PostgreSQL contains some hidden gems which have been around for many years and help to silently speed up your queries. They optimize your SQL statements in a clever and totally transparent way. One of those hidden gems is the ability to synchronize sequential scans. Actually, this feature has been around for 15+ years, but has gone mostly unnoticed by many end-users. However, if you are running data warehouses and analytical workloads, you might have already used synchronized seq scans without actually knowing it.
Table of Contents
Before we draw any conclusions, it is necessary to understand the problem we’re trying to solve in the first place. Consider the following scenario: 10 users are concurrently running analytics on a large table. For the sake of simplicity, we assume that the size of the table is 1 TB and we can read 1 GB / second. In case there is just 1 user, we can get read data in around 17 minutes (assuming there is zero caching). But what if people are reading the table concurrently and if there is still zero caching, because those reads are spread all over the PostgreSQL table? In that case, we face a problem:
| Number of users | MB / second | Time |
| 1 | 1000 | 16.6 minutes |
| 2 | 500 | 33.2 minutes |
| 4 | 250 | 67 minutes |
| 10 | 100 | 166 minutes |
Assuming that the overall throughput is a constant (which of course it is not - especially not on spinning disks) we really have a big problem.
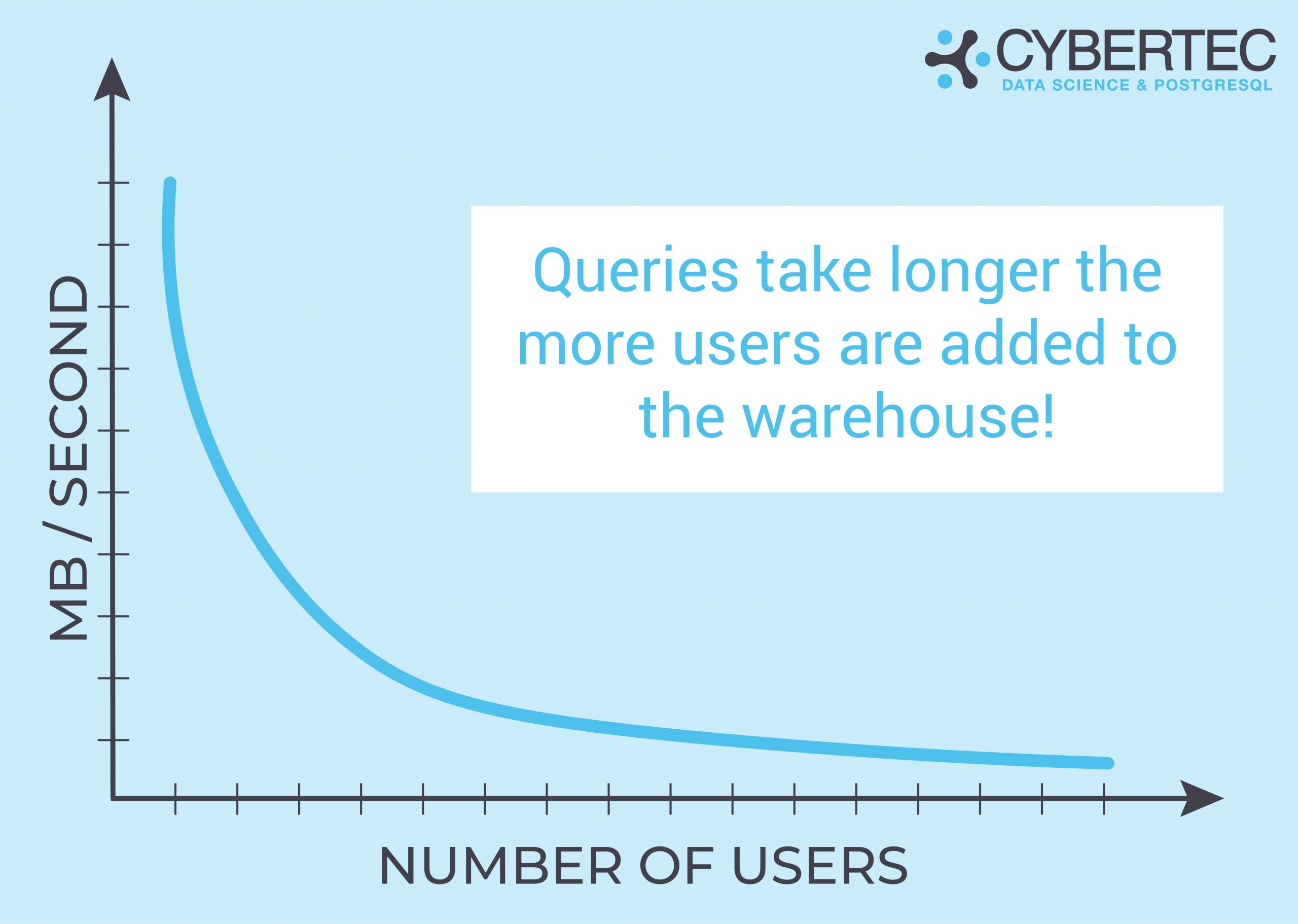
What is important to understand is that queries take longer and longer as more users are added to your warehouse.
Synchronized sequential scans have been around for many years and are a good way to reduce I/O. Let’s take a look at a picture explaining the solution to the problems we face in many data warehouses:
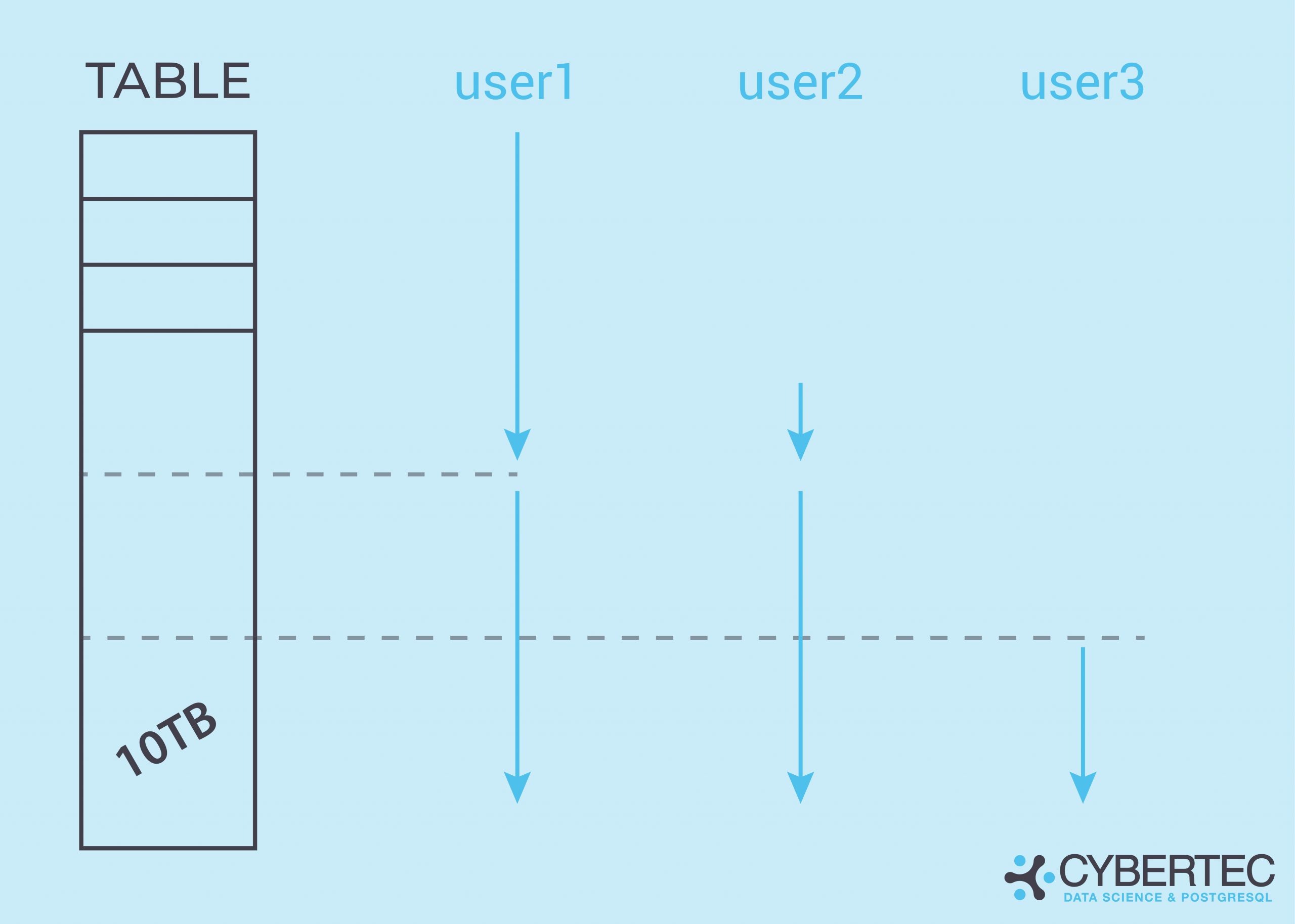
Suppose query 1 starts a sequential scan on the table. After it has read 4TB, a second query also needs to perform a sequential scan. Instead of starting at the beginning, the second query can start reading the table at the current position of query 1. The idea is to serve both sequential scans with a single I/O request. The scans proceed in lock step until they reach the end of the table, then the second scan continues reading at the start of the table until it has read the data it missed in the beginning.
More users can be added as needed. By keeping the scans together, I/O can be reduced dramatically in many cases - especially if the amount of data is really large. What is important to note here is that PostgreSQL synchronizes the scans once, but does not force them to stay together. If one of the scans is significantly slower than the other one, the scans won’t stick together, but will go separate ways, to make sure that neither scan is forced to execute slowly.
However, since data warehousing and analytics in general are often I/O bound, we’ve got a good chance to see better performance.
To control this behavior, PostgreSQL offers the following variable:
|
1 2 3 4 5 |
demo=# SHOW synchronize_seqscans; synchronize_seqscans ---------------------- on (1 row) |
By default, synchronize_seqscans is on, which is a good value. However, if you want to change the default behavior, it is possible to change the value in postgresql.conf.
If you want to learn more about PostgreSQL performance tuning, consider checking out our blog about improving PostgreSQL’s ability to handle time series.
In case you need help to run your database in the most efficient way possible, CYBERTEC offers 24x7 support services to customers around the world.
Leave a Reply