By Kaarel Moppel - Some weeks ago, in the light of PostgreSQL v12 release, I wrote a general overview on various major version upgrade methods and benefits of upgrading in general - so if upgrading is a new thing for you I’d recommend to read that posting first. But this time I’m concentrating on the newest (available since v10) and the most complex upgrade method - called “Logical Replication” or LR shortly. For demonstration purposes I’ll be migrating from v10 to freshly released v12 as this is probably the most likely scenario. But it should work the same also with v11 to v12. But do read on for details.
First a bit of recap from the previous post on why would you use LR for upgrading at all. Well, in short - because it’s the safest option with shortest possible downtime! With that last point I’m already sold...but here again the list of “pros” / “cons”:
After the initial setup burden one just needs to wait (and verify) that the new instance hast all the data from the old one...and then just shut down the old instance and point applications to the new instance. Couldn’t be easier!
Also before the switchover one can make sure that statistics are up to date, to minimize the typical “degraded performance” period seen after "pg_upgrade" for more complex queries (on bigger databases). For high load application one could even be more careful here and pull the most popular relations into shared buffers by using the (relatively unknown) “pg_prewarm” Contrib extension or by just running common SELECT-s in a loop, to counter the “cold cache” effect.
One can for example already make some changes on the target DB – add columns / indexes, change datatypes, leave out some old archive tables, etc. The general idea is that LR does not work on the binary, 1-to-1 level as”pg_upgrade” does, but rather JSON-like data objects are sent over to another master / primary instance, providing quite some freedom on the details.
Before the final switchover you can anytime abort the process and re-try if something seems fishy. The old instances data is not changed in any way even after the final switchover! Meaning you can easily roll back (with cost of some data loss typically though) to the old version if some unforeseen issues arise. One should only watch out for the replication slot on the source / publisher DB if the target server just taken down suddenly.
As LR has some prerequisites on the configuration and schema, you’d first need to see if it’s possible to start with the migration process at all or some changes are needed on the old master node, also called the “publisher” in LR context.
Action points:
1) Enable LR on the old master aka subscriber aka source DB if not done already. This means setting “wal_level” to “logical” in postgresql.conf and making sure that “replication” connections are allowed in “pg_hba.conf” from the new host (also called the “subscriber” in LR context). FYI - changing “wal_level” needs server restart! To enable any kind of streaming replication some other params are needed but they are actually already set accordingly out of the box as of v10 so it shouldn’t be a problem.
2) Check that all tables have a Primary Key (which is good database design anyways) or alternatively have REPLICA IDENTITY set. Primary Keys don’t need much explaining probably but what is this REPLICA IDENTITY thing? A bit simplified - basically it allows to say which columns formulate uniqueness within a table and PK-s are automatically counted as such.
3) If there’s no PK for a particular table, you should create one, if possible. If you can’t do that, set unique constraints / indexes to serve as REPLICA IDENTITY, if at all possible. If even that isn’t possible, you can set the whole row as REPLICA IDENTITY, a.k.a. REPLICA IDENTITY FULL, meaning all columns serve as PK’s in an LR context - with the price of very slow updates / deletes on the subscriber (new DB) side, meaning the whole process could take days or not even catch up, ever! It’s OK not to define a PK for a table, as long as it’s a write-only logging table that only gets inserts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
psql -c “ALTER SYSTEM SET wal_level TO logical;” sudo systemctl postgresql@10-main restart # find problematic tables (assuming we want to migrate everything 'as is') SELECT format('%I.%I', nspname, relname) AS tbl FROM pg_class AS c JOIN pg_namespace AS n ON c.relnamespace = n.oid WHERE c.relkind = 'r' AND NOT n.nspname LIKE ANY (ARRAY[E'pg\_%', 'information_schema']) AND NOT EXISTS (SELECT FROM pg_index AS i WHERE i.indrelid = c.oid AND i.indisunique AND i.indisvalid AND i.indisready AND i.indislive) ORDER BY 1; # set replica identities on tables highlighted by the previous query ALTER TABLE some_bigger_table REPLICA IDENTITY USING INDEX unique_idx ; ALTER TABLE some_table_with_no_updates_deletes REPLICA IDENTITY FULL ; |
Second most important step is to set up a new totally independent instance with a newer Postgres version - or at least create a new database on an existing instance with the latest major version. And as a side note - same version LR migrations are also possible, but you'd be solving some other problem in that case.
This step is actually very simple - just a standard install of PostgreSQL, no special steps needed! With the important addition that to make sure everything works exactly the same way as before for applications - same encoding and collation should be used!
|
1 2 3 4 5 |
-- on old SELECT pg_catalog.pg_encoding_to_char(d.encoding) AS 'Encoding', d.datcollate as 'Collate' FROM pg_database d WHERE datname = current_database(); -- on new CREATE DATABASE appdb TEMPLATE template0 ENCODING UTF8 LC_COLLATE 'en_US.UTF-8'; |
NB! Before the final switchover it’s important that no normal users have access to the new DB - as they might alter table data or structures and thereby inadvertently produce replication conflicts that mostly mean starting from scratch (or a costly investigation / fix) as “replay” is a sequential process.
Next we need to synchronize the old schema onto the new DB as Postgres does not take care of that automatically as of yet. The simplest way is to use the official PostgreSQL backup tool called “pg_dump”, but if you have your schema initialization scripts in Git or such and they're up to date then this is fine also. For syncing roles “pg_dumpall” can be used.
NB! After this point it’s not recommended to introduce any changes to the schema or be at least very careful when doing it, e.g. creating new tables / columns first on the subscriber and refreshing the subscriptions when introducing new tables - otherwise data synchronization will break! Tip - a good way to disable unwanted schema changes is to use DDL triggers! An approximate example on that is here. Adding new tables only on the new DB is no issue though but during an upgrade not a good idea anyways - my recommendation is to first upgrade and then to evolve the schema.
|
1 2 |
pg_dumpall -h $old_instance --globals-only | psql -h $new_instance pg_dump -h $old_instance --schema-only appdb | psql -h $new_instance appdb |
If preparations on the old DB has been finished (all tables having PK-s or replication identities) then this is a oneliner:
|
1 |
CREATE PUBLICATION upgrade FOR ALL TABLES; |
Here we added all (current and those added in future) tables to a publication (a replication set) named “upgrade” but technically we could also leave out some or choose to only replicate some operations like UPDATE-s, but for a pure version upgrade you want typically all.
NB! As of this moment the replication identities become important - and you might run into trouble on the old master if the identities are not in place on all tables that get changes! In such case you might see errors like that:
|
1 2 3 4 |
UPDATE pgbench_history SET delta = delta WHERE aid = 1; ERROR: cannot update table 'pgbench_history' because it does not have a replica identity and publishes updates HINT: To enable updating the table, set REPLICA IDENTITY using ALTER TABLE. |
Next step - create a “subscription” on the new DB. This is also a oneliner, that creates a logical replication slot on the old instance, pulls initial table snapshots and then starts to stream and apply all table changes as they happen on the source, resulting eventually in a mirrored dataset! Note that currently superuser rights are needed for creating the subscription and actually hit also makes life a lot easier on the publisher side.
|
1 2 3 |
CREATE SUBSCRIPTION upgrade_sub CONNECTION 'port=5432 user=postgres' PUBLICATION upgrade; NOTICE: created replication slot 'upgrade_sub' on publisher CREATE SUBSCRIPTION |
WARNING! As of this step the 2 DB-s are “coupled” via a replication slot, carrying some dangers if the process is aborted abruptly and the old DB is not “notified” of that. If this sounds new please see the details from documentation.
Depending on the amount of data it will take X minutes / days until everything is moved over and “live” synchronization is working.
Things to inspect for making sure there are no issues:
Although not a mandatory step, when it comes to data consistency / correctness, it always makes sense to go the extra mile and run some queries that validate that things (source - target) have the same data. For a running DB it’s of course a bit difficult as there’s always some replication lag but for “office hours” applications it should make a lot of sense. My sample script for comparing rowcounts (in a non-threaded way) is for example here but using some slightly more "costly" aggregation / hashing functions that really look at all the data would be even better there.
Also important to note if you’re using sequences (which you most probably are) - sequence state is not synchronized by LR and needs some manual work / scripting! The easiest option I think is that you leave the old DB ticking in read-only mode during switchover so that you can quickly access the last sequence values without touching the indexes for maximum ID-s on the subscriber side.
We’re almost there with our little undertaking...with the sweaty part remaining - the actual switchover to start using the new DB! Needed steps are simple though and somewhat similar to switching over to a standard, “streaming replication” replica.
Make sure it’s a nice shutdown. The last logline should state “database system is shut down”, meaning all recent changes were delivered to connected replication clients, including our new DB. Start of downtime! PS Another alternative to make sure absolutely all data is received is to actually configure the new instance in “synchronous replication” mode! This has the usual synchronous replication implications of course so I’d avoid it for bigger / busier DBs.
From v12 this is achieved by declaring a "standby.signal" file
if time constraints allow it - verify table sizes, row counts, your last transactions, etc. For “live” comparisons it makes sense to restart the old DB under a new, random port so that no-one else connects to it.
Given we'll leave the old DB in read-only mode the easiest way is something like that:
|
1 2 3 |
psql -h $old_instance -XAtqc 'SELECT $select setval('$ || quote_ident(schemaname)||$.$|| quote_ident(sequencename) || $', $ || last_value || $); $ AS sql FROM pg_sequences' appdb | psql -h $new_instance appdb |
your pg_hba.conf to allow access for all "mortal" users, then reconfigure your application, connection pooler, DNS or proxy to start using the new DB! If the two DB-s were on the same machine then it’s even easier - just change the ports and restart. End of downtime!
Basically we’re done here, but would be nice of course to clean up and remove the (no-more needed) subscription not to accumulate errors in server log.
|
1 |
DROP SUBSCRIPTION upgrade_sub; |
Note that if you won't keep the old “publisher” accessible in read-only or normal primary mode (dangerous!) though, some extra steps are needed here before dropping:
|
1 2 3 |
ALTER SUBSCRIPTION upgrade_sub DISABLE ; ALTER SUBSCRIPTION upgrade_sub SET (slot_name = NONE); DROP SUBSCRIPTION upgrade_sub; |
Although there are quite some steps and nuances involved, LR is worth adding to the standard upgrade toolbox for time-critical applications as it’s basically the best way to do major version upgrades nowadays - minimal dangers, minimal downtime!
FYI - if you're planning to migrate dozens of DB-s the LR upgrade process can be fully automated! Even starting from version 9.4 actually, with the help of the “pglogical” extension. So feel free to contact us if you might need something like that and don't particularly enjoy the details. Thanks for reading!
By Kevin Speyer
Reinforcement Learning (RL) has gained a lot of attention due to its ability to surpass humans at numerous table games like chess, checkers and Go. If you are interested in AI, you have surely seen the video where a RL trained program finishes a Supermario level.
In this post, I'll show you how to write your first RL program from scratch. Then, I'll show how this algorithm manages to find better solutions for the Travelling Salesman Problem (TSP) than Google’s specialised algorithms. I will not go through the mathematical details of RL. You can read an introduction of Reinforcement Learning in this article and also in this article.
We will use a model-free RL named Q-learning. The key element in this algorithm is Q(s,a), which gives a score for each action (a) to take, given the state (s) that the agent is in. During training, the agent will go through various states and estimate what the total reward for each possible action is, taking into account the short- and long-term consequences. Mathematically speaking, this is written:
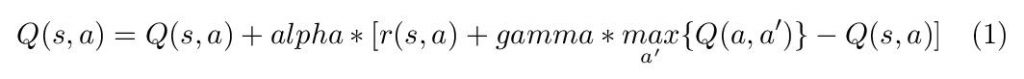
The parameters are alpha (learning rate) and gamma (discount factor). r(s,a) is the immediate reward for taking actions a under state s. The second term, max_a' ( Q(a,a') ), is the tricky one. This adds the future reward to Q(s,a) so that long-term objectives are taken into account in Q(s,a). Gamma is a discount factor between 0 and 1 that gives a lower weight to distant events in the future.
Now it's just a matter of mapping states, rewards and actions to a specific problem. We will solve the Travelling Salesman Problem using Q-learning. Given a set of travelling distances between destinations, the problem is to find the shortest route to visit every location. In this case, we will start and finish in the same location, so it's a round trip. Now we need to map the problem to the algorithm.
Naturally, the state s is the location the salesman is at. The possible actions are the points he can visit; that was easy! Now, what is the immediate reward for going from point 0 to point 1? We want the reward to be a monotonic descendent function with respect to travelling distance. That is: less distance, more reward. In this case I used r(s,a) = 1/d_sa, where d_sa is the travelling distance between point s and point a. We are assuming that there is no 0 distance travel between points. Another possibility is to use r(s,a)=-d_sa.
First, we have to obtain the data. In this case, the given data is the location of each city to be visited by the salesman. Typically, this kind of data is stored in databases (DB). This means that we have to connect and query the DB to extract the relevant information. In this case I used PostgreSQL due to its features and simplicity. The programming language of choice for this project is python, because it is the most popular option for data science projects.
Let’s set the connection to the DB:
|
1 2 3 |
import psycopg2 connection = psycopg2.connect(user = 'usname', database = 'db_name') cursor = connection.cursor() |
In usname and db_name you should write your username and database name, respectively. Now we have to query the DB, and get the position of each city:
|
1 2 |
cursor.execute("select x_coor, y_coor from city_locations;") locations = cursor.fetchall() |
Finally, we have to calculate the distances between each pair of cities and save it as a matrix:
|
1 2 3 4 5 6 7 |
import numpy as np n_dest = len(locations) # 20 destinations in this case dist_mat = np.zeros([n_dest,n_dest]) for i,(x1,y1) in enumerate(locations): for j,(x2,y2) in enumerate(locations): d = np.sqrt((x1-x2)**2+(y1-y2)**2) # Euclid distance dist_mat[i,j] = d |
We will define just one function which will be responsible for updating the elements of the Q-matrix in the training phase according to equation 1.
|
1 2 3 4 5 |
def update_q(q, dist_mat, state, action, alpha=0.012, gamma=0.4): immed_reward = 1./ dist_mat[state,action] # Set immediate reward as inverse of distance delayed_reward = q[action,:].max() q[state,action] += alpha * (immed_reward + gamma * delayed_reward - q[state,action]) return q |
Now we can train the RL model by letting the agent run through all the destinations, collecting the rewards. We will use 2000 training iterations.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
q = np.zeros([n_dest,n_dest]) epsilon = 1. # Exploration parameter n_train = 2000 # Number of training iterations for i in range(n_train): traj = [0] # initial state is the warehouse state = 0 possible_actions = [ dest for dest in range(n_dest) if dest not in traj] while possible_actions: # until all destinations are visited #decide next action: if random.random() < epsilon: # explore random actions action = random.choice(possible_actions) else: # exploit known data from Q matrix best_action_index = q[state, possible_actions].argmax() action = possible_actions[best_action_index] # update Q: core of the training phase q = update_q(q, dist_mat, state, action) traj.append(action) state = traj[-1] possible_actions = [ dest for dest in range(n_dest) if dest not in traj] # Last trip: from last destination to warehouse action = 0 q = update_q(q, dist_mat, state, action) traj.append(0) epsilon = 1. - i * 1/n_train |
The parameter epsilon (between 0 and 1) controls the exploration vs exploitation ratio in training. If epsilon is near 1, then the agent will take random decisions and explore new possibilities. A low value of epsilon means the agent will take the best known path, exploiting the information already acquired. A well-known policy is to lower this epsilon parameter as the model gains insight into the problem. At the beginning, the agent takes random actions and explores different routes, and as the Q matrix gains more useful information, the agent is more likely to take the path of greater reward.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
traj = [0] state = 0 distance_travel = 0. possible_actions = [ dest for dest in range(n_dest) if dest not in traj ] while possible_actions: # until all destinations are visited best_action_index = q[state, possible_actions].argmax() action = possible_actions[best_action_index] distance_travel += dist_mat[state, action] traj.append(action) state = traj[-1] possible_actions = [ dest for dest in range(n_dest) if dest not in traj ] # Back to warehouse action = 0 distance_travel += dist_mat[state, action] traj.append(action) #Print Results: print('Best trajectory found:') print(' -> '.join([str(b) for b in traj])) print(f'Distance Travelled: {distance_travel}') |
The agent starts at the warehouse and runs through all cities according to the Q matrix, trying to minimise the total distance of the route.
To compare the solutions given by this algorithm, we will use the QR-tools TSP solver from Google. This is a highly specialised algorithm particularly designed to solve the TSP, and has great performance. After playing around with the RL algorithm and tuning the parameters (alpha and gamma), I was surprised to see that our RL algorithm was able to find shorter routes than Google's algorithm in some cases.
|
1 2 |
RL route: 0 -> 7 -> 17 -> 2 -> 19 -> 4 -> 8 -> 9 -> 18 -> 14 -> 11 -> 3 -> 6 -> 12 -> 10 -> 16 -> 13-> 1 -> 5 -> 15 -> 0; distance: 3511 Google route 0 -> 7 -> 17 -> 2 -> 19 -> 4 -> 8 -> 9 -> 18 -> 14 -> 11 -> 3 -> 6 -> 5 -> 10 -> 16 -> 13-> 1 -> 12 -> 15 -> 0; distance: 3767 |
The Reinforcement Learning algorithm was able to beat the highly specific algorithm by almost 7%! It is worth mentioning that most of the time, OR-Tools’ algorithm finds the best solution, but not infrequently, our simple RL algorithm finds a better solution.
“Durability”, the D of ACID, demands that a committed database transaction remains committed, no matter what. For normal outages like a power failure, this is guaranteed by the transaction log (WAL). However, if we want to guarantee durability even in the face of more catastrophic outages that destroy the WAL, we need more advanced methods.
This article discusses how to use pg_receivewal to maintain durability even under dire circumstances.
archive_commandThe “traditional” method of archiving the transaction log is the archive_command in postgresql.conf. The DBA has to set this parameter to a command that archives a WAL segment after it is completed.
Popular methods include:
cp (or copy on Windows) to copy the file to network attached storage like NFS.scp or rsync to copy the file to a remote machine.The important thing to consider is that the archived WAL segment is stored somewhere else than the database.
Yes, because there is still a single point of failure: the file system.
If the file system becomes corrupted through a hardware or software problem, all the redundant distributed copies of your WAL archive can vanish or get corrupted.
If you believe that this is so unlikely that it borders on the paranoid: I have seen it happen.
A certain level of professional paranoia is a virtue in a DBA.
archive_command isn't good enoughIf your database server gets destroyed so that its disks are no longer available, we will still lose some committed transactions: the transactions in the currently active WAL segment. Remember that PostgreSQL archives a WAL segment usually when it is full. So up to 16MB worth of committed transactions can vanish with the active WAL segment.
To reduce the impact, you can set archive_timeout: that will set the maximum time between WAL archivals. But for some applications, that just isn't good enough: If you cannot afford to lose a single transaction even in the event of a catastrophe, WAL archiving just won't do the trick.
pg_receivewal comes to the rescuePostgreSQL 9.2 introduced pg_receivexlog, which has been renamed to pg_receivewal in v10. This client program will open a replication connection to PostgreSQL and stream WAL, just like streaming replication does. But instead of applying the information to a standby server, it writes it to disk. This way, it creates a copy of the WAL segments in real time. The partial WAL segment that pg_receivewal is currently writing has the extension .partial to distinguish it from completed WAL archives. Once the segment is complete, pg_receivewal will rename it.
pg_receivewal is an alternative to WAL archiving that avoids the gap between the current and the archived WAL location. It is a bit more complicated to manage and monitor, because it is a separate process and should run on a different machine.
pg_receivewal and synchronous replicationBy default, replication is asynchronous, so pg_receivewal can still lose a split second's worth of committed transactions in the case of a crash. If you cannot even afford that, you can switch to synchronous replication. That guarantees that not a single committed transaction can get lost, but it comes at a price:
pg_receivewal, it will take significantly longer. This has an impact on the number of writing transactions your system can support.pg_receivewal acts as a standby), the availability of your system is reduced. This is because PostgreSQL won't commit any more transactions if your only standby is unavailable.pg_receivewal processes.Now if the worst has happened and you need to recover, you'll have to make sure to restore the partial WAL segments as well. In the simple case where you archive to an NFS mount, the restore_command could be as simple as this:
|
1 |
restore_command = 'cp /walarchive/%f %p || cp /walarchive/%f.partial %p' |
With careful design and a little effort, you can set up a PostgreSQL system that can never lose a single committed transaction even under the most dire circumstances. Integrate this with a high availability setup for maximum data protection.
PostgreSQL uses shared_buffers to cache blocks in memory. The idea is to reduce
disk I/O and to speed up the database in the most efficient way
possible. During normal operations your database cache will be pretty useful and
ensure good response times. However, what happens if your database instance is
restarted - for whatever reason? Your PostgreSQL database performance will suffer
until your I/O caches have filled up again. This takes some time and it can
be pretty damaging to your query response times.
Fortunately, there are ways in PostgreSQL to fix the problem. pg_prewarm is a
module which allows you to automatically prewarm your caches after a database
failure or a simple restart. The pg_prewarm module is part of the PostgreSQL
contrib package and is usually available on your server by default.
There is no need to install additional third party software. PostgreSQL has all
you need by default.
Basically, pg_prewarm can be used in two ways:
Let us take a look at both options and see how the module works in detail. In general automatic pre-warming is, in my judgement, the better way to preload caches - but in some cases, it can also make sense to just warm caches manually (usually for testing purposes).
Prewarming the cache manually is pretty simple. The following section explains how the process works in general.
The first thing to do is to enable the pg_prewarm extension in your database:
|
1 2 |
test=# CREATE EXTENSION pg_prewarm; CREATE EXTENSION |
To show how a table can be preloaded, I will first create a table and put it into
the cache:
|
1 2 3 4 5 6 7 8 |
test=# CREATE TABLE t_test AS SELECT * FROM generate_series(1, 1000000) AS id; SELECT 1000000 test=# SELECT * FROM pg_prewarm('public.t_test'); pg_prewarm ------------ 4425 (1 row) |
All you have to do is to call the pg_prewarm function and pass the name of the
desired table to the function. In my example, 4425 pages have been read and put
into the cache.
4425 blocks translates to roughly 35 MB:
|
1 2 3 4 5 |
test=# SELECT pg_size_pretty(pg_relation_size('t_test')); pg_size_pretty ---------------- 35 MB (1 row) |
Calling pg_prewarm with one parameter is the easiest way to get started.
However, the module can do a lot more, as shown in the next listing:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
test=# x Expanded display is on. test=# df *pg_prewarm* List of functions -[ RECORD 1 ] ---------------------+--------------------------------------------- Schema | public Name | pg_prewarm Result data type | bigint Argument data types | regclass, mode text DEFAULT 'buffer'::text, fork text DEFAULT 'main'::text, first_block bigint DEFAULT NULL::bigint, last_block bigint DEFAULT NULL::bigint Type | func |
In addition to passing the name of the object you want to cache to the function,
you can also tell PostgreSQL which part of the table you want to cache. The
"relation fork" defines whether you want the real data file, the VM (Visibility
Map) or the FSM (Free Space Map). Usually, caching the main table is just fine.
You can also tell PostgreSQL to cache individual blocks. While this is flexible,
it is usually not what you want to do manually.
In most cases, people might want pg_prewarm to take care of caching automatically
on startup. The way to achieve this is to add pg_prewarm to
shared_preload_libraries and to restart the database server. The following
example shows how to configure shared_preload_libraries in postgresql.conf:
shared_preload_libraries = 'pg_stat_statements, pg_prewarm'
After the server has restarted you should be able to see the "autoprewarm
master" process which is in charge of starting up things for you.
|
1 2 3 4 5 6 7 8 9 |
80259 ? Ss 0:00 /usr/pgsql-11/bin/postmaster -D /var/lib/pgsql/11/data/ 80260 ? Ss 0:00 _ postgres: logger 80262 ? Ss 0:00 _ postgres: checkpointer 80263 ? Ss 0:00 _ postgres: background writer 80264 ? Ss 0:00 _ postgres: walwriter 80265 ? Ss 0:00 _ postgres: autovacuum launcher 80266 ? Ss 0:00 _ postgres: stats collector 80267 ? Ss 0:00 _ postgres: autoprewarm master 80268 ? Ss 0:00 _ postgres: logical replication launcher |
By default, pg_prewarm will store a list of blocks which are currently in memory
on disk. After a crash or a restart, pg_prewarm will automatically restore the
cache as it was when the file was last exported.
In general, pg_prewarm makes most sense if your database and your RAM are really
really large (XXX GB or more). In such cases, the difference between cached
and uncached data will be greatest and users will suffer the most if
performance is bad.
If you want to learn more about performance and database tuning in general,
consider checking out my post about how to track down slow or time consuming
queries. You might also be interested in taking a look at
http://pgconfigurator.cybertec.at, which is a free website to help you with
database configuration.
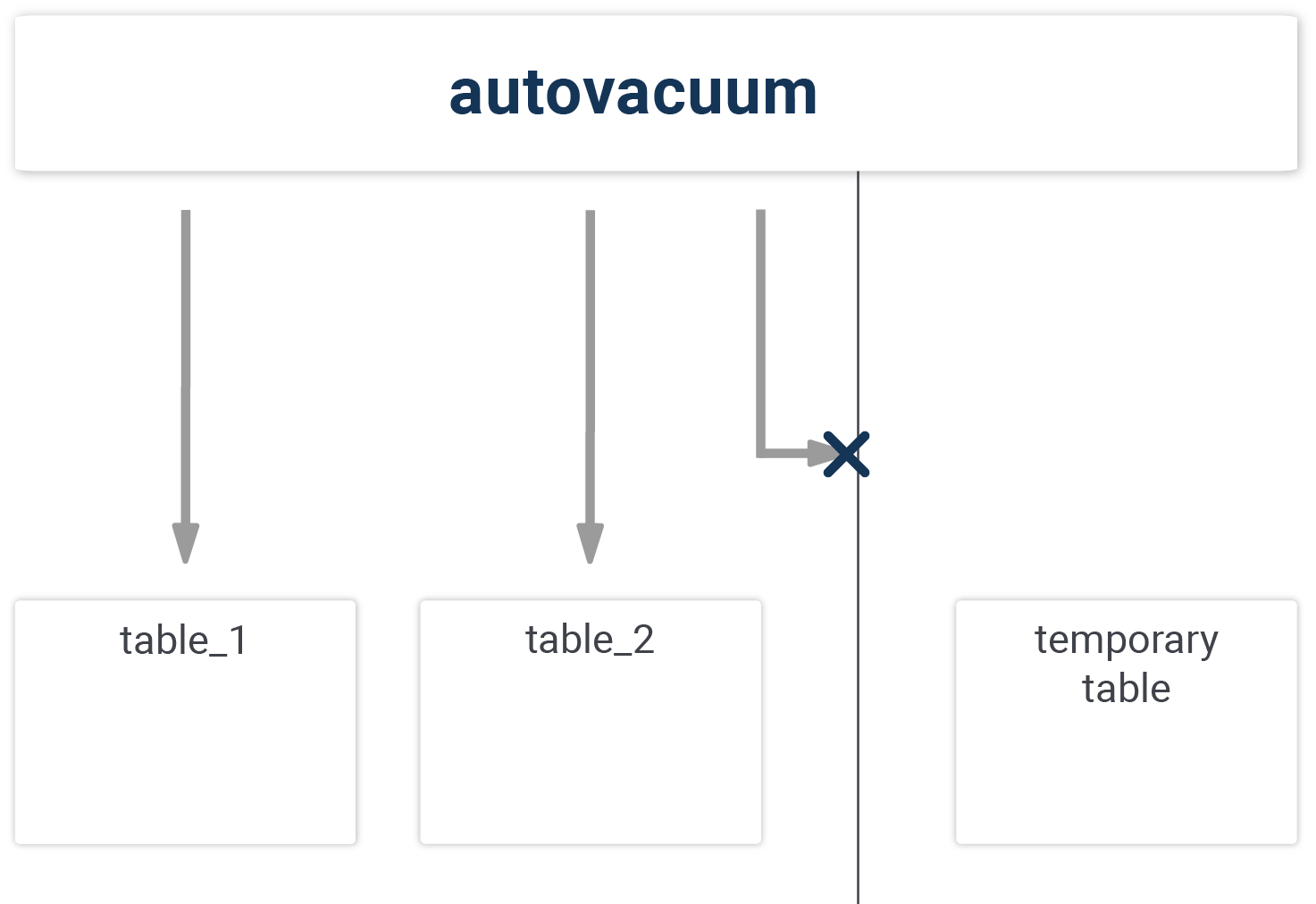
Did you know that your temporary tables are not cleaned up by autovacuum?
Since the days of PostgreSQL 8.0, the database has provided the miraculous autovacuum daemon which is in charge of cleaning tables and indexes. In many cases, the default configuration is absolutely ok and people don’t have to worry about VACUUM much. However, recently one of our support clients sent us an interesting request related to temporary tables and autovacuum.
The main issue is that autovacuum does not touch temporary tables. Yes, it’s true – you have to VACUUM temporary tables on your own. But why is this the case? Let’s take a look at how the autovacuum job works in general. Autovacuum sleeps for a minute and wakes up. After that it checks, if a table has seen a sufficiently large number of changes before it fires up a cleanup process. The important thing is that the cleanup process actually has to see the objects it will clean, and this is where the problem starts.
An autovacuum process has no way of seeing a temporary table, because temporary tables can only be seen by the database connection which actually created them. Autovacuum therefore has to skip temporary tables. Unfortunately, most people are not aware of this issue. As long as you don’t use your temporary tables for extended periods, the missing cleanup job is not an issue. However, if your temp tables are repeatedly changed in long transactions, it can become a problem.
The main question now is: How can we verify what I have just said? To show you what I mean, I will load the pgstattuple extension and create two tables-- a “real” one, and a temporary one:
|
1 2 3 4 5 6 7 8 |
test=# CREATE EXTENSION pgstattuple; CREATE EXTENSION test=# CREATE TABLE t_real AS SELECT * FROM generate_series(1, 5000000) AS id; SELECT 5000000 test=# CREATE TEMPORARY TABLE t_temp AS SELECT * FROM generate_series(1, 5000000) AS id; SELECT 5000000 |
|
1 2 3 4 |
test=# DELETE FROM t_real WHERE id % 2 = 0; DELETE 2500000 test=# DELETE FROM t_temp WHERE id % 2 = 0; DELETE 2500000 |
The tables will now contain around 50% trash each. If we wait sufficiently long, we will see that autovacuum has cleaned up the real table while the temporary one is still in jeopardy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
test=# x Expanded display is on. test=# SELECT * FROM pgstattuple('t_real'); -[ RECORD 1 ] ............---------------+-..--------- table_len | 181239808 tuple_count | 2500000 tuple_len | 70000000 tuple_percent | 38.62 dead_tuple_count | 0 dead_tuple_len | 0 dead_tuple_percent | 0 free_space | 80620336 free_percent | 44.48 test=# SELECT * FROM pgstattuple('t_temp'); -[ RECORD 1 ] --------------------+------------ table_len | 181239808 tuple_count | 2500000 tuple_len | 70000000 tuple_percent | 38.62 dead_tuple_count | 2500000 dead_tuple_len | 70000000 dead_tuple_percent | 38.62 free_space | 620336 free_percent | 0.34 |
The “real table” has already been cleaned and a lot of free space is available, while the temporary table still contains a ton of dead rows. Only a manual job will find the free space in all that jumble.
Keep in mind that VACUUM is only relevant if you really want to keep the temporary table for a long time. If you close your connection, the entire space will be automatically reclaimed anyway-- so there is no need to worry about dropping the table.
If you want to learn more about VACUUM in general, consider checking out one of our other blogposts. If you are interested in how VACUUM works, it also is definitely useful to read the official documentation, which can be found here.
Parallel queries were introduced back in PostgreSQL 9.6, and the feature has been extended ever since. In PostgreSQL 11 and PostgreSQL 12, even more functionality has been added to the database engine. However, there remain some questions related to parallel queries which often pop up during training and which definitely deserve some clarification.
To show you how the process works, I have created a simple table containing just two columns:
|
1 2 3 4 5 6 7 |
test=# CREATE TABLE t_test AS SELECT id AS many, id % 2 AS few FROM generate_series(1, 10000000) AS id; SELECT 10000000 test=# ANALYZE; ANALYZE |
The "many" column contains 10 million different entries. The "few" column will contain two different ones. However, for the sake of this example, all reasonably large tables will do.
The query we want to use to show how the PostgreSQL optimizer works is pretty simple:
|
1 2 3 4 5 6 7 8 |
test=# SET max_parallel_workers_per_gather TO 0; SET test=# explain SELECT count(*) FROM t_test; QUERY PLAN ------------------------------------------------------------------------ Aggregate (cost=169248.60..169248.61 rows=1 width=8) -> Seq Scan on t_test (cost=0.00..144248.48 rows=10000048 width=0) (2 rows) |
The default configuration will automatically make PostgreSQL go for a parallel sequential scan; we want to prevent it from doing that in order to make things easier to read.
Turning off parallel queries can be done by setting the max_parallel_workers_per_gather variable to 0. As you can see in the execution plan, the cost of the sequential scan is estimated to be 144.248. The cost of the total query is expected to be 169.248. But how does PostgreSQL come up with this number? Let’s take a look at the following listings:
|
1 2 3 4 5 6 |
test=# SELECT pg_relation_size('t_test') AS size, pg_relation_size('t_test') / 8192 AS blocks; size | blocks -----------+-------- 362479616 | 44248 (1 row) |
The t_test table is around 350 MB and consists of 44.248 blocks. Each block has to be read and processed sequentially. All rows in those blocks have to be counted to create the final results. The following formula will be used by the optimizer to estimate the costs:
|
1 2 3 4 5 6 7 8 |
test=# SELECT current_setting('seq_page_cost')::numeric * 44248 + current_setting('cpu_tuple_cost')::numeric * 10000000 + current_setting('cpu_operator_cost')::numeric * 10000000; ?column? ------------- 169248.0000 (1 row) |
As you can see, a couple of parameters are being used here: seq_page_cost tells the optimizer the cost of reading a block sequentially. On top of that, we have to account for the fact that all those rows have to travel through the CPU (cpu_tuple_cost) before they are finally counted. cpu_operator_cost is used because counting is basically the same as calling "+1" for every row. The total cost of the sequential scan is therefore 169.248 which is exactly what we see in the plan.
The way PostgreSQL estimates sequential scans is often a bit obscure to people end during database training here at Cybertec many people ask about this topic. Let’s therefore take a look at the execution plan and see what happens:
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# SET max_parallel_workers_per_gather TO default; SET test=# explain SELECT count(*) FROM t_test; QUERY PLAN ------------------------------------------------------------------------------------ Finalize Aggregate (cost=97331.80..97331.81 rows=1 width=8) -> Gather (cost=97331.58..97331.79 rows=2 width=8) Workers Planned: 2 -> Partial Aggregate (cost=96331.58..96331.59 rows=1 width=8) -> Parallel Seq Scan on t_test (cost=0.00..85914.87 rows=4166687 width=0) (5 rows) |
As you can see, PostgreSQL decided on using two CPU cores. But how did PostgreSQL
come up with this part? "rows=4166687"
The answer lies in the following formula:
10000048.0 / (2 + (1 - 0.3 * 2)) = 4166686.66 rows
10.000.048 rows is the number of rows PostgreSQL expects to be in the table (as
determined by ANALYZE before). The next thing is that PostgreSQL tries to
determine how much work has to be done by one core. But what does the formula
actually mean?
estimate = estimated_rows / (number_of_cores + (1 - leader_contribution * number_of_cores)

The leader process often spends quite some effort contributing to the result.
However, we assume that the leader spends around 30% of its time servicing the
worker processes. Therefore the contribution of the leader will go down as the
number of cores grows. If there are 4 or more cores at work, the leader will not
make a meaningful contribution to the scan anymore-- so PostgreSQL will simply
calculate the size of the tables by the number of cores, instead of using the
formula just shown.
Other parallel operations will use similar divisors to estimate the amount of
effort needed for those operations. Bitmap scans and so on work the same way.
If you want to learn more about PostgreSQL and if you want to know how to speed
up CREATE INDEX, consider checking out our blog post.
Many of you might have wondered why some system views and monitoring statistics in PostgreSQL can contain incomplete query strings. The answer is that in PostgreSQL, it's a configuration parameter that determines when a query will be cut off: track_activity_query_size. This blog post explains what this parameter does and how it can be used to its greatest advantage.
Some system views and extensions will show you which queries are currently running (pg_stat_activity) or which ones have eaten up the most time in the past (pg_stat_statements). Those system views are super important: I can strongly encourage you to make good use of this vital information. However, many of you might have noticed that queries are sometimes cut off prematurely. There are some important reasons for premature query cut off: in PostgreSQL, the content of both views comes from a shared memory segment which is not dynamic for reasons of efficiency. Therefore PostgreSQL allocates a fixed chunk of memory which is then used. If the query you want to look at does not fit into this piece of memory, it will be cut off. There is not much you can do about it apart from simply increasing track_activity_query_size so that everything you need is there.
The question is now: What is the best value to use when adjusting track_activity_query_size? There is no clear answer to this question. As always: it depends on your needs. If you happen to use Hibernate or some other ORM, I find a value around 32k (32.786 bytes) quite useful. Some other ORMs (Object Relational Mappers) will need similar values so that PostgreSQL can expose the entire query in a useful way.

You have to keep in mind that there is no such thing as a free lunch. If you increase track_activity_query_size in postgresql.conf the database will allocate slightly more than "max_connections x track_activity_query_size" bytes at database startup time to store your queries. While increasing the memory allocation of "track_activity_query_size" is surely a good investment on most systems you still have to be aware of this issue to avoid excessive memory usage. On a big system the downside of not having the data is usually larger, however. I therefore recommend always changing this parameter in ordner to see what is going on on your servers.
As stated before PostgreSQL uses shared memory (or mapped memory depending on your system) to store these kind of statistics. For that reason, PostgreSQL cannot dynamically change the size of the memory segment. Changing track_activity_query_size therefore also requires you to restart PostgreSQL which can be pretty nasty on a busy system. That's why it makes sense to have the parameter already correctly set when the server is deployed.
If you are unsure how to configure postgresql.conf in general check out our config generator which is available online on our website. If you want to find out more about PostgreSQL security we also encourage you to take a look at our blog post about pg_permissions.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.