Table of Contents
I recently investigated a surprising behavior of the DBeaver database client in connection with PostgreSQL parallel query, which I'd like to share with you. This might be interesting for everybody who accesses PostgreSQL using the JDBC driver.
Parallel query was introduced in PostgreSQL 9.6 and has been improved in later versions. It breaks with the “traditional” PostgreSQL architecture of using a single backend process per database connection to process SQL statements. If the optimizer thinks that parallel processing would reduce the execution time, it will plan additional parallel worker processes. These processes are created by the query executor and live only for the duration of a single SQL statement. The parallel worker processes calculate intermediate results, which eventually are collected at the original backend process. This collection happens in the “Gather” node of the execution plan: PostgreSQL executes all steps below the Gather node in parallel, while everything above Gather is single-threaded.
While parallel query can speed up query execution, it incurs some overhead:
The PostgreSQL optimizer takes this overhead into account by planning parallel query only expensive statements that process large tables or indexes. There are some additional limits to prevent parallel query from consuming too many resources:
max_parallel_workers limits the number of parallel workers for the entire database cluster at any given timemax_parallel_workers_per_gather limits the number of parallel workers that a single statement can useIf the pool defined by max_parallel_workers is exhausted, the query executor cannot start all the parallel processes that the optimizer planned.
This brief introduction is far from exhaustive. For more information, read the PostgreSQL documentation and our articles about parallel query optimization, parallel DDL, parallel aggregate or the interaction of parallel query and SERIALIZABLE isolation.
The query I will use to demonstrate the problem is a simple query that counts the number of rows in a table with 5 million rows. PostgreSQL plans a parallel sequential scan on the table:
|
1 2 3 4 5 6 7 8 9 |
EXPLAIN (COSTS OFF) SELECT count(*) FROM bar; QUERY PLAN ════════════════════════════════════════════ Finalize Aggregate -> Gather Workers Planned: 2 -> Partial Aggregate -> Parallel Seq Scan on bar |
Using DBeaver, I can use EXPLAIN (ANALYZE) to verify that the executor actually launches the parallel worker processes:
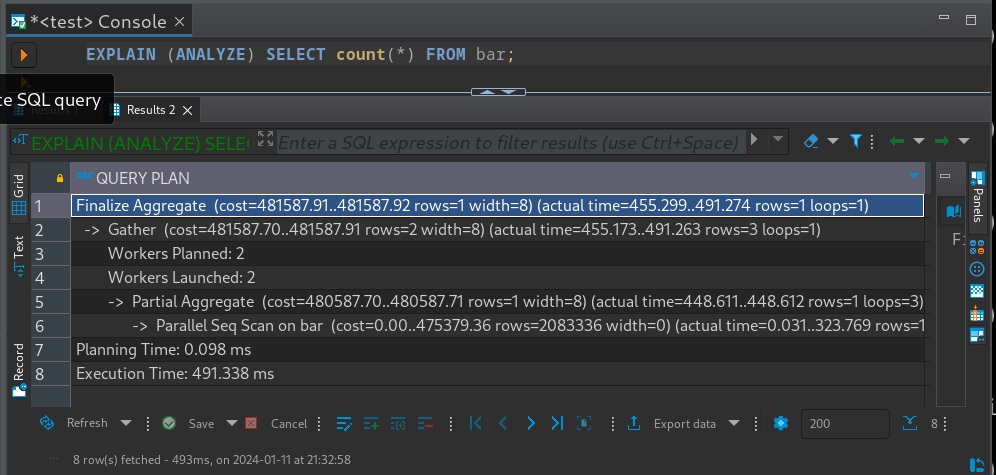
But running the query in DBeaver actually takes much longer than the 491 milliseconds. That is strange, because EXPLAIN (ANALYZE) adds notable overhead to the execution of a statement! To find out what actually happens on the server, I use the auto_explain extension to collect the actual execution plan in the PostgreSQL server log:
|
1 2 3 4 5 6 7 8 |
LOG: duration: 712.369 ms plan: Query Text: SELECT count(*) FROM bar Finalize Aggregate (...) (actual time=712.361..712.363 rows=1 loops=1) -> Gather (...) (actual time=712.355..712.356 rows=1 loops=1) Workers Planned: 2 Workers Launched: 0 -> Partial Aggregate (...) (actual time=712.354..712.354 rows=1 loops=1) -> Parallel Seq Scan on bar (...) (actual time=0.006..499.970 rows=5000000 loops=1) |
PostgreSQL didn't start any parallel workers, so the query had to execute single-threaded. That explains the longer duration. But what kept PostgreSQL from starting parallel workers? The first suspicion would be that the pool of max_parallel_workers was exhausted. But no other queries are running on this server! Time to dig deeper.
The PostgreSQL documentation has a chapter on the limitations of parallel query. For example, most data modifying statements don't support parallel query. Also, queries that use PARALLEL UNSAFE functions or are executed in a cursor cannot use parallel query. But none of these limitations can affect us here, because then the optimizer wouldn't have planned parallel workers at all. The problem must occur during the execution of the query.
At the very end of the page, we find the following limitation:
Even when parallel query plan is generated for a particular query, there are several circumstances under which it will be impossible to execute that plan in parallel at execution time. [...]
- The client sends an Execute message with a non-zero fetch count. See the discussion of the extended query protocol. Since libpq currently provides no way to send such a message, this can only occur when using a client that does not rely on libpq.
Ha! Looks like we have struck gold. DBeaver uses the JDBC driver to access PostgreSQL, which does not use libpq to access PostgreSQL.
You can see a description of the “execute” message mentioned above in the PostgreSQL documentation. The final argument is the fetch count. The PostgreSQL JDBC driver uses that feature to implement the method setMaxRows(int), available in java.sql.Statement (and inherited by java.sql.PreparedStatement and java.sql.CallableStatement).
This simple Java program reproduces the problem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public class Parallel { public static void main(String[] args) throws ClassNotFoundException, java.sql.SQLException { Class.forName('org.postgresql.Driver'); java.sql.Connection conn = java.sql.DriverManager.getConnection( 'jdbc:postgresql://127.0.0.1:5432/test?user=xxx&password=xxx' ); java.sql.Statement stmt = conn.createStatement(); stmt.setMaxRows(200); java.sql.ResultSet rs = stmt.executeQuery('SELECT count(*) FROM bar'); rs.next(); System.out.println(rs.getString(1)); rs.close(); stmt.close(); conn.close(); } } |
If you set the row limit to 0 (the default), the problem goes away.
The remaining piece of the puzzle is to figure out how to configure the row count limit in DBeaver. After some digging in the documentation, I found that the answer was right before my eyes when I looked at the “Data Editor” pane:
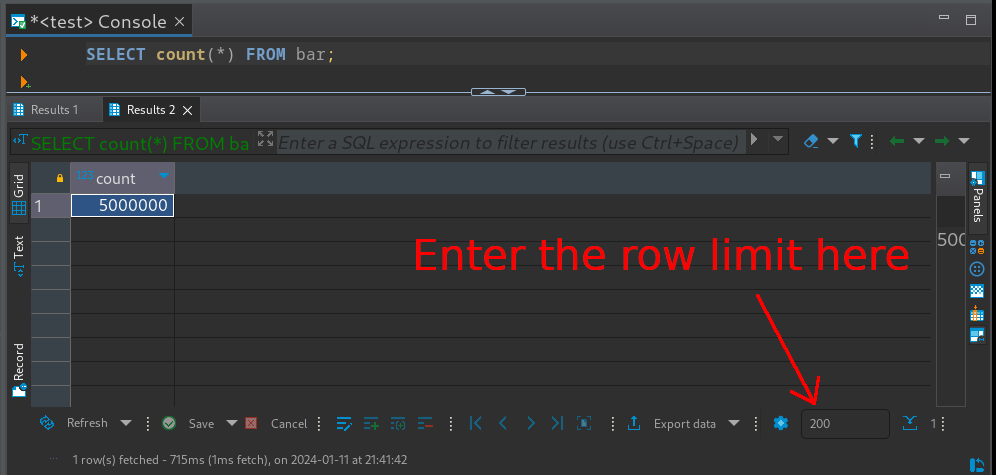
All you have to do is to change the limit to 0! Alternatively, you can click the “blue flower” left of the row limit to bring up the “Properties” dialog. There you can change the ”ResultSet fetch size” in the ”Data Editor” properties. If you want to change the setting for good, switch to the “Global settings” in the top right corner.
Once you change the setting, PostgreSQL will start parallel workers as desired.
Sure you can: use the LIMIT clause rather than setMaxRows(). This query can use parallel workers:
|
1 2 3 4 5 6 7 8 9 10 |
EXPLAIN (COSTS OFF) SELECT count(*) FROM bar LIMIT 200; QUERY PLAN ══════════════════════════════════════════════════ Limit -> Finalize Aggregate -> Gather Workers Planned: 2 -> Partial Aggregate -> Parallel Seq Scan on bar |
The difference between LIMIT and setMaxRows() is that the former is known at query planning time, while the latter only at query execution time. In the above query, the optimizer knows that the LIMIT is applied after the Gather node, when there is no more parallelism. The executor doesn't know that, so it disables parallelism to be on the safe side. There is another reason why it is better to use LIMIT: if the optimizer knows that you only need the first couple of result rows, it can choose a plan that yields those first rows quickly rather than optimizing for the whole result set.
The default configuration of DBeaver uses java.sql.Statement.setMaxRows(int) to limit the size of a result set to 200. This triggers a little known limitation in PostgreSQL that prevents it from starting parallel worker processes. The problem is easy to avoid by setting the limit to 0, once you have understood what's going on.
Use LIMIT at query planning time rather than a row count at execution time if you want parallelism.
Leave a Reply