UPDATED July 2024: Most people who use PostgreSQL database systems are aware of this fact: The database engine must send changes to the so-called “Write Ahead Log” (= WAL). That is to ensure that in case of a crash, the database will be able to recover to a consistent state safely and reliably. However, not everybody knows that tuning the database server will actually have an impact on the amount of WAL which Postgres writes to disk. This is due to Postgres' use of checkpoints.
Table of Contents
PostgreSQL must write changes to the WAL (or xlog as some call it) before those changes even make it to the underlying data files. In most cases PostgreSQL will simply log what has to be changed in the data files. All in all it can be said: It must write much much more.
To ensure that the WAL will not grow infinitely, PostgreSQL creates checkpoints. These are a perfect opportunity to recycle WAL. The size of your transaction should be more or less constant, so cleaning up WAL from time to time is an absolute must. Fortunately checkpointing is done automatically.
By default, PostgreSQL uses the following parameters to determine when a checkpoint is supposed to happen:
# checkpoint_timeout = 5min # range 30s-1h
# max_wal_size = 1GB
# min_wal_size = 80MB
These default settings are somewhat ok for a reasonable small database. However, for a big system, having fewer checkpoints will help to increase performance. Setting max_wal_size to, say, 20GB is definitely a good thing to do if your system is reasonably large and heavily loaded (writes).
What is widely known is the distance between two checkpoints. It does not only improve speed due to reduced checkpointing – fewer checkpoints will also have an impact on the amount of transaction log written.
Increasing the distance between checkpoints leads to less WAL - but why does that actually happen? Remember: The whole point of having the transaction log in the first place, is to ensure that the system will always survive a crash. Applying these changes in the WAL to the data files will fix the data files and recover the system at startup. To do that safely, PostgreSQL cannot simply log the changes made to a block – in case a block is changed for THE FIRST TIME after a checkpoint, the entire page has to be sent to the WAL. All subsequent changes can be incremental. The point now is: If checkpoints are close together there are many “first times” and full pages have to be written to the WAL quite frequently. If checkpoints are far apart the number of full page writes will drop dramatically leading to a lot less WAL.
On heavily loaded systems we are not talking about peanuts – the difference can be quite significant.
To measure how much transaction log the system actually produces during a normal benchmark, I have conducted a simple test using empty database instances:
|
1 2 3 4 |
[hs@linuxpc db]$ createdb test [hs@linuxpc db]$ psql test psql (9.6.1) Type 'help' for help. |
To reduce the number of disk flushes and to give my SSD a long and prosperous life, I set synchronous_commit to off:
|
1 2 |
test=# ALTER DATABASE test SET synchronous_commit TO off; ALTER DATABASE |
|
1 2 3 4 5 6 7 8 9 10 |
[hs@linuxpc db]$ pgbench -i test NOTICE: table 'pgbench_history' does not exist, skipping NOTICE: table 'pgbench_tellers' does not exist, skipping NOTICE: table 'pgbench_accounts' does not exist, skipping NOTICE: table 'pgbench_branches' does not exist, skipping creating tables... 100000 of 100000 tuples (100%) done (elapsed 0.09 s, remaining 0.00 s) vacuum... set primary keys... done. |
100.000 rows are absolutely enough to conduct this simple test.
Then 4 concurrent connections will perform 2 million transactions each.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[hs@linuxpc db]$ time pgbench -c 4 -t 2000000 test starting vacuum...end. transaction type: scaling factor: 1 query mode: simple number of clients: 4 number of threads: 1 number of transactions per client: 2000000 number of transactions actually processed: 8000000/8000000 latency average = 0.558 ms tps = 7173.597623 (including connections establishing) tps = 7173.616874 (excluding connections establishing) real 18m35.222s user 2m23.980s sys 3m4.830s |
|
1 2 3 4 5 |
test=# SELECT pg_size_pretty(pg_current_wal_lsn() - '0/00000000'::pg_lsn); pg_size_pretty ---------------- 3447 MB (1 row) |
However, what happens if the checkpoint distances are decreased dramatically?
|
1 2 3 |
checkpoint_timeout = 30s max_wal_size = 32MB min_wal_size = 32MB |
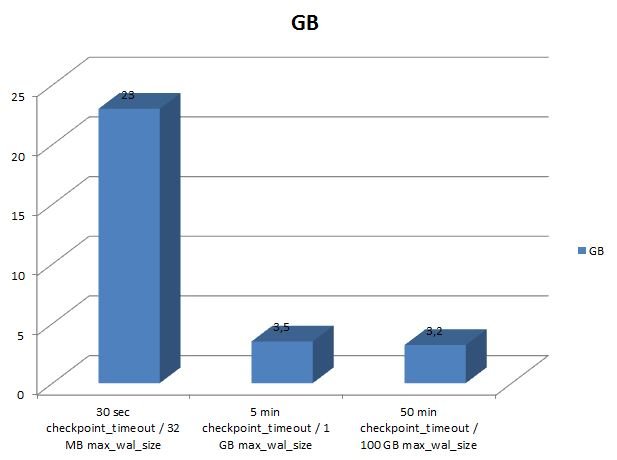
The amount of WAL will skyrocket because checkpoints are so close that most changes will be a “first change” made to a block. Using these parameters, the WAL will skyrocket to staggering 23 GB. As you can see the amount of WAL can easily multiply if those settings are not ideal.
Increasing the distance between checkpoints will certainly speed things up and have a positive impact on the WAL volume:
In case you need any assistance, please feel free to contact us.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
Thank you for the great explanation! I am having trouble understanding one thing though - "The amount of WAL will skyrocket because checkpoints are so close that most changes will be a “first change” made to a block." What does the "first change" to a block actually mean here?
pg_current_xlog_location() function does not exists anymore.
it looks pg_current_wal_lsn() is the equilent
Thanks, I updated the code.