Over the years, many of our PostgreSQL clients have asked whether it makes sense to create indexes before - or after - importing data. Does it make sense to disable indexes when bulk loading data, or is it better to keep them enabled? This is an important question for people involved in data warehousing and large-scale data ingestion. So let’s dig in and figure it out:
Table of Contents
Before we dive into the difference in performance, we need to take a look at how B-trees in PostgreSQL are actually structured:
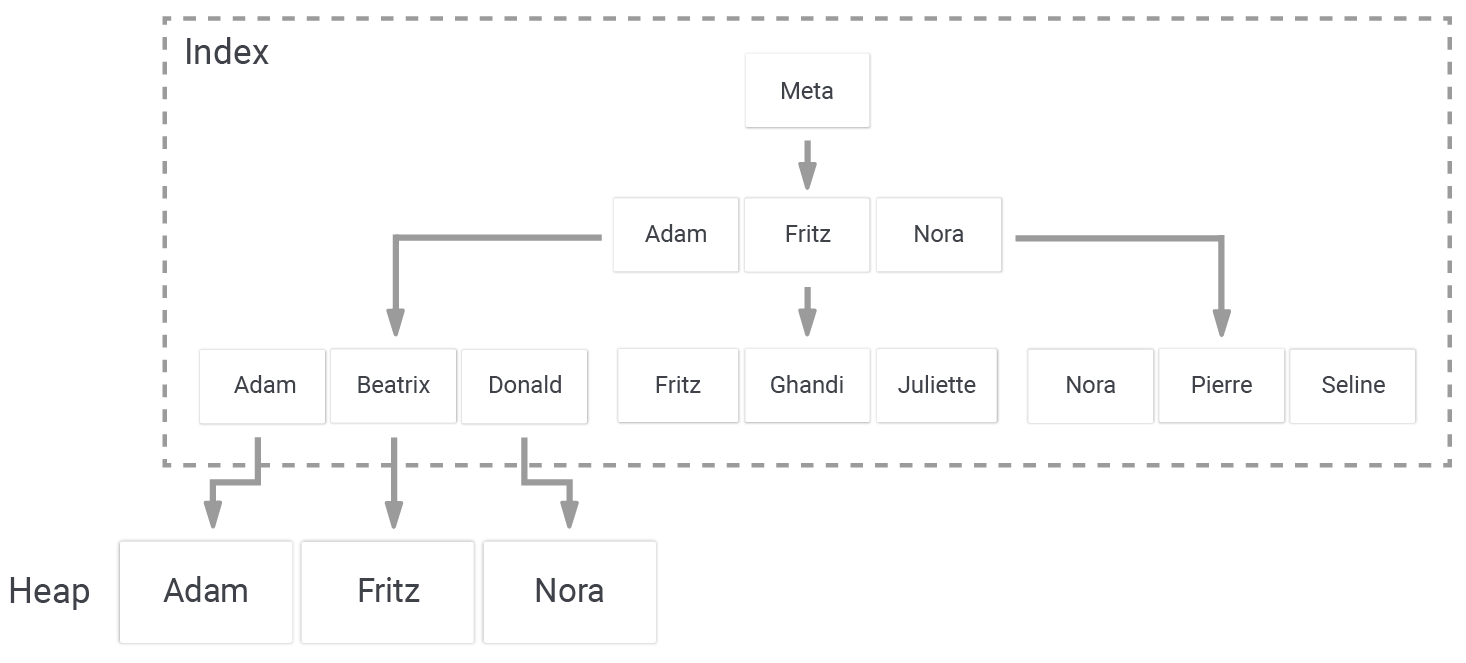
An index points to pages in the heap (= “table”). In PostgreSQL, a B-tree index always contains at least as much data as the underlying table. Inserting content into the table also means that data has to be added to the B-tree structure, which can easily turn a single change into a more expensive process. Keep in mind that this happens for each row (unless you are using partial indexes).
In reality, the additional data can pile up, resulting in a really expensive operation.
To show the difference between indexing after an import and before an import, I have created a simple test on my old Mac OS X machine. However, one can expect to see similar results on almost all other operating systems, including Linux.
Here are some results:
|
1 2 3 4 5 6 7 8 9 |
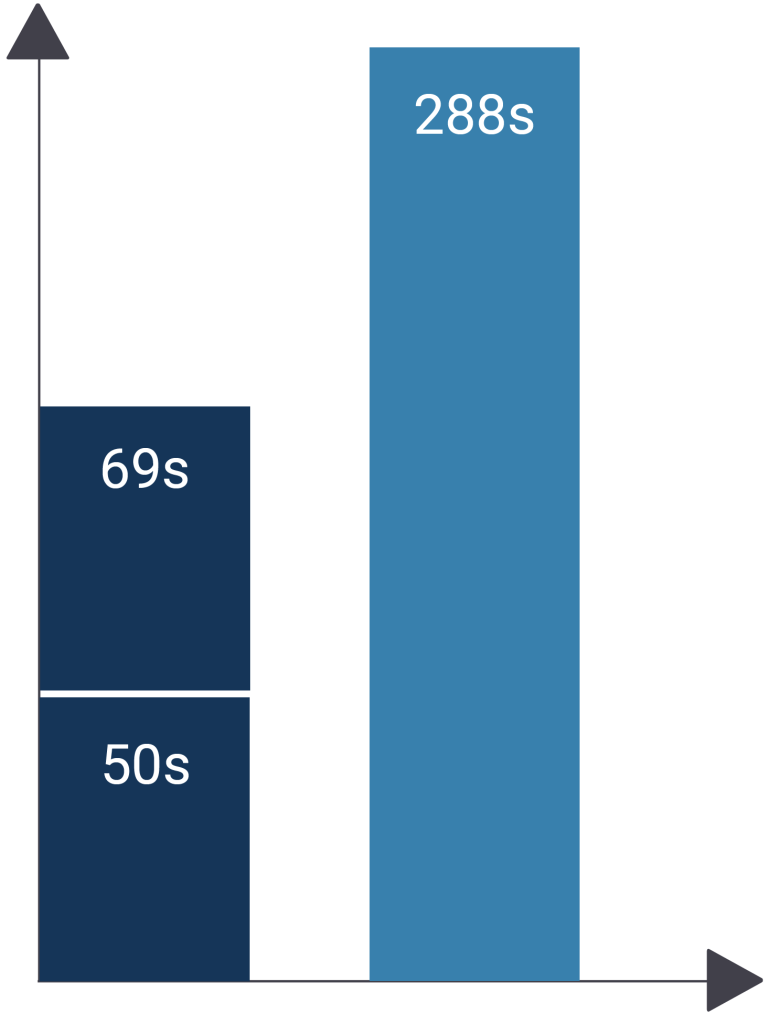
test=# CREATE TABLE t_test (id int, x numeric); CREATE TABLE test=# INSERT INTO t_test SELECT *, random() FROM generate_series(1, 10000000); INSERT 0 10000000 Time: 50249.299 ms (00:50.249) test=# CREATE INDEX idx_test_x ON t_test (x); CREATE INDEX Time: 68710.372 ms (01:08.710) |
As you can see, we need roughly 2 minutes and 50 seconds to load the data, and a little more than one minute to create the index.
But what happens if we drop the table, and create the index before loading the data?
|
1 2 3 4 5 6 7 8 9 |
test=# CREATE TABLE t_test (id int, x numeric); CREATE TABLE test=# CREATE INDEX idx_test_x ON t_test (x); CREATE INDEX Time: 11.192 ms test=# INSERT INTO t_test SELECT *, random() FROM generate_series(1, 10000000); INSERT 0 10000000 Time: 288630.970 ms (04:48.631) |
Wow, the runtime has skyrocketed to close to 5 minutes! The overhead of the additional index is relevant.
The situation can become even worse if there is more than just one index.
In general, our recommendation is therefore:
Create indexes after bulk loading!
The natural question which then arises is: What should I do if there is already data in a table, and even more data is added? In most cases, there is no other way to deal with it but to take on the overhead of the existing indexes, because in most cases, you can’t live without indexes if there is already data in the database.
A second option is to consider PostgreSQL partitioning. If you load data on a monthly basis, it might make sense to create a partition for each month, and attach it after the loading process.
In general, adding to existing data is way more critical, and not so straightforward, as creating data from scratch.
Bulk loading is an important topic and everybody has to load large amounts of data once in a while.
However, bulk loading and indexes are not the only important issues. Docker is also a growing technology that has found many friends around the world. If you want to figure out how to best run PostgreSQL in a container, check out our article about this topic.
What's wrong with scale on you chart?
It's a shame that PostgreSQL doesn't have the equivalent of Onracle's direct path loading, as the index maintenance mechanism on that can really even out the total times.
I wish PostgreSQL had the same ability to log wait events also, as direct comparisons of wall clock time often fail to show the real drivers of a delay.