What does PostgreSQL Full-Text-Search have to do with VACUUM? Many readers might actually be surprised that there might be a relevant connection worth talking about at all. However, those two topics are more closely related, than people might actually think. The reason is buried deep inside the code and many people might not be aware of those issues. Therefore I've decided to shed some light on this topic and explain, what is really going on here. The goal is to help end users to speed up their Full-Text-Indexing (FTI) and offer better performance to everybody making use of PostgreSQL.
Table of Contents
Before digging into the real stuff, it is necessary to create some test data. For that purpose, I created a table. Note that I turned autovacuum off so that all operations are fully under my control. This makes it easier to demonstrate, what is going on in PostgreSQL.
|
1 2 3 |
test=# CREATE TABLE t_fti (payload tsvector) WITH (autovacuum_enabled = off); CREATE TABLE |
In the next step we can create 2 million random texts. For the sake of simplicity, I did not import a real data set containing real texts but simply created a set of md5 hashes, which are absolutely good enough for the job:
|
1 2 3 4 |
test=# INSERT INTO t_fti SELECT to_tsvector('english', md5('dummy' || id)) FROM generate_series(1, 2000000) AS id; INSERT 0 2000000 |
Here is what our data looks like:
|
1 2 3 4 5 6 7 8 9 10 |
test=# SELECT to_tsvector('english', md5('dummy' || id)) FROM generate_series(1, 5) AS id; to_tsvector -------------------------------------- '8c2753548775b4161e531c323ea24c08':1 'c0c40e7a94eea7e2c238b75273087710':1 'ffdc12d8d601ae40f258acf3d6e7e1fb':1 'abc5fc01b06bef661bbd671bde23aa39':1 '20b70cebcb94b1c9ba30d17ab542a6dc':1 (5 rows) |
To make things more efficient, I decided to use the tsvector data type in the table directly. The advantage is that we can directly create a full text index (FTI) on the column:
|
1 2 3 |
test=# CREATE INDEX idx_fti ON t_fti USING gin(payload); CREATE INDEX |
In PostgreSQL, a GIN index is usually used to take care of “full text search” (FTS).
Finally we run VACUUM to create all those hint bits and make PostgreSQL calculate optimizer statistics.
|
1 2 |
test=# VACUUM ANALYZE ; VACUUM |
To understand what VACUUM and Full Text Search (FTS) have to do with each other, we first got to see, how GIN indexes actually work: A GIN index is basically a “normal tree” down to the word level. So you can just binary search to find a word easily. However: In contrast to a btree, GIN has a “posting tree” below the word level. So each word only shows up once in the index but points to a potentially large list of entries. For full text search this makes sense because the number of distinct words is limited in real life while a single word might actually show up thousands of times.
The following image shows, what a GIN index looks like:
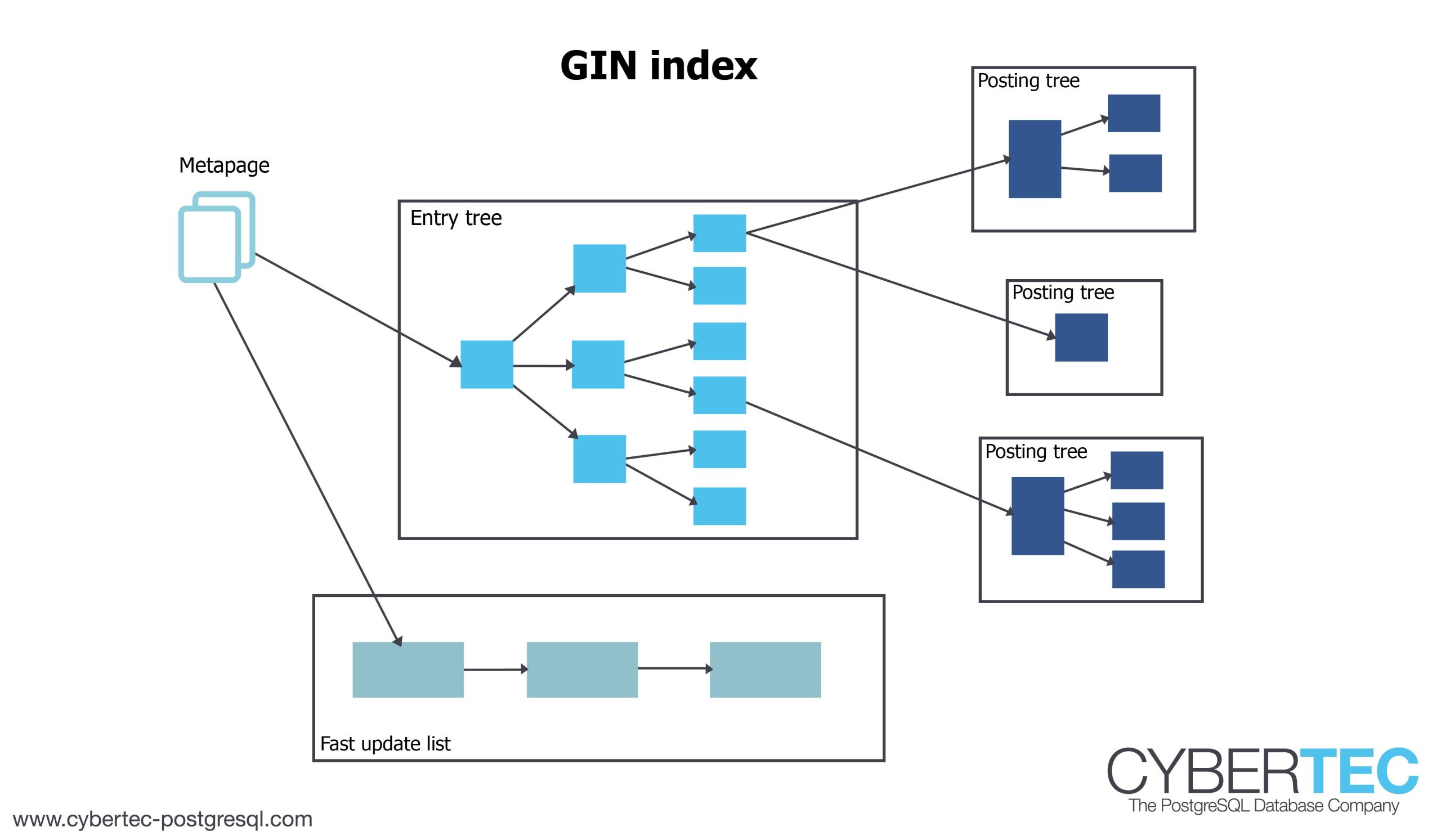
Let us take a closer look at the posting tree itself: It has one entry for pointer to the underlying table. To make it efficient, the posting tree is sorted. The trouble now is: If you insert into the table, changing the GIN index for each row is pretty expensive. Modifying the posting tree does not come for free. Remember: You have to maintain the right order in your posting tree so changing things comes with some serious overhead.
Fortunately there is a solution to the problem: The “GIN pending list”. When a row is added, it does not go to the main index directly. But instead it is added to a “TODO” list, which is then processed by VACUUM. So after a row is inserted, the index is not really in its final state. What does that mean? It means that when you scan the index, you have to scan the tree AND sequentially read what is still in the pending list. In other words: If the pending list is long, this will have some impact on performance. In many cases it can therefore make sense to vacuum a table used to full text search more aggressively as usual. Remember: VACUUM will process all the entries in the pending list.
To see what is going on behind the scenes, install pgstattuple:
|
1 |
CREATE EXTENSION pgstattuple; |
With pgstattuple you can take a look at the internals of the index:
|
1 2 3 4 5 |
test=# SELECT * FROM pgstatginindex('idx_fti'); version | pending_pages | pending_tuples ---------+---------------+---------------- 2 | 0 | 0 (1 row) |
In this case the pending list is empty. In addition to that the index is also pretty small:
|
1 2 3 4 5 |
test=# SELECT pg_relation_size('idx_gin'); pg_relation_size ------------------ 188416 (1 row) |
Keep in mind: We had 2 million entries and the index is still close to nothing compared to the size of the table:
|
1 2 3 4 5 |
test=# SELECT pg_relation_size('t_fti'); pg_relation_size ------------------ 154329088 (1 row) |
Let us run a simple query now. We are looking for a word, which does not exist. Note that the query needs ways less than 1 millisecond:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
test=# explain (analyze, buffers) SELECT * FROM t_fti WHERE payload @@ to_tsquery('whatever'); QUERY PLAN -------------------------------------------------------------------- Bitmap Heap Scan on t_fti (cost=20.77..294.37 rows=67 width=45) (actual time=0.030..0.030 rows=0 loops=1) Recheck Cond: (payload @@ to_tsquery('whatever'::text)) Buffers: shared hit=5 -> Bitmap Index Scan on idx_fti (cost=0.00..20.75 rows=67 width=0) (actual time=0.028..0.028 rows=0 loops=1) Index Cond: (payload @@ to_tsquery('whatever'::text)) Buffers: shared hit=5 Planning time: 0.148 ms Execution time: 0.066 ms (8 rows) |
I would also like to point you to something else: “shared hit = 5”. The query only needed 5 blocks of data to run. This is really really good because even if the query has to go to disk, it will still return within a reasonable amount of time.
Let us add more data. Note that autovacuum is off so there are no hidden operations going on:
|
1 2 3 4 |
test=# INSERT INTO t_fti SELECT to_tsvector('english', md5('dummy' || id)) FROM generate_series(2000001, 3000000) AS id; INSERT 0 1000000 |
The same query, which performanced so nicely before, is now a lot slower:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
test=# explain (analyze, buffers) SELECT * FROM t_fti WHERE payload @@ to_tsquery('whatever'); QUERY PLAN -------------------------------------------------------------------- Bitmap Heap Scan on t_fti (cost=1329.02..1737.43 rows=100 width=45) (actual time=9.377..9.377 rows=0 loops=1) Recheck Cond: (payload @@ to_tsquery('whatever'::text)) Buffers: shared hit=331 -> Bitmap Index Scan on idx_fti (cost=0.00..1329.00 rows=100 width=0) (actual time=9.374..9.374 rows=0 loops=1) Index Cond: (payload @@ to_tsquery('whatever'::text)) Buffers: shared hit=331 Planning time: 0.194 ms Execution time: 9.420 ms (8 rows) |
PostgreSQL needs more than 9 milliseconds to run the query. The reason is that there are many pending tuples in the pending list. Also: The query had to access 331 pages in this case, which is A LOT more than before. The GIN pending list reveals the underlying problem:
|
1 2 3 4 5 |
test=# SELECT * FROM pgstatginindex('idx_fti'); version | pending_pages | pending_tuples ---------+---------------+---------------- 2 | 326 | 50141 (1 row) |
5 pages + 326 pages = 331 pages. The pending list explains all the additional use of data pages instantly.
Moving those pending entries to the real index is simple. We simply run VACUUM ANALYZE again:
|
1 2 |
test=# VACUUM ANALYZE; VACUUM |
As you can see the pending list is now empty:
|
1 2 3 4 5 |
test=# SELECT * FROM pgstatginindex('idx_fti'); version | pending_pages | pending_tuples ---------+---------------+---------------- 2 | 0 | 0 (1 row) |
The important part is that the query is also a lot slower again because the number of blocks has decreased again.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
test=# explain (analyze, buffers) SELECT * FROM t_fti WHERE payload @@ to_tsquery('whatever'); QUERY PLAN ----------------------------------------------------------------- Bitmap Heap Scan on t_fti (cost=25.03..433.43 rows=100 width=45) (actual time=0.033..0.033 rows=0 loops=1) Recheck Cond: (payload @@ to_tsquery('whatever'::text)) Buffers: shared hit=5 -> Bitmap Index Scan on idx_fti (cost=0.00..25.00 rows=100 width=0) (actual time=0.030..0.030 rows=0 loops=1) Index Cond: (payload @@ to_tsquery('whatever'::text)) Buffers: shared hit=5 Planning time: 0.240 ms Execution time: 0.075 ms (8 rows) |
I think those examples show pretty conclusively that VACUUM does have a serious impact on the performance of your full text indexing. Of course this is only true if a significant part of your data is changed on a regular basis.
Minor typo... Think that should be "faster" ...
"
Important part is that the query is also a lot slower again because the number of blocks has decreased again.
"
Yeah that had me scratching my head
And what about gin_pending_list_limit parameter?
Nice explanation.
There's another way to clean the pending list, you can use the "gin_clean_pending_list" function as well, which might be lighter than VACUUM under some circumstances.
Cheers,
More than that, this pending list do some checkout from time to time and can cause huge IO spike on a single random insert. It's very hard to predict what vacuum rate is sufficient enough. But you have an option to deal with it – just disable the usage of this pending list with
fastupdate=offoption. https://www.postgresql.org/docs/current/static/gin-implementation.htmlIn our installation, we haven't noticed any INSERT performance impact but IO spikes has gone forever. The same would be with your SELECTs