Many PostgreSQL database users might have stumbled over the effective_cache_size parameter in postgresql.conf. But how can it be used to effectively tune the database and how can we speed up PostgreSQL using effective_cache_size? This blog will hopefully answer some of my readers' questions and reveal the hidden power of this secretive setting.
Table of Contents
A lot has been written about RAM, PostgreSQL, and operating systems (especially Linux) over the years. However, to many memory usage is still a mystery and it makes sense to think about it when running a production database system. Let's take a look at a simple scenario and see how memory might be used on a modern server. For the sake of simplicity, let's assume that our server (or VM - virtual machine, ed.) provides us with 100 GB of RAM. 2 GB might be taken by the operating system including maybe some cron jobs, monitoring processes and so on. Then you might have assigned 20 GB of memory to PostgreSQL in the form of shared buffers (=PostgreSQL's I/O cache). In total PostgreSQL might need 25 GB of memory to run in this case. On top of those 20 GB it will take some memory to sort data, keep database connections around and keep some other vital information in mapped memory.
The question is now: What happens to the remaining 73 GB of RAM? The answer is: Some of it might be "free" and available but most of it will end up as filesystem cache. Whenever Linux does I/O and in case enough free memory is around the filesystem cache will kick in and try to cache the data to avoid disk I/O if possible. The filesystem is vital and can be changed in size dynamically as needed. If PostgreSQL needs more RAM to, say, sort data, it will allocate memory which in turn makes the operating system shrink the filesystem cache as needed to ensure efficiency.
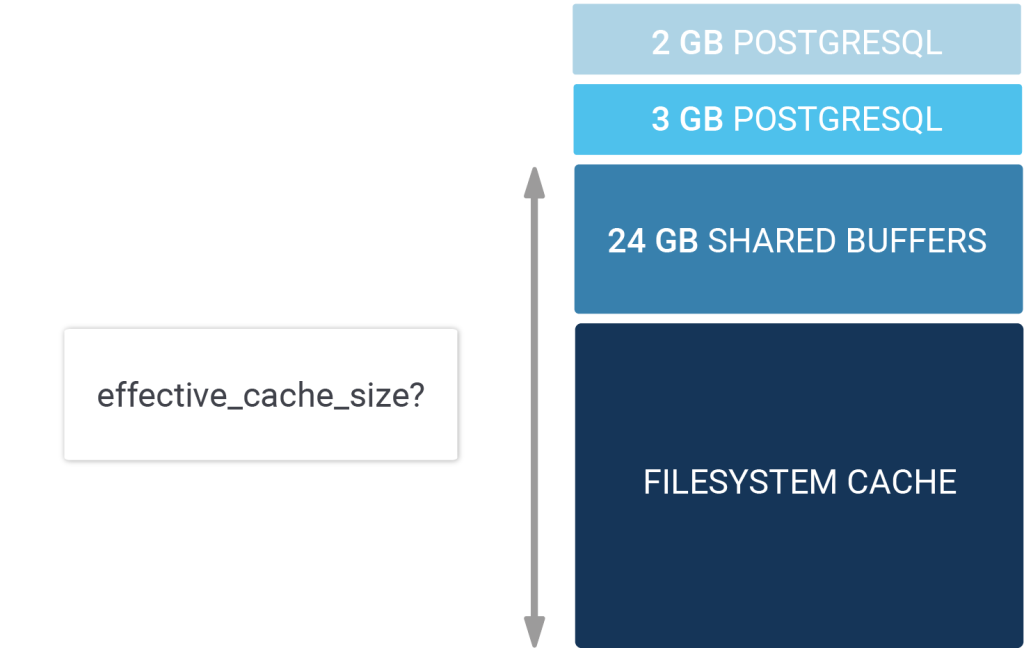
The PostgreSQL optimizer is in charge of making sure that your queries are executed in the most efficient way possible. However, to do that it makes sense to know how much RAM there is really around. The system knows about the size if its own memory (= shared_buffers) but what about the filesystem cache? What about your RAID controller and so on? Wouldn't it be cool if you the optimizer knew about all those ressources?
That is exactly what effective_cache_size is all about. It helps the planner to determine how much cache there really is and helps to adjust the I/O cache. Actually,
the explanation I am giving here is already longer than the actual C code in the server. Let's take a look at costsize.c and see what the comment says there:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
* We also use a rough estimate "effective_cache_size" of the number of * disk pages in Postgres + OS-level disk cache. (We can't simply use * NBuffers for this purpose because that would ignore the effects of * the kernel's disk cache.) * * Obviously, taking constants for these values is an oversimplification, * but it's tough enough to get any useful estimates even at this level of * detail. Note that all of these parameters are user-settable, in case * the default values are drastically off for a particular platform. So how is this information really used? Which costs are adjusted? And how is this done precisely? * index_pages_fetched * Estimate the number of pages actually fetched after accounting for * cache effects. * * We use an approximation proposed by Mackert and Lohman, "Index Scans * Using a Finite LRU Buffer: A Validated I/O Model", ACM Transactions * on Database Systems, Vol. 14, No. 3, September 1989, Pages 401-424. * The Mackert and Lohman approximation is that the number of pages * fetched is * PF = * min(2TNs/(2T+Ns), T) when T b and Ns b and Ns > 2Tb/(2T-b) * where * T = # pages in table * N = # tuples in table * s = selectivity = fraction of table to be scanned * b = # buffer pages available (we include kernel space here) * * We assume that effective_cache_size is the total number of buffer pages * available for the whole query, and pro-rate that space across all the * tables in the query and the index currently under consideration. (This * ignores space needed for other indexes used by the query, but since we * don't know which indexes will get used, we can't estimate that very well; * and in any case counting all the tables may well be an overestimate, since * depending on the join plan not all the tables may be scanned concurrently.) * * The product Ns is the number of tuples fetched; we pass in that * product rather than calculating it here. "pages" is the number of pages * in the object under consideration (either an index or a table). * "index_pages" is the amount to add to the total table space, which was * computed for us by query_planner. |
This code snippet taken directly from costsize.c in the core is basically the only place in the optimizer which takes effective_cache_size into account. As you can see, the formula is only used to estimate the costs of indexes. In short: If PostgreSQL knows that a lot of RAM is around, it can safely assume that fewer pages have to come from disk and more data will come from the cache, which allows the optimizer to make indexes cheaper (relativ to a sequential scan). You will notice that this effect can only be observed if your database is sufficiently large. On fairly small databases you will not observe any changes in execution plans.
However, the PostgreSQL query optimizer is not the only place that checks effective_cache_size. Gist index creation will also check the parameter and
adjust its index creation strategy. The idea is to come up with the buffering strategy during index creation.
If you want to learn more about PostgreSQL memory parameters you can find out more in our post about about work_mem and sort performance.
Hans - thanks for the writeup. Orthogonal question here - what are you thoughts on allocating most of the system RAM for the Shared buffer instead of relying on the file system cache? I would assume it is more efficient to fetch data that is already in the shared buffer than data that is in the file system cache (since an extra content switch will be involved here). However postgres guidelines do not recommend this approach.
Comparing this paragraph:
Then you might have assigned 20 GB of memory to PostgreSQL in the form of shared buffers (=PostgreSQL’s I/O cache). In total PostgreSQL might need 25 GB of memory to run in this case. On top of those 20 GB it will take some memory to sort data, keep database connections around and keep some other vital information in mapped memory.
And the chart below, I was wondering if the 20 GB and 25 GB mentionned into the text might be replaced by the 24 GB allocated to the
shared_buffersin the chart?If these are different elements, is it possible to clarify the different space definitions?
Thanks in advance,