Hello there, this is your developer speaking...
Table of Contents
I'm struggling with how to start this post, since I've procrastinated a lot. There should be at least 5 published posts on this topic already. But there is only one by Hans-Jürgen Schönig. I'm thanking him for trying to cover my back, but the time has come!
Well, that's a tricky question. We've started working on pg_timetable a year ago, aiming our own targets. Then we've found out that this project might be interesting for other people and we opened it.
Soon we received some feedback from users and improved our product. There were no releases and versions at that time. But suddenly, we faced a situation where you cannot grow or fix anything vital, until you introduce changes in your database schema. Since we are not a proprietary project anymore, we must provide back-compatibility for current users.
Precisely at this time, you understand that there is a need for releases (versions) and database migrations to the new versions.
Major versions usually change the internal format of system tables and data representation. That's why we go for the new major version 2, considering the initial schema as version 1.
This means that, if you have a working installation of the pg_timetable, you will need to use --upgrade command-line option, but don't forget to make a backup beforehand.
So what are those dramatic changes?
How scheduling information was stored before:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE timetable.chain_execution_config ( ... run_at_minute INTEGER, run_at_hour INTEGER, run_at_day INTEGER, run_at_month INTEGER, run_at_day_of_week INTEGER, ... ); |
Turned out, it's incredibly inconvenient to store schedules one job per line because of the UI. Consider this simple cron syntax:
0 */6 * * * which stands for "every 6th hour".
So in the old model, it will produce 4 rows for hours 6, 12, 18, 24.
It's not a problem for the database itself to store and work with a large number of rows. However, now if a user wants to update the schedule, he/she either must update each entrance row by row or delete old rows and insert new ones.
So we've come out with the new syntax:
|
1 2 3 4 5 6 7 |
CREATE DOMAIN timetable.cron AS TEXT CHECK(...); CREATE TABLE timetable.chain_execution_config ( ... run_at timetable.cron, ... ); |
To be honest, these guys are the main reasons why we've changed the database schema. 🙂
If a job is marked as @reboot, it will be executed once after pg_timetable connects to the database or after connection reestablishment.
This kind of job is useful for initialization or for clean-up actions. Consider to remove leftovers from the unfinished tasks, e.g., delete downloaded or temporary files, clean tables, reinitialize schema, etc. One may rotate the log of the previous session, backup something, send logs by email.
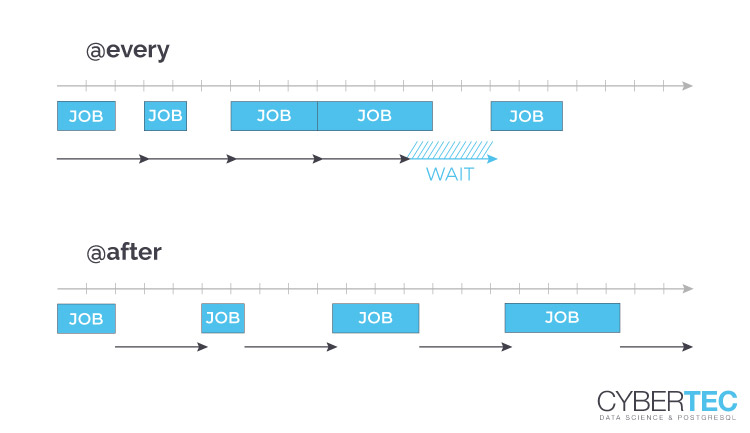
@every and @after are interval tasks, meaning they are not scheduled for a particular time but will be executed repeatedly. The syntax consists of the keyword (@every or @after) followed by proper interval type value.
The only difference is that @every task will be repeated within at equal intervals of time. In contrast, @after task will repeat itself in an interval only after the previous job was finished. See the figure below for details.
Here is the list of possible syntaxes:
|
1 2 3 4 5 6 7 8 9 |
SELECT '* * * * *' :: timetable.cron; SELECT '0 1 1 * 1' :: timetable.cron; SELECT '0 1 1 * 1,2,3' :: timetable.cron; SELECT '0 * * 0 1-4' :: timetable.cron; SELECT '0 * * * 2/4' :: timetable.cron; SELECT '*/2 */2 * * *' :: timetable.cron; SELECT '@reboot' :: timetable.cron; SELECT '@every 1 hour 30 sec' :: timetable.cron; SELECT '@after 30 sec' :: timetable.cron; |
We've added a startup option that forbids the execution of shell tasks. The reason is simple. If you are in a cloud deployment, you probably won't like shell tasks.
Ants Aasma, Cybertec expert:
Linux container infrastructure is basically taking a sieve and trying to make it watertight. It has a history of security holes. So unless you do something like KubeVirt, somebody is going to break out of the container.
Even with KubeVirt, you have to keep an eye out for things like Spectre that can break through the virtualization layer.
It's not the database we are worried about in this case. It's other people's databases running on the same infrastructure.
Starting on this release, we will provide you with pre-built binaries and packages. Currently, we build binaries:
We consider including our packages into official Yum and Apt PostgreSQL repositories.
And last but not least! Continuous testing was implemented using GitHub Actions, meaning all pull requests and commits are checked automatically to facilitate the development and integration of all kinds of contributors.
Cheers!
Leave a Reply