moppel - With the heyday of big data and people running lots of Postgres databases, sometimes one needs to join or search for data from multiple absolutely regular and independent PostgreSQL databases. (i.e., no built-in clustering extensions are in use). The goal is to present it as one logical entity. Think sales reporting aggregations over logical clusters, or matching click-stream info, with sales orders based on customer ID's.
Table of Contents
So how do you solve such ad-hoc tasks? One could of course solve it on the application level with some simple scripting, but let's say we only know SQL. Luckily PostgreSQL (plus the ecosystem) provide some options out of the box. There are also some 3rd party tools for cases when you can't use the Postgres options (no superuser rights or extensions can be installed). So let's look at the following 4 options:
Around since ever, this method might easily be the simplest way to join independent Postgres databases. Basically you just need to create the extension (requires "contrib"), declare a named connection and then use the dblink function to specify a query, including a list of output columns and their datatypes. The query will be sent over to the specified connection, and the pulled in dataset will be handled as a normal subselect - thus from thereon one could use all the functionality that Postgres has to offer! Full documentation on the extension here.
Things to note:
Pros: easiest setup possible, flexibility on connecting to X amount of Postgres DBs
Cons: SQLs could get ugly for multiple joins, possible performance issues for bigger datasets, basic transaction support
On board since 9.3, the Postgres foreign-data wrapper (postgres_fdw extension, available in "contrib") is an improvement over dblink and is well-suited for more permanent data crunching. You can even build complex sharding/scaling architectures on top of it, with the introduction of "foreign table inheritance" in 9.6. Basically what you have is a permanent "symlink / synonym" to a table/view on another database. The benefit is that the local Postgres database (where the user is connected) already has the column details on the table. Most importantly, size and data distribution statistics are included, so that it can figure out better execution plans. True, in older Postgres versions, the plans were not always too optimal. However, version 9.6 got a lot of attention in that area. NB! The FDW also supports writing/changing data and transactions! Here's the FDW full documentation.
Overview of the steps required for setup:
Pros: schema introspection, performance, allows data modifications, full transaction support
Cons: many steps needed for setup + user management
Presto is an open source distributed SQL query engine, meant to connect the most different "bigdata" datasources via SQL, thus not really Postgres-centric but DB-agnostic. Created by Facebook to juggle Terabytes of data for analytical workloads, one can expect it to handle your data amounts efficiently though. Basically it is a Java-based query parser/coordinator/worker framework, so not the most light-weight approach, but definitely worth a try even for smaller amounts of data. For bigger amounts of data it assumes nodes with a lot of RAM!
Setup might look scary at first, but it will actually only take minutes to get going as the docs are great. The process in general can be seen below. See the docs for setup details here.
|
1 2 3 4 5 6 7 8 9 |
presto:default> SELECT count(*) FROM postgres.public.t1 x INNER JOIN kala.public.t1 y ON x.c1 = y.c1; _col0 ------- 1 (1 row) Query 20170731_122315_00004_s3nte, FINISHED, 1 node Splits: 67 total, 67 done (100.00%) 0:00 [3 rows, 0B] [12 rows/s, 0B/s] |
Pros: Lot of datasources, good SQL support, good documentation, monitoring dashboard
Cons: Setup (server + client), full SQL re-implementation thus you'll lose Postgres analytic functions etc
Another "generic" solution for connecting various databases, including Postgres, via standard SQL can be performed by using the Unity "virtual datasource" plugin for the popular SQL client called SQuirreL. Actually some other SQL client can be used also, SQuirreL just seems to be well documented.
General process here is following:
Pros: relatively easy setup, user level access, many other datasources (MySQL, MSSQL, Oracle, MongoDB) supported
Cons: Commercial licence, limited to 100 result rows/2 DBs in trial mode, SQL-92 compliant thus don't expect all the fancy Postgres syntax to work
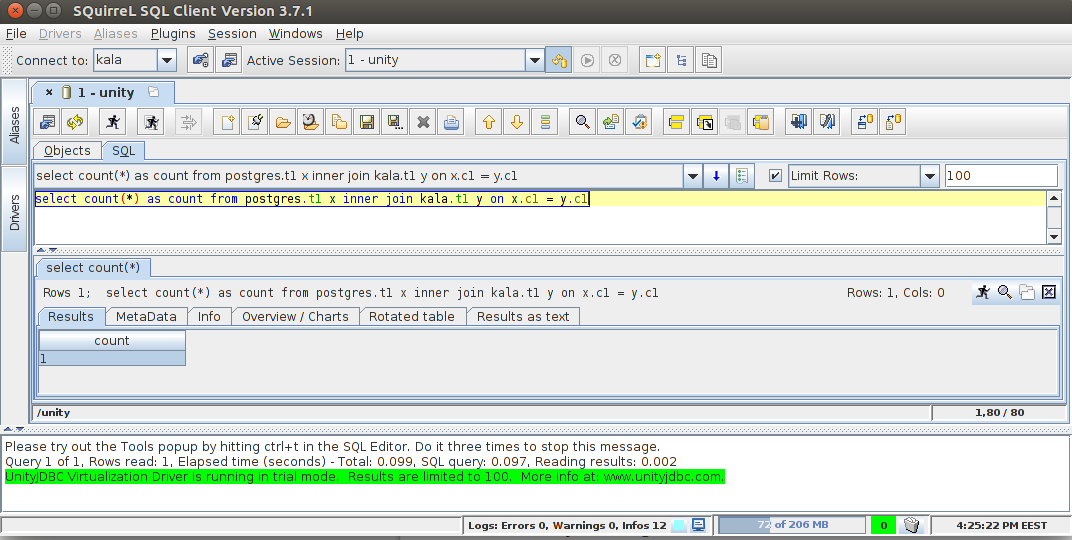
That's all. Hope you found out something new and let me know in the comments if you know some other cool approaches for ad hoc mixing of data from different Postgres databases. Thanks a lot!
In case you need any assistance with your data, feel free to contact us, we're ready to assist you.
Thank you Kaarel, this is exactly what I needed. I've been struggling with this for a while and this article was very helpful.
This is a great article, thanks so much
Excelente el artículo ! muchísimas gracias, ha sido de gran ayuda.