Many people ask about index scans in PostgreSQL. This blog is meant to be a basic introduction to the topic. Many people aren't aware of what the optimizer does when a single query is processed. I decided to show how a table can be accessed and give examples. Let's get started with PostgreSQL indexing.
Table of Contents
Indexes are the backbone of good performance. Without proper indexing, your PostgreSQL database might be in dire straits and end users might complain about slow queries and bad response times. It therefore makes sense to see which choices PostgreSQL makes when a single column is queried.
To show you how things work we can use a table:
|
1 2 |
test=# CREATE TABLE sampletable (x numeric); CREATE TABLE |
If your table is almost empty, you will never see an index scan, because it might be too much overhead to consult an index - it is cheaper to just scan the table directly and throw away whatever rows which don't match your query.
So to demonstrate how an index actually works, we can add 10 million random rows to the table we just created before:
|
1 2 3 4 |
test=# INSERT INTO sampletable SELECT random() * 10000 FROM generate_series(1, 10000000); INSERT 0 10000000 |
Then an index is created:
|
1 2 |
test=# CREATE INDEX idx_x ON sampletable(x); CREATE INDEX |
After loading so much data, it is a good idea to create optimizer statistics in case autovacuum has not caught up yet. The PostgreSQL optimizer needs these statistics to decide on whether to use an index or not:
|
1 2 |
test=# ANALYZE ; ANALYZE |
In PostgreSQL a btree uses Lehman-Yao High-Concurrency btrees (which will be covered in more detail in a later blog).
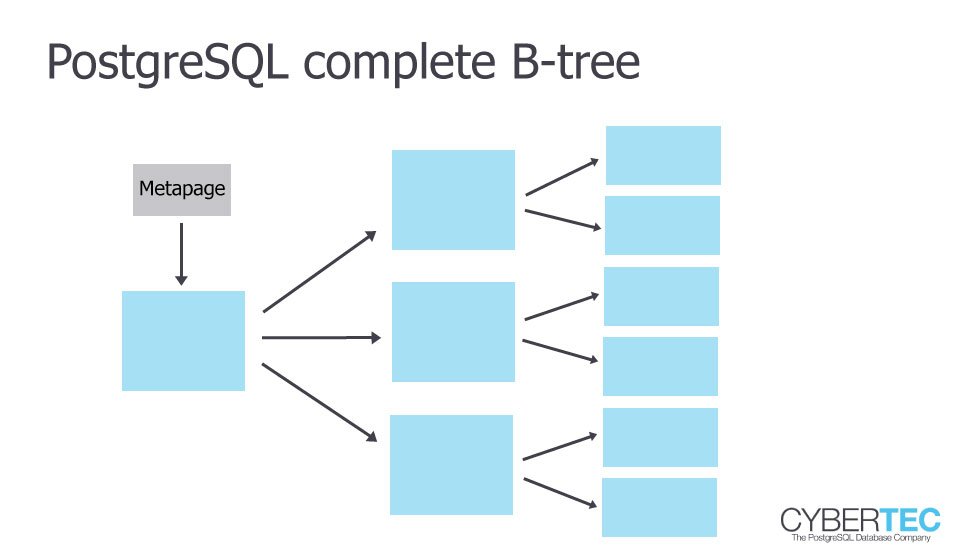
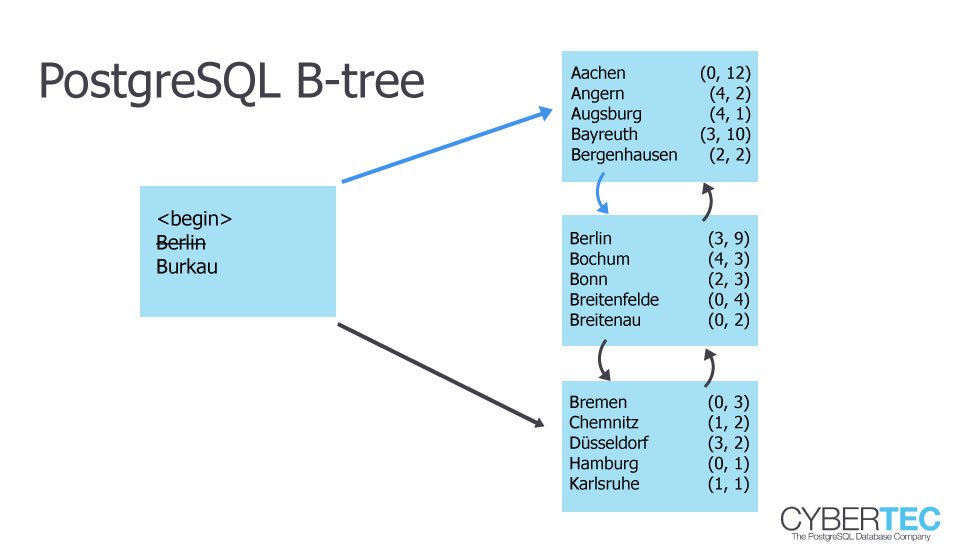
When only a small set of rows is selected, PostgreSQL can directly ask the index. In this case it can even use an “Index Only Scan” because all columns needed are actually already in the index:
|
1 2 3 4 5 6 |
test=# explain SELECT * FROM sampletable WHERE x = 42353; QUERY PLAN ----------------------------------------------------------------------- Index Only Scan using idx_x on sampletable (cost=0.43..8.45 rows=1 width=11) Index Cond: (x = '42353'::numeric) (2 rows) |
Selecting only a handful of rows will be super efficient using the index. However, if more data is selected, scanning the index AND the table will be too expensive.
However, if you select a LOT of data from a table, PostgreSQL will fall back to a sequential scan. In this case, reading the entire table and just filtering out a couple of rows is the best way to do things.
Here is how it works:
|
1 2 3 4 5 6 |
test=# explain SELECT * FROM sampletable WHERE x < 42353; QUERY PLAN --------------------------------------------------------------- Seq Scan on sampletable (cost=0.00..179054.03 rows=9999922 width=11) Filter: (x < '42353'::numeric) (2 rows) |
PostgreSQL will filter out those unnecessary rows and just return the rest. This is really the ideal thing to do in this case. A sequential scan is therefore not always bad - there are use cases where a sequential scan is actually perfect.
Still: Keep in mind that scanning large tables sequentially too often will take its toll at some point.
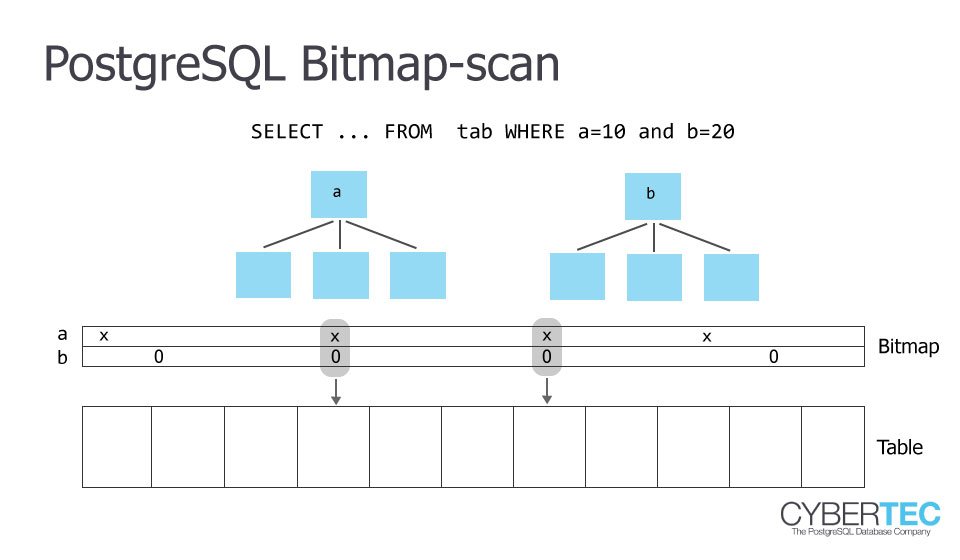
If you only select a handful of rows, PostgreSQL will decide on an index scan - if you select a majority of the rows, PostgreSQL will decide to read the table completely. But what if you read too much for an index scan to be efficient but too little for a sequential scan? The solution to the problem is to use a bitmap scan. The idea behind a bitmap scan is that a single block is only used once during a scan. It can also be very helpful if you want to use more than one index to scan a single table.
Here is what happens:
|
1 2 3 4 5 6 7 8 |
test=# explain SELECT * FROM sampletable WHERE x < 423; QUERY PLAN ---------------------------------------------------------------------------- Bitmap Heap Scan on sampletable (cost=9313.62..68396.35 rows=402218 width=11) Recheck Cond: (x < '423'::numeric) -> Bitmap Index Scan on idx_x (cost=0.00..9213.07 rows=402218 width=0) Index Cond: (x < '423'::numeric) (4 rows) |
PostgreSQL will first scan the index and compile those rows / blocks which are needed at the end of the scan. Then PostgreSQL will take this list and go to the table to really fetch those rows. The beauty is that this mechanism even works if you are using more than just one index.
Bitmaps scans are therefore a wonderful contribution to performance.
Read more about how foreign key indexing affects performance, and how to find missing indexes in Laurenz Albe's blog.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
Nice article. Thanks.
I got confused by the below one. Can you help me?
> However, if you select a LOT of data from a table, PostgreSQL will fall back to a sequential scan.
how can Postgres know you are
selecting a LOT of databefore getting the search result?PostgreSQL estimate amount of data using statistics. That's why you need to run "ANALYZE" to update statistic after INSERT or UPDATE a large amount of data in table.
got it, thanks!
Not sure why PG would need to look at the table blocks at all if it can scan the index (which is in your example covering the only column). Why would it go through all the trouble of creating a bitmap for the data blocks and then reading those if it already had all values checked in the index?
(It also looks a bit unclear why it would prefer a sequence scan over a Index only scan for 5% rows. Would it use the index scan longer if the unread part of the rows are bigger?)
Is there a way to see how many blocks have been candidates and eliminated in a concrete query?
why isn't index works on count (*) ???
https://uploads.disquscdn.com/images/fad715371fcdc49b3f3512764474b5d487bdcd3c94de86514e8d69efcc8d95c6.png
An index cannot help much here, because all rows have to be scanned in order to count them.
If "sampletable" has many columns, and index only scan might be used, but only if the table has been VACUUMed recently, so that PostgreSQL doesn't have to perform heap fetches to determine if a row is visible or not.
thanks @laurenz it is safer to say that index is not helpful for count(*) alternatively is there any other to get faster count(*)