written by Granthana Biswas
pgBackRest is an open source backup tool for PostgreSQL which offers easy configuration and reliable backups. So if you want to protect your database and create backups easily, pgBackRest is a good solution to make that happen. In this blog, we are going to go through the basic steps of using pgBackRest for full and differential backup of PostgreSQL.
Some of the key features of pgBackRest are:
To read about them more in detail, please visit pgbackrest.org.
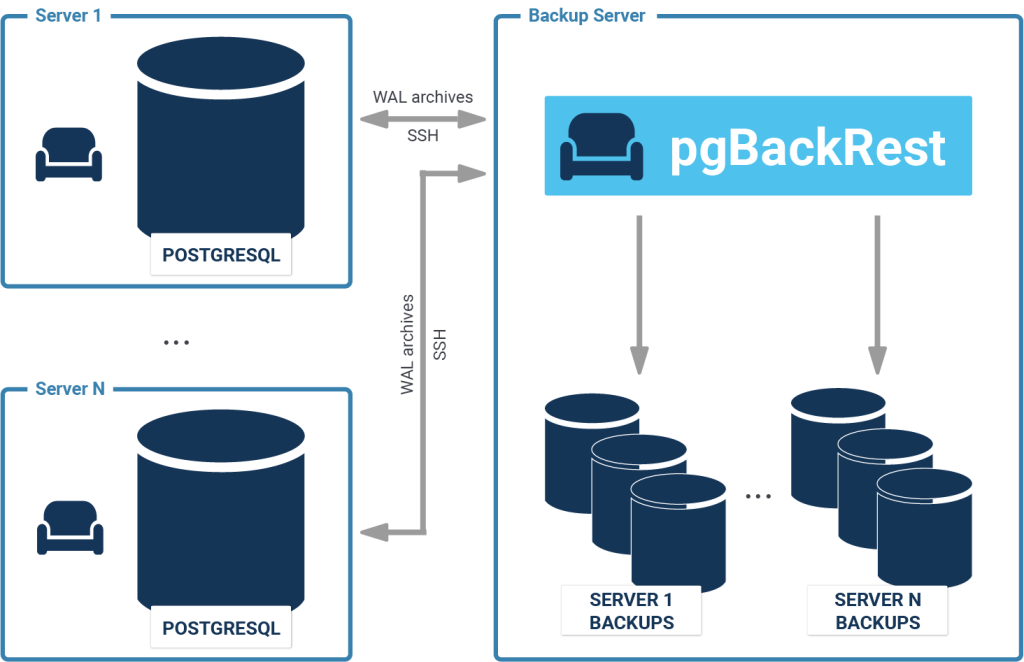
Here, we are going to build pgBackRest from the source and install it on the host where a test DB cluster is running.
Installing from Debian / Ubuntu packages:
|
1 |
sudo apt-get install pgbackrest |
For manual installation, download the source on a build host. Please avoid building the source on a production server, as the tools required should not be installed on a production machine:
|
1 2 3 |
sudo wget -q -O - https://github.com/pgbackrest/pgbackrest/archive/release/2.14.tar.gz | sudo tar zx -C /root |
|
1 2 3 |
sudo apt-get install build-essential libssl-dev libxml2-dev libperl-dev zlib1g-dev perl -V | grep USE_64_BIT_INT |
|
1 2 |
(cd /root/pgbackrest-release-2.14/src && ./configure) make -s -C /root/pgbackrest-release-2.14/src |
|
1 2 |
sudo scp BUILD_HOST:/root/pgbackrest-release-2.14/src/pgbackrest /usr/bin/ sudo chmod 755 /usr/bin/pgbackrest |
|
1 |
sudo apt-get install libdbd-pg-perl |
|
1 2 3 4 5 6 7 |
sudo mkdir -p -m 770 /var/log/pgbackrest sudo chown postgres:postgres /var/log/pgbackrest sudo mkdir -p /etc/pgbackrest sudo mkdir -p /etc/pgbackrest/conf.d sudo touch /etc/pgbackrest/pgbackrest.conf sudo chmod 640 /etc/pgbackrest/pgbackrest.conf sudo chown postgres:postgres /etc/pgbackrest/pgbackrest.conf |
|
1 2 3 |
sudo mkdir -p /var/lib/pgbackrest sudo chmod 750 /var/lib/pgbackrest sudo chown postgres:postgres /var/lib/pgbackrest |
|
1 |
cat /etc/pgbackrest/pgbackrest.conf |
[demo]
pg1-path=/data/postgres/pgdata/data1
[global]
repo1-path=/var/lib/pgbackrest
Change the following parameters in postgresql.conf:
|
1 2 3 4 5 6 |
archive_command = 'pgbackrest --stanza=demo archive-push %p' archive_mode = on listen_addresses = '*' log_line_prefix = '' max_wal_senders = 3 wal_level = replica |
postgres user:The stanza-create command must be run on the host where the repository is located to initialize the stanza. It is recommended that the check command be run after stanza-create to ensure archiving and backups are properly configured.
|
1 2 3 4 5 6 7 8 |
$ pgbackrest --stanza=demo --log-level-console=info stanza-create 2019-07-03 12:26:40.060 P00 INFO: stanza-create command begin 2.14: --log-level-console=info --pg1-path=/data/postgres/pgdata/data1 --repo1-path=/var/lib/pgbackrest --stanza=demo 2019-07-03 12:26:40.494 P00 INFO: stanza-create command end: completed successfully (435ms) $ pgbackrest --stanza=demo --log-level-console=info check 2019-07-03 12:27:11.996 P00 INFO: check command begin 2.14: --log-level-console=info --pg1-path=/data/postgres/pgdata/data1 --repo1-path=/var/lib/pgbackrest --stanza=demo 2019-07-03 12:27:13.386 P00 INFO: WAL segment 000000010000000000000003 successfully stored in the archive at '/var/lib/pgbackrest/archive/demo/10-1/0000000100000000/000000010000000000000003-b346d07d4b31e54e31d9204204816cde3cfcca3a.gz' 2019-07-03 12:27:13.387 P00 INFO: check command end: completed successfully (1392ms) |
info command to get information about the backupSince we haven't made any backups yet, we will get the following result:
|
1 2 3 4 5 6 |
$ pgbackrest info stanza: demo status: error (no valid backups) cipher: none db (current) wal archive min/max (10-1): 000000010000000000000001/000000010000000000000003 |
Let's make the first backup. By default, it will be full even if we specify type as differential:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ pgbackrest --stanza=demo --log-level-console=info backup 2019-07-03 12:37:38.366 P00 INFO: backup command begin 2.14: --log-level-console=info --pg1-path=/data/postgres/pgdata/data1 --repo1-path=/var/lib/pgbackrest --repo1-retention-full=2 --stanza=demo WARN: no prior backup exists, incr backup has been changed to full 2019-07-03 12:37:39.200 P00 INFO: execute non-exclusive pg_start_backup() with label 'pgBackRest backup started at 2019-07-03 12:37:38': backup begins after the next regular checkpoint completes 2019-07-03 12:37:39.500 P00 INFO: backup start archive = 000000010000000000000005, lsn = 0/5000028 . . . 2019-07-03 12:37:45.212 P00 INFO: full backup size = 22.5MB 2019-07-03 12:37:45.212 P00 INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive 2019-07-03 12:37:45.313 P00 INFO: backup stop archive = 000000010000000000000005, lsn = 0/5000130 2019-07-03 12:37:45.558 P00 INFO: new backup label = 20190703-123738F 2019-07-03 12:37:45.586 P00 INFO: backup command end: completed successfully (7221ms) 2019-07-03 12:37:45.586 P00 INFO: expire command begin 2019-07-03 12:37:45.594 P00 INFO: full backup total < 2 - using oldest full backup for 10-1 archive retention 2019-07-03 12:37:45.596 P00 INFO: expire command end: completed successfully (10ms) |
Now when we run the info command again:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ pgbackrest info stanza: demo status: ok cipher: none db (current) wal archive min/max (10-1): 000000010000000000000005/000000010000000000000005 full backup: 20190703-123738F timestamp start/stop: 2019-07-03 12:37:38 / 2019-07-03 12:37:45 wal start/stop: 000000010000000000000005 / 000000010000000000000005 database size: 22.6MB, backup size: 22.6MB repository size: 2.7MB, repository backup size: 2.7MB |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
$ pgbackrest --stanza=demo --log-level-console=info --type=diff backup 2019-07-03 12:40:05.749 P00 INFO: backup command begin 2.14: --log-level-console=info --pg1-path=/data/postgres/pgdata/data1 --repo1-path=/var/lib/pgbackrest --repo1-retention-full=2 --stanza=demo --type=diff 2019-07-03 12:40:05.951 P00 INFO: last backup label = 20190703-123738F, version = 2.14 2019-07-03 12:40:06.657 P00 INFO: execute non-exclusive pg_start_backup() with label 'pgBackRest backup started at 2019-07-03 12:40:05': backup begins after the next regular checkpoint completes 2019-07-03 12:40:06.958 P00 INFO: backup start archive = 000000010000000000000007, lsn = 0/7000028 2019-07-03 12:40:08.414 P01 INFO: backup file /data/postgres/pgdata/data1/global/pg_control (8KB, 99%) checksum c8b3635ef4701b19bff56fcd5ca33d41eaf3ce5b 2019-07-03 12:40:08.421 P01 INFO: backup file /data/postgres/pgdata/data1/pg_logical/replorigin_checkpoint (8B, 100%) checksum 347fc8f2df71bd4436e38bd1516ccd7ea0d46532 2019-07-03 12:40:08.439 P00 INFO: diff backup size = 8KB 2019-07-03 12:40:08.439 P00 INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive 2019-07-03 12:40:08.540 P00 INFO: backup stop archive = 000000010000000000000007, lsn = 0/70000F8 2019-07-03 12:40:08.843 P00 INFO: new backup label = 20190703-123738F_20190703-124005D 2019-07-03 12:40:08.938 P00 INFO: backup command end: completed successfully (3189ms) 2019-07-03 12:40:08.938 P00 INFO: expire command begin 2019-07-03 12:40:08.949 P00 INFO: full backup total < 2 - using oldest full backup for 10-1 archive retention 2019-07-03 12:40:08.951 P00 INFO: expire command end: completed successfully (13ms) |
info:|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
$ pgbackrest info stanza: demo status: error (no valid backups) cipher: none db (current) wal archive min/max (10-1): 000000010000000000000001/000000010000000000000003 full backup: 20190703-123738F timestamp start/stop: 2019-07-03 12:37:38 / 2019-07-03 12:37:45 wal start/stop: 000000010000000000000005 / 000000010000000000000005 database size: 22.6MB, backup size: 22.6MB repository size: 2.7MB, repository backup size: 2.7MB diff backup: 20190703-123738F_20190703-124005D timestamp start/stop: 2019-07-03 12:40:05 / 2019-07-03 12:40:08 wal start/stop: 000000010000000000000007 / 000000010000000000000007 database size: 22.6MB, backup size: 8.2KB repository size: 2.7MB, repository backup size: 468B backup reference list: 20190703-123738F |
If you want to learn more about how to protect data, check out my blog on PostgreSQL TDE ("Transparent Data Encryption") .
Also if you want to make sure that your database performs well, check out our blog posts on PostgreSQL performance.
Row Level Security (RLS) is one of the key features in PostgreSQL. It can be used to dramatically improve security and help to protect data in all cases. However, there are a couple of corner cases which most people are not aware of. So if you are running PostgreSQL and you happen to use RLS in a high-security environment, this might be the most important piece of text about database security you have ever read.
To prepare for my examples let me create some data first. The following code is executed as superuser:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE USER bob NOSUPERUSER; CREATE USER alice NOSUPERUSER; CREATE TABLE t_service (service_type text, service text); INSERT INTO t_service VALUES ('open_source', 'PostgreSQL consulting'), ('open_source', 'PostgreSQL training'), ('open_source', 'PostgreSQL 24x7 support'), ('closed_source', 'Oracle tuning'), ('closed_source', 'Oracle license management'), ('closed_source', 'IBM DB2 training'); GRANT ALL ON SCHEMA PUBLIC TO bob, alice; GRANT ALL ON TABLE t_service TO bob, alice; |
For the sake of simplicity there are only three users: postgres, bob, and alice. The t_service table contains six different services. Some are related to PostgreSQL and some to Oracle. The goal is to ensure that bob is only allowed to see Open Source stuff while alice is mostly an Oracle girl.
While hacking up the example, we want to see who we are and which chunks of code are executed as which user at all times. Therefore I have written a debug function which just throws out a message and returns true:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE FUNCTION debug_me(text) RETURNS boolean AS $ BEGIN RAISE NOTICE 'called as session_user=%, current_user=% for '%' ', session_user, current_user, $1; RETURN true; END; $ LANGUAGE 'plpgsql'; GRANT ALL ON FUNCTION debug_me TO bob, alice; |
Now that the infrastructure is in place, RLS can be enabled for this table:
|
1 |
ALTER TABLE t_service ENABLE ROW LEVEL SECURITY; |
The superuser is not able to see all the data. Normal users are not allowed to see anything. To them, the table will appear to be empty.
Of course, people want to see data. In order to expose data to people, policies have to be created. In my example there will be two policies:
|
1 2 3 4 5 6 7 8 9 |
CREATE POLICY bob_pol ON t_service FOR SELECT TO bob USING (debug_me(service) AND service_type = 'open_source'); CREATE POLICY alice_pol ON t_service FOR SELECT TO alice USING (debug_me(service) AND service_type = 'closed_source'); |
What we see here is that bob is really the Open Source guy while alice is more on the Oracle side. I added the debug_me function to the policy so that you can see which users are active.
Let us set the current role to bob and run a simple SELECT statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SET ROLE bob; SET test=> SELECT * FROM t_service; psql: NOTICE: called as session_user=hs, current_user=bob for 'PostgreSQL consulting' psql: NOTICE: called as session_user=hs, current_user=bob for 'PostgreSQL training' psql: NOTICE: called as session_user=hs, current_user=bob for 'PostgreSQL 24x7 support' service_type | service --------------+------------------------- open_source | PostgreSQL consulting open_source | PostgreSQL training open_source | PostgreSQL 24x7 support (3 rows) |
The policy does exactly what you would expect for bob. The same thing is true for alice:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=> SET ROLE alice; SET test=> SELECT * FROM t_service; psql: NOTICE: called as session_user=hs, current_user=alice for 'Oracle tuning' psql: NOTICE: called as session_user=hs, current_user=alice for 'Oracle license management' psql: NOTICE: called as session_user=hs, current_user=alice for 'IBM DB2 training' service_type | service ---------------+--------------------------- closed_source | Oracle tuning closed_source | Oracle license management closed_source | IBM DB2 training (3 rows) |
As a PostgreSQL consultant and PostgreSQL support company there is one specific question which keeps coming to us again and again: What happens if RLS (Row Level Security) is used in combination with views? This kind of question is not as easy to answer as some people might think. Expect some corner cases which require a little bit of thinking to get stuff right.
To show how things work, I will switch back to user “postgres” and create two identical views:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
test=> SET ROLE postgres; SET test=# CREATE VIEW v1 AS SELECT *, session_user, current_user FROM t_service; CREATE VIEW test=# CREATE VIEW v2 AS SELECT *, session_user, current_user FROM t_service; CREATE VIEW test=# GRANT SELECT ON v1 TO bob, alice; GRANT test=# ALTER VIEW v2 OWNER TO alice; ALTER VIEW test=# GRANT SELECT ON v2 TO bob; GRANT |
SELECT permissions will be granted to both views, but there is one more difference: alice will be the owner of v2. v1 is owned by the postgres user. This tiny difference makes a major difference later on, as you will see. To sum it up: v1 will be owned by postgres, v2 is owned by our commercial database lady alice, and everybody is allowed to read those views.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SET ROLE bob; SET test=> SELECT * FROM v1; service_type | service | session_user | current_user ---------------+---------------------------+--------------+-------------- open_source | PostgreSQL consulting | hs | bob open_source | PostgreSQL training | hs | bob open_source | PostgreSQL 24x7 support | hs | bob closed_source | Oracle tuning | hs | bob closed_source | Oracle license management | hs | bob closed_source | IBM DB2 training | hs | bob (6 rows) |
Ooops! What is going on here? “bob” is allowed to see all the data. There is a reason for that: The view is owned by “postgres”. That means that the row level policy on t_service will not be taken into account. The RLS policies (Row Level Security) have been defined for bob and alice. However, in this case they are not taken into consideration, because the view is owned by the superuser, and the superuser has given us SELECT permissions on this view so we can see all that data. That is important: Imagine some sort of aggregation (e.g. SELECT sum(turnover) FROM sales). A user might see the aggregate but not the raw data. In that case, skipping the policy is perfectly fine.
|
1 2 3 4 5 6 7 8 9 10 |
test=> SELECT * FROM v2; psql: NOTICE: called as session_user=hs, current_user=bob for 'Oracle tuning' psql: NOTICE: called as session_user=hs, current_user=bob for 'Oracle license management' psql: NOTICE: called as session_user=hs, current_user=bob for 'IBM DB2 training' service_type | service | session_user | current_user ---------------+---------------------------+--------------+-------------- closed_source | Oracle tuning | hs | bob closed_source | Oracle license management | hs | bob closed_source | IBM DB2 training | hs | bob (3 rows) |
The “current_user” is still “bob” BUT what we see is only closed source data, which basically belongs to alice. Why does that happen? The reason is: v2 belongs to alice and therefore PostgreSQL will check alice's RLS policy. Remember, she is supposed to see closed source data and as the “owner” of the data she is in charge. The result is: bob will see closed source data, but no open source data (which happens to be his domain). Keep these corner cases in mind - not being aware of this behavior can create nasty security problems. Always ask yourself which policy PostgreSQL will actually use behind the scenes. Having a small test case at hand can be really useful in this context.
What you have seen are some corner cases many people are not aware of. Our PostgreSQL consultants have seen some horrible mistakes in this area already, and we would like to ensure that other people out there don't make the same mistakes.
Let us drop those policies:
|
1 2 3 4 5 6 |
test=> SET ROLE postgres; SET test=# DROP POLICY bob_pol ON t_service; DROP POLICY test=# DROP POLICY alice_pol ON t_service; DROP POLICY |
Usually policies are not assigned to individual people, but to a group of people or sometimes even to “public” (basically everybody who does not happen to be a superuser in this context). The following code snippet shows a simple example:
|
1 2 3 4 5 6 7 |
test=# CREATE POLICY general_pol ON t_service FOR SELECT TO public USING (CASE WHEN CURRENT_USER = 'bob' THEN service_type = 'open_source' ELSE service_type = 'closed_source' END); CREATE POLICY |
If the CURRENT_USER is bob, the system is supposed to show Open Source data. Otherwise it is all about closed source.
Let us take a look what happens:
|
1 2 3 4 5 6 7 8 9 |
test=# SET ROLE bob; SET test=> SELECT * FROM v2; service_type | service | session_user | current_user --------------+-------------------------+--------------+-------------- open_source | PostgreSQL consulting | hs | bob open_source | PostgreSQL training | hs | bob open_source | PostgreSQL 24x7 support | hs | bob (3 rows) |
The most important observation is that the policy applies to everybody who is not marked as superuser and it applies to everybody who is not marked with BYPASSRLS. As expected, alice will only see her subset of data:
|
1 2 3 4 5 6 7 8 9 |
test=> SET ROLE alice; SET test=> SELECT * FROM v2; service_type | service | session_user | current_user ---------------+---------------------------+--------------+-------------- closed_source | Oracle tuning | hs | alice closed_source | Oracle license management | hs | alice closed_source | IBM DB2 training | hs | alice (3 rows) |
The most important observation here is that defining policies has to be done with great care. ALWAYS make sure that your setup is well tested and that no leaks can happen. Security is one of the most important topics in any modern IT system and nobody wants to take chances in this area.
As a PostgreSQL consulting company we can help to make sure that your databases are indeed secure. Leaks must not happen and we can help to achieve that.
If you want to learn more about PostgreSQL security in general, check out our PostgreSQL products including Data Masking for PostgreSQL which helps you to obfuscate data, and check out PL/pgSQL_sec which has been designed explicitly to protect your code.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
UPDATED July 2023: Window functions and analytics have been around for quite some time and many people already make use of this awesome stuff in the PostgreSQL world. Timeseries are an especially important area in this context. However, not all features have been widely adopted and thus many developers have to implement functionality at the application level in a painful way instead of just using some of the more advanced SQL techniques.
The idea of this blog is to demonstrate some of the advanced analytics so that more people out there can make use of PostgreSQL's true power.
For the purpose of this post I have created a basic data set:
|
1 2 3 4 5 |
test=# CREATE TABLE t_demo AS SELECT ordinality, day, date_part('week', day) AS week FROM generate_series('2020-01-02', '2020-01-15', '1 day'::interval) WITH ORDINALITY AS day; SELECT 14 |
In PostgreSQL, the generate_series function will return one row each day spanning January 2nd, 2020 to January 15th, 2020. The WITH ORDINALITY clause tells PostgreSQL to add an “id” column to the result set of the function. The date_part function will extract the number of the week out of our date. The purpose of this column is to have a couple of identical values in our timeseries.
In the next list you see the data set we'll use:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
test=# SELECT * FROM t_demo; ordinality | day | week ------------+------------------------+------ 1 | 2020-01-02 00:00:00+01 | 1 2 | 2020-01-03 00:00:00+01 | 1 3 | 2020-01-04 00:00:00+01 | 1 4 | 2020-01-05 00:00:00+01 | 1 5 | 2020-01-06 00:00:00+01 | 2 6 | 2020-01-07 00:00:00+01 | 2 7 | 2020-01-08 00:00:00+01 | 2 8 | 2020-01-09 00:00:00+01 | 2 9 | 2020-01-10 00:00:00+01 | 2 10 | 2020-01-11 00:00:00+01 | 2 11 | 2020-01-12 00:00:00+01 | 2 12 | 2020-01-13 00:00:00+01 | 3 13 | 2020-01-14 00:00:00+01 | 3 14 | 2020-01-15 00:00:00+01 | 3 (14 rows) |
One of the things you often have to do is to use a sliding window. In SQL this can easily be achieved using the OVER clause. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
test=# SELECT *, array_agg(ordinality) OVER (ORDER BY day ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING), avg(ordinality) OVER (ORDER BY day ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) FROM t_demo; ordinality | day | week | array_agg | avg ------------+------------------------+------+------------+--------------------- 1 | 2020-01-02 00:00:00+01 | 1 | {1,2} | 1.5000000000000000 2 | 2020-01-03 00:00:00+01 | 1 | {1,2,3} | 2.0000000000000000 3 | 2020-01-04 00:00:00+01 | 1 | {2,3,4} | 3.0000000000000000 4 | 2020-01-05 00:00:00+01 | 1 | {3,4,5} | 4.0000000000000000 5 | 2020-01-06 00:00:00+01 | 2 | {4,5,6} | 5.0000000000000000 6 | 2020-01-07 00:00:00+01 | 2 | {5,6,7} | 6.0000000000000000 7 | 2020-01-08 00:00:00+01 | 2 | {6,7,8} | 7.0000000000000000 8 | 2020-01-09 00:00:00+01 | 2 | {7,8,9} | 8.0000000000000000 9 | 2020-01-10 00:00:00+01 | 2 | {8,9,10} | 9.0000000000000000 10 | 2020-01-11 00:00:00+01 | 2 | {9,10,11} | 10.0000000000000000 11 | 2020-01-12 00:00:00+01 | 2 | {10,11,12} | 11.0000000000000000 12 | 2020-01-13 00:00:00+01 | 3 | {11,12,13} | 12.0000000000000000 13 | 2020-01-14 00:00:00+01 | 3 | {12,13,14} | 13.0000000000000000 14 | 2020-01-15 00:00:00+01 | 3 | {13,14} | 13.5000000000000000 (14 rows) |
array_aggThe OVER clause allows you to feed the data to the aggregate function. For the sake of simplicity, I have used the array_agg function, which simply returns the data fed to the aggregate as an array. In a real-life scenario you would use something more common such as the avg, sum, min, max, or any other aggregation function. However, array_agg is pretty useful, in that it shows which data is really passed to the function, and what values we have in use. ROWS BETWEEN … PRECEDING AND 1 … FOLLOWING tells the system that we want to use 3 rows: The previous, the current one, as well as the one after the current row. At the beginning of the list, there is no previous row, so we will only see two values in the array column. At the end of the data set, there are also only two rows, because there are no more values after the last one.
In some cases, it can be useful to exclude the current row from the data passed to the aggregate. The EXCLUDE CURRENT ROW clause has been developed to do exactly that. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=# SELECT *, array_agg(ordinality) OVER (ORDER BY day ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING EXCLUDE CURRENT ROW) FROM t_demo; ordinality | day | week | array_agg ------------+------------------------+------+----------- 1 | 2020-01-02 00:00:00+01 | 1 | {2} 2 | 2020-01-03 00:00:00+01 | 1 | {1,3} 3 | 2020-01-04 00:00:00+01 | 1 | {2,4} 4 | 2020-01-05 00:00:00+01 | 1 | {3,5} 5 | 2020-01-06 00:00:00+01 | 2 | {4,6} 6 | 2020-01-07 00:00:00+01 | 2 | {5,7} 7 | 2020-01-08 00:00:00+01 | 2 | {6,8} 8 | 2020-01-09 00:00:00+01 | 2 | {7,9} 9 | 2020-01-10 00:00:00+01 | 2 | {8,10} 10 | 2020-01-11 00:00:00+01 | 2 | {9,11} 11 | 2020-01-12 00:00:00+01 | 2 | {10,12} 12 | 2020-01-13 00:00:00+01 | 3 | {11,13} 13 | 2020-01-14 00:00:00+01 | 3 | {12,14} 14 | 2020-01-15 00:00:00+01 | 3 | {13} (14 rows) |
As you can see, the array is a little shorter now. The current value is not part of the array anymore.
The idea behind EXCLUDE TIES is to remove duplicates. Let's take a look at the following to make things clear:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
test=# SELECT day, week, array_agg(week) OVER (ORDER BY week ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS all, array_agg(week) OVER (ORDER BY week ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING EXCLUDE TIES) AS ties FROM t_demo; day | week | all | ties ------------------------+------+-------------+--------- 2020-01-02 00:00:00+01 | 1 | {1,1,1} | {1} 2020-01-03 00:00:00+01 | 1 | {1,1,1,1} | {1} 2020-01-04 00:00:00+01 | 1 | {1,1,1,1,2} | {1,2} 2020-01-05 00:00:00+01 | 1 | {1,1,1,2,2} | {1,2,2} 2020-01-06 00:00:00+01 | 2 | {1,1,2,2,2} | {1,1,2} 2020-01-07 00:00:00+01 | 2 | {1,2,2,2,2} | {1,2} 2020-01-08 00:00:00+01 | 2 | {2,2,2,2,2} | {2} 2020-01-09 00:00:00+01 | 2 | {2,2,2,2,2} | {2} 2020-01-10 00:00:00+01 | 2 | {2,2,2,2,2} | {2} 2020-01-11 00:00:00+01 | 2 | {2,2,2,2,3} | {2,3} 2020-01-12 00:00:00+01 | 2 | {2,2,2,3,3} | {2,3,3} 2020-01-13 00:00:00+01 | 3 | {2,2,3,3,3} | {2,2,3} 2020-01-14 00:00:00+01 | 3 | {2,3,3,3} | {2,3} 2020-01-15 00:00:00+01 | 3 | {3,3,3} | {3} (14 rows) |
The first array_agg simply collects all values in the frame we have defined. The “ties” column is a bit more complicated to understand: Let's take a look at the 5th of January. The result says (1, 2, 2). As you can see, two incarnations of 1 have been removed. EXCLUDE TIES made sure that those duplicates are gone. However, this has no impact on those values in the “future”, because the future values are different from the current row. The documentation states what EXCLUDE TIES is all about: “EXCLUDE TIES excludes any peers of the current row from the frame, but not the current row itself.”
After this first example, we should also consider a fairly common mistake:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
test=# SELECT day, week, array_agg(week) OVER (ORDER BY week, day ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING EXCLUDE TIES) AS ties FROM t_demo; day | week | ties ------------------------+------+------------- 2020-01-02 00:00:00+01 | 1 | {1,1,1} 2020-01-03 00:00:00+01 | 1 | {1,1,1,1} 2020-01-04 00:00:00+01 | 1 | {1,1,1,1,2} 2020-01-05 00:00:00+01 | 1 | {1,1,1,2,2} 2020-01-06 00:00:00+01 | 2 | {1,1,2,2,2} 2020-01-07 00:00:00+01 | 2 | {1,2,2,2,2} 2020-01-08 00:00:00+01 | 2 | {2,2,2,2,2} 2020-01-09 00:00:00+01 | 2 | {2,2,2,2,2} 2020-01-10 00:00:00+01 | 2 | {2,2,2,2,2} 2020-01-11 00:00:00+01 | 2 | {2,2,2,2,3} 2020-01-12 00:00:00+01 | 2 | {2,2,2,3,3} 2020-01-13 00:00:00+01 | 3 | {2,2,3,3,3} 2020-01-14 00:00:00+01 | 3 | {2,3,3,3} 2020-01-15 00:00:00+01 | 3 | {3,3,3} (14 rows) |
Can you spot the difference between this and the previous example? Take all the time you need …
The problem is that the ORDER BY clause has two columns in this case. That means that there are no duplicates anymore from the ORDER BY's perspective. Thus, PostgreSQL is not going to prune values from the result set. I can assure you that this is a common mistake seen in many cases. The problem can be very subtle and go unnoticed for quite some time.
In some cases you might want to remove an entire set of rows from the result set. To do that, you can make use of EXCLUDE GROUP.
The following example shows how that works, and how our timeseries data can be analyzed:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
test=# SELECT *, array_agg(week) OVER (ORDER BY week ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING EXCLUDE GROUP) AS week, array_agg(week) OVER (ORDER BY day ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING EXCLUDE GROUP) AS all FROM t_demo; ordinality | day | week | week | all ------------+------------------------+------+-------+----------- 1 | 2020-01-02 00:00:00+01 | 1 | | {1,1} 2 | 2020-01-03 00:00:00+01 | 1 | | {1,1,1} 3 | 2020-01-04 00:00:00+01 | 1 | {2} | {1,1,1,2} 4 | 2020-01-05 00:00:00+01 | 1 | {2,2} | {1,1,2,2} 5 | 2020-01-06 00:00:00+01 | 2 | {1,1} | {1,1,2,2} 6 | 2020-01-07 00:00:00+01 | 2 | {1} | {1,2,2,2} 7 | 2020-01-08 00:00:00+01 | 2 | | {2,2,2,2} 8 | 2020-01-09 00:00:00+01 | 2 | | {2,2,2,2} 9 | 2020-01-10 00:00:00+01 | 2 | | {2,2,2,2} 10 | 2020-01-11 00:00:00+01 | 2 | {3} | {2,2,2,3} 11 | 2020-01-12 00:00:00+01 | 2 | {3,3} | {2,2,3,3} 12 | 2020-01-13 00:00:00+01 | 3 | {2,2} | {2,2,3,3} 13 | 2020-01-14 00:00:00+01 | 3 | {2} | {2,3,3} 14 | 2020-01-15 00:00:00+01 | 3 | | {3,3} (14 rows) |
The first aggregation function does ORDER BY week and the array_agg will aggregate on the very same column. In this case, we will see a couple of NULL columns, because in some cases all entries within the frame are simply identical. The last row in the result set is a good example: All array entries are 3 and the current row contains 3 as well. Thus all incarnations of 3 are simply removed, which leaves us with an empty array.
To calculate the last column, the data is ordered by day. In this case, there are no duplicates and therefore no data can be removed. For more information on EXCLUDE GROUP, see the documentation on window functions.
In PostgreSQL, an aggregate function is capable of handling DISTINCT. The following example shows what I mean:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# SELECT DISTINCT week FROM t_demo; week ------ 3 1 2 (3 rows) test=# SELECT count(DISTINCT week) FROM t_demo; count ------- 3 (1 row) |
“count” does not simply count all columns, but filters the duplicates beforehand. Therefore the result is simply 3.
In PostgreSQL there is no way to use DISTINCT as part of a window function. PostgreSQL will simply error out:
|
1 2 3 4 5 6 |
test=# SELECT *, array_agg(DISTINCT week) OVER (ORDER BY day ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) FROM t_demo; ERROR: DISTINCT is not implemented for window functions LINE 2: array_agg(DISTINCT week) OVER (ORDER BY day ROWS |
The natural question which arises is: How can we achieve the same result without using DISTINCT inside the window function? What you have to do is to filter the duplicates on a higher level. You can use a subselect, unroll the array, remove the duplicates and assemble the array again. It is not hard to do, but it is not as elegant as one might expect.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
test=# SELECT *, (SELECT array_agg(DISTINCT unnest) FROM unnest(x)) AS b FROM ( SELECT *, array_agg(week) OVER (ORDER BY day ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS x FROM t_demo ) AS a; ordinality | day | week | x | b ------------+------------------------+------+-------------+------- 1 | 2020-01-02 00:00:00+01 | 1 | {1,1,1} | {1} 2 | 2020-01-03 00:00:00+01 | 1 | {1,1,1,1} | {1} 3 | 2020-01-04 00:00:00+01 | 1 | {1,1,1,1,2} | {1,2} 4 | 2020-01-05 00:00:00+01 | 1 | {1,1,1,2,2} | {1,2} 5 | 2020-01-06 00:00:00+01 | 2 | {1,1,2,2,2} | {1,2} 6 | 2020-01-07 00:00:00+01 | 2 | {1,2,2,2,2} | {1,2} 7 | 2020-01-08 00:00:00+01 | 2 | {2,2,2,2,2} | {2} 8 | 2020-01-09 00:00:00+01 | 2 | {2,2,2,2,2} | {2} 9 | 2020-01-10 00:00:00+01 | 2 | {2,2,2,2,2} | {2} 10 | 2020-01-11 00:00:00+01 | 2 | {2,2,2,2,3} | {2,3} 11 | 2020-01-12 00:00:00+01 | 2 | {2,2,2,3,3} | {2,3} 12 | 2020-01-13 00:00:00+01 | 3 | {2,2,3,3,3} | {2,3} 13 | 2020-01-14 00:00:00+01 | 3 | {2,3,3,3} | {2,3} 14 | 2020-01-15 00:00:00+01 | 3 | {3,3,3} | {3} (14 rows) |
In case you are interested in timeseries and aggregation in general, consider checking out some of our other blog posts including “Speeding up count(*)” by Laurenz Albe. If you are interested in high-performance PostgreSQL check out my blog post about finding slow queries.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
Trivial timeseries are an increasingly important topic - not just in PostgreSQL. Recently I gave a presentation @AGIT in Salzburg about timeseries and I demonstrated some super simple examples. The presentation was well received, so I decided to share this stuff in the form of a blog, so that more people can learn about window functions and SQL in general. A link to the video is available at the end of the post so that you can listen to the original material in German.
To show how data can be loaded, I compiled a basic dataset which can be found on my website. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# CREATE TABLE t_oil ( region text, country text, year int, production int, consumption int ); CREATE TABLE test=# COPY t_oil FROM PROGRAM 'curl /secret/oil_ext.txt'; COPY 644 |
The cool thing is that if you happen to be a superuser, you can easily load the data from the web directly. COPY FROM PROGRAM allows you to execute code on the server and pipe it directly to PostgreSQL, which is super simple. Keep in mind: that only works if you are a PostgreSQL superuser (for security reasons).
If you are dealing with timeseries, calculating the difference to the previous period is really important. Fortunately, SQL allows you to do that pretty easily. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# SELECT year, production, lag(production, 1) OVER (ORDER BY year) FROM t_oil WHERE country = 'USA' LIMIT 5; year | production | lag ------+------------+------- 1965 | 9014 | 1966 | 9579 | 9014 1967 | 10219 | 9579 1968 | 10600 | 10219 1969 | 10828 | 10600 (5 rows) |
The lag functions takes two parameters: The first column defines the column, which should be used in this case. The second parameter is optional. If you skip it, the expression will be equivalent to lag(production, 1). In my example, the lag column will be off by one. However, you can use any integer number to move data up or down, given the order defined in the OVER clause.
What we have so far is the value of the previous period. Let us calculate the difference next:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# SELECT year, production, production - lag(production, 1) OVER (ORDER BY year) AS diff FROM t_oil WHERE country = 'USA' LIMIT 5; year | production | diff ------+------------+------ 1965 | 9014 | 1966 | 9579 | 565 1967 | 10219 | 640 1968 | 10600 | 381 1969 | 10828 | 228 (5 rows) |
That was easy. All we have to do is to take the current row and subtract the previous row.
Window functions are far more powerful than shown here, but maybe this example will help to get you started in the first place.
You may want to calculate the correlation between columns. PostgreSQL offers the “corr” function to do exactly that. The following listing shows a simple example:
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# SELECT country, corr(production, consumption) FROM t_oil GROUP BY 1 ORDER BY 2 DESC NULLS LAST; country | corr ----------------------+-------------------- Mexico | 0.962790640608018 Canada | 0.932931452462893 Qatar | 0.925552359601189 United Arab Emirates | 0.882953285119214 Saudi Arabien | 0.642815458284221 |
As you can see, the correlation in Mexico and Canada are highest.
In the past we presented other examples related to timeseries and analysis in general. One of the most interesting posts is found here.
If you want to see the entire short presentation in German consider checking out the following video.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.