A lot has been said about PostgreSQL shared buffers and performance. As my new desktop box has arrived this week I decided to give it a try and see, how a simple benchmark performs, given various settings of shared_buffers.
The first thing to run the test is to come up with a simple test database. I decided to use a pgbench with a scale factor of 100. This gives a total of 10 mio rows and a database size of roughly 1.5 GB:
|
1 2 3 4 5 |
test=# select pg_size_pretty(pg_database_size('test')); pg_size_pretty ---------------- 1502 MB (1 row) |
The test box we are running on is an AMD FX-8350 (8 cores) with 16 GB of RAM and a 256 GB Samsung 840 SSD.
A simple shell script is used to conduct the test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/bin/sh PGDATA=/home/hs/db CONNS=32 T=1200 DB=test for x in 1024 4096 16384 65536 131072 262144 524288 1048576 do pg_ctl -D $PGDATA -o "-B $x" -l /dev/null start > /dev/null sleep 2 echo trying with: $x buffers pgbench -j 16 -M simple -S -T $T $DB -c $CONNS 2> /dev/null | grep tps | grep includ pgbench -j 16 -M prepared -S -T $T $DB -c $CONNS 2> /dev/null | grep tps | grep includ pg_ctl -D $PGDATA -o "$x" -m fast -l /dev/null stop > /dev/null echo done |
The goal of the test is to see if the amount of shared memory does have an impact on the performance of the system.
NOTE: In our test the benchmarking program is running on the same node sucking up around 1.5 CPU cores. So, the tests we have here can basically just use up the remaining 6.5 cores. While this does not give performance data, it is still enough to see, which impact changing the size of the shared buffers have.
Here are the results. Buffers are in 8 blocks:
| Buffers | TPS simple | TPS prepared |
| 1024 | 80529,33 | 120403,43 |
| 4096 | 80496,44 | 119709,02 |
| 16384 | 82487,12 | 124697,52 |
| 65536 | 87791,88 | 139695,82 |
| 131072 | 92086,75 | 150641,91 |
| 262144 | 94760,85 | 155698,34 |
| 524288 | 94708,02 | 155766,49 |
| 1048576 | 94676,83 | 156040,41 |
What we see is a steady increase of the database throughput roughly up to the size of the database itself. Then the curve is flattening out as expected:
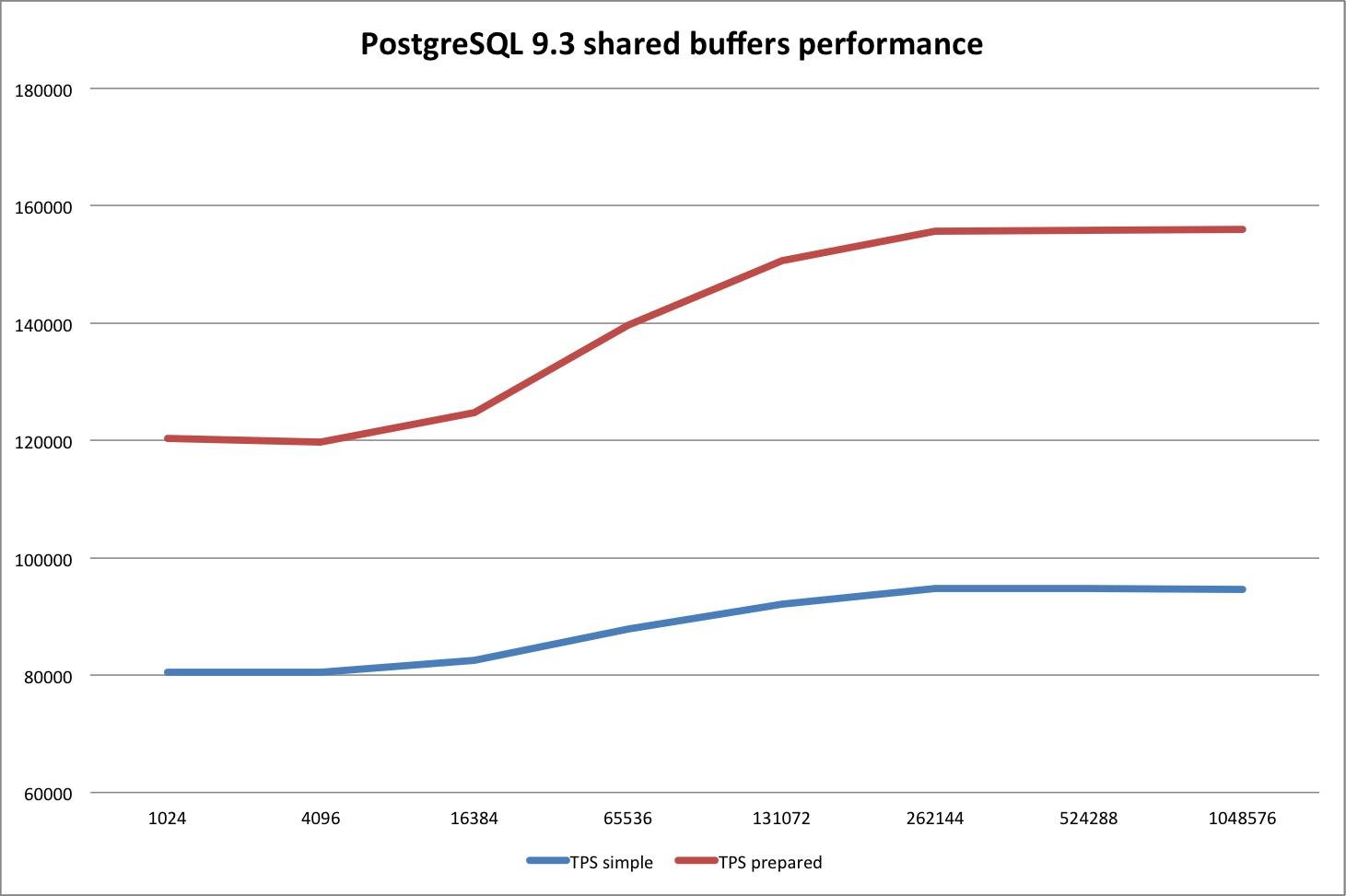
It is interesting to see that the impact of not having to ask the operating system for each and every block is actually quite significant.
The same can be said about prepared queries. Avoiding parsing does have a serious impact on performance - especially on short reading transactions. Close to 160k reads to find data in 10 mio rows is actually quite a lot given the fact that we are talking about hardware, which is ways around 1.000 euros including VAT.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
To me this is just further confirmation that we still can't use any more than 2-8G for shared_buffers. That matches what I've seen at work, where we're using 80 core machines with 512GB, yet still have to set shared_buffers to 8G.
yes, making them too large is a problem. in my case i just got 1.5GB of data so it is expected to flatten out. i should add more RAM to the box and test with a lot more data to see where we start to go south.