Looking at the type of PostgreSQL support requests, we have received recently, it is striking to see, how many of them are basically related to autovacuum and UPDATE in particular. Compared to other databases such as Oracle, PostgreSQL’s way of handling UPDATE and storage in general is quite different. Therefore people moving from Oracle to PostgreSQL might be surprised. So it can make sense to take a step back and take a look at the broader picture: Here is our beginners guide on UPDATE and autovacuum in PostgreSQL.
Table of Contents
The most important thing beginners have to keep in mind is: Internally UPDATE will duplicate a row. After an UPDATE the old as well as the new row will be in your table. But why is that the case? Here is an example:
|
1 2 3 4 |
BEGIN; UPDATE tab SET id = 17 WHERE id = 16; SELECT … ROLLBACK; |
The idea is simple: UPDATE is not allowed to destroy the old version of the row because otherwise ROLLBACK would not work. UPDATE has to copy the row and ensure that both versions are there to handle transactions properly.
Let us assume that the table will contain a single row (id = 16):
| Connection 1 | Connection 2 |
| SELECT * FROM tab; | SELECT * FROM tab; |
| ... returns 16 ... | ... returns 16 ... |
| BEGIN; | |
| UPDATE tab SET id = 20 WHERE id = 16 | |
| SELECT * FROM tab; | SELECT * FROM tab; |
| ... returns 20 ... | ... returns 16 ... |
| COMMIT; |
Note that the second SELECT in the second connection will still see the old row. PostgreSQL has to ensure that the row is still there.
The same applies to DELETE: If your disk is full, deleting 100 million rows will not automatically return space to the filesystem because some concurrent transactions might still use the data.
As stated already, DELETE does not actually remove old rows. Who does? The answer is: VACUUM.
| Connection 1 | Connection 2 | Connection 3 |
| BEGIN; | ||
| DELETE FROM tab; | ||
| ... running ... | SELECT * FROM tab; | |
| ... running ... | ... will return all the rows ... | |
| VACUUM; | ||
| COMMIT; | ... does not delete anything ... | |
| VACUUM; | ||
| ... space can be reclaimed ... |
The important thing in this example is: The first VACUUM is not allowed to remove dead rows already because there are still transactions, which can see those rows, which are about to be deleted. In short: Even when you are trying to run VACUUM like crazy, it does not necessarily reclaim space because long running transactions will delay the cleanup.
Long transactions can delay cleanup and cause table bloat.
It is also worth pointing out that VACUUM does NOT necessarily shrink the table on disk anymore but simply marks space in a way that it can be reused later on. Therefore keeping a close eye on long transactions is crucial. One way to take care of long transaction is to simply kill them if they are not active for a certain period of time: idle_in_transaction_session_timeout can be pretty helpful in this case.
VACUUM is very important and to make life as simple as possible, PostgreSQL does a lot of vacuum by itself. The autovacuum daemon periodically checks (usually once a minute) if tables are in need of VACUUM. In case something has to be done, a process is launched to cleanup a table.
Note that those automatic VACUUM processes are not running at full speed to ensure that running transactions are not affected. Running VACUUM on a table manually will therefore “feel” faster than autovacuum, which is of course only related to the default configuration.
In 90% of all cases autovacuum does a perfect job and cleans out tables just the way it should be. However, there are cases, in which things can turn out to be a problem.
In most cases autovacuum is exactly what you want. However, there are also some very special cases, which users should be aware of - imagine the following situation:
In this case, all ingredients for disaster are there: The long reads will make sure that VACUUM cannot do its job and remove dead rows in time, which in turn will lead to table bloat. Your tables will simply grow beyond proportion. Of course a larger table will make VACUUM take longer and longer and longer. At some point the situation is not under control anymore and the tables in your database will simply explode. We have recently seen cases, where a table containing only a couple of millions of rows has exploded to the staggering size of 4.5 TB.
Needless to say, such an explosion does have a real impact on performance. Remember: Not even running more aggressive VACUUM on such a table will really fix the situation because VACUUM will simply mark space as reusable – in most cases space is not going to be returned to the filesystem.
VACUUM FULL has to lock the table while the table is being rebuilt, which essentially means “downtime”. Running at 50.000 transactions a second implies that downtime is not really an option. Therefore we have spent some time on working on a tool to allow for in place reorganization without extensive table locking: pg_squeeze is able to do exactly that >>.
In general, the default configuration is somewhat ok, unless you are running countless UPDATE statements. In this case it can be beneficial to configure autovacuum more aggressively and combine it with pg_squeeze as well as some other means of keeping table bloat under control.
UPDATE all togetherSome applications we have seen recently use UPDATE statements to change the current position of a person or a vehicle. Suppose you want to track your pizza delivery and you want to know exactly where your pizza is at the moment. There might be thousands of Pizza deliveries going on at the same time and each driver might send his or her GPS position every couple of seconds. The result would be thousands of updates on a fairly small amount of data, which can lead to the bloat issues I have explained earlier on.
One way to approach the problem is to use INSERT instead of UPDATE. Yes, you heard that right – why not just keep the entire history? Now, what kind of logic is that? Let us think again: UPDATE will duplicate the row anyway so storage wise there is no real difference between INSERT and UPDATE – in both cases you will be left with one more row on disk.
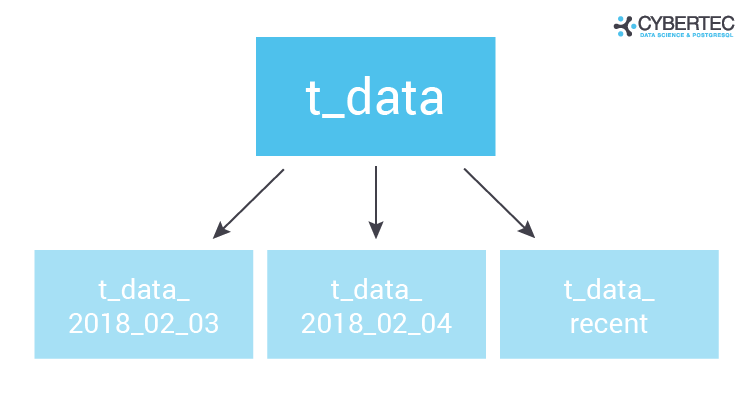
The beauty of INSERT is that you will eventually have the history of the entire track, which can be put to good use (BI people love this kind of timeseries data). But how does cleanup work then? The idea is to use a time-partitioned table and simply use “DROP TABLE” to clean out data. DROP TABLE has some very nice advantages over DELETE / VACUUM and UPDATE / VACUUM: The nice thing is that DROP TABLE will simply delete data files on disk, which is very fast.
Dear Hans,
Firstly, thank you for the article.
Secondly, I think you are describing postgresql MVCC concept while talking that
UPDATEin postgres doesn't change existing but creates new one. The MVCC will work the same way creating new snapshot while removing (DROP) partitioned data and if there is active session (with active transaction) for that snapshot it wont be removed until transaction is completed. Am I right? If yes the suggested option to haveINSERTs and partitioned table still is not advantageous and it is relevant havingUPATEproblem in shape of keeping snapshots until released transactions. (Note I am not counting the importance of keeping data for business)Regards,