pgbouncer is one of the most widely used tool for connection pooling. At CYBERTEC, we've successfully deployed it in many different situations. It has proven to be reliable as well as useful.
Table of Contents
Before we dive into different pooling modes and their implications, why do we need a connection pooler in the first place? The reason is that we want to reduce the overhead of new connections. That is right. Creating new connections is not free of charge.
As stated already, connections and their creation are not free. In PostgreSQL, we have to fork an entire process to create a connection. In case a connection lives for a very long time, this is no problem. However, forking a process for just a very short query can be really expensive. Those costs are often underestimated by developers and DBAs alike.
Let's run a test using a simple script:
|
1 2 |
HansJurgensMini:~ hs$ cat /tmp/sample.sql SELECT 1; |
To maximize the result, I've used the most basic script possible.
Let's run a simple test: 10 seconds, 10 concurrent transactions given our SQL script. Test hardware: Mac Mini (M1).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
HansJurgensMini:~ hs$ pgbench -c 10 -T 10 -j 10 -f /tmp/sample.sql test starting vacuum...end. transaction type: /tmp/sample.sql scaling factor: 1 query mode: simple number of clients: 10 number of threads: 10 maximum number of tries: 1 duration: 10 s number of transactions actually processed: 2957846 number of failed transactions: 0 (0.000%) latency average = 0.034 ms initial connection time = 5.708 ms tps = 295825.128043 (without initial connection time) |
This gave us 295825 transactions per second. But now let's run the same test again. This time, each transaction will open a separate connection (-C):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
HansJurgensMini:~ hs$ pgbench -c 10 -T 10 -j 10 -f /tmp/sample.sql -C test starting vacuum...end. transaction type: /tmp/sample.sql scaling factor: 1 query mode: simple number of clients: 10 number of threads: 10 maximum number of tries: 1 duration: 10 s number of transactions actually processed: 37713 number of failed transactions: 0 (0.000%) latency average = 2.652 ms average connection time = 2.439 ms tps = 3770.311424 (including reconnection times) |
Wow, we reduced the speed to 3770 transactions per second which is a 98.7% drop in performance.
It's logical if you think about it. “SELECT 1” is way cheaper than fork() plus all the other overhead. Therefore pooling makes a lot of sense, because it allows us to recycle the connection.
pgbouncer can enter the picture to address the problem. The key here is that a pgbouncer connection has only 2 Kb or so in overhead. In other words, it is really efficient, and it can hold thousands of connections for very little overhead. Sure, there is a bit more latency - but overall it helps to greatly reduce the need to open and close connections.
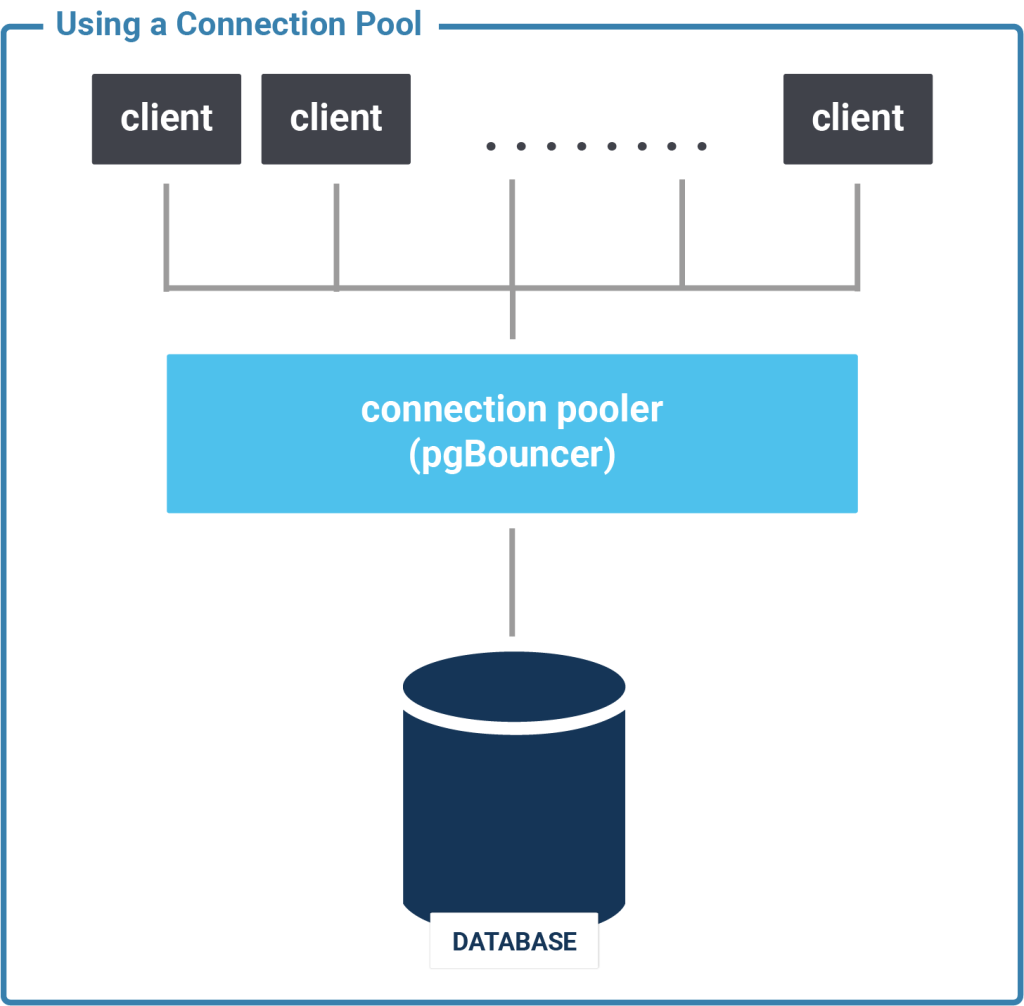
pgbouncer will sit between the database and the client. It will keep connections to the database open and make sure that the number of fork() calls needed is significantly reduced.
pgbouncer has three types of pooling modes. This is important to understand because it offers a lot of potential to adjust the tool’s behavior to our exact needs.
The config file shows the following options:
|
1 2 3 4 5 |
;; When server connection is released back to pool: ;; session - after client disconnects (default) ;; transaction - after transaction finishes ;; statement - after statement finishes pool_mode = session |
What do all those options mean? Let's discuss it in detail.
Session pooling means that pgbouncer keeps a set of connections to the server open. The clients will pick one and things will be routed through to the database.
It is also possible to use pgpool to “narrow down” the number of connections really needed on the database side. This can be useful in case you have some crazy application-side connection pool which needs an unusually high number of open connections which should not make it to the backend database in the first place.
In case all connections are working, some of them have to wait until a slot in the pool is available. Often many applications using a connection pool access the same database. Many apps running pools that are too large might end up with far too many connections in the backend - which can in turn cause issues.
Every client will run the entire transaction and even the entire connection on the same “real” database connection.
Sometimes a full connection is too much. So what about transaction pooling? Instead of mapping an entire client connection to a real database connection, it is enough to ensure that the same transaction will end up on the same host.
pgbouncer will therefore map many client connections to the same physical connection and separate them by transaction. Often this is entirely sufficient.
Statement pooling is by far the most aggressive method. Often you don't need large transaction blocks. Suppose you want to look up names in a phone book 1 million times per second. Clearly those are quick, small queries and there are no large transactions spanning multiple statements. We therefore don’t have to worry about transactional visibility. We can simply load balance all those statements to any connection and pass the result on to the client.
The use case is as follows: Pump millions of short statements through the system which are not related to some large fancy business logic that needs heavy locking (e.g. SELECT FOR UPDATE) or anything of that kind.
Depending on your needs, you can decide on the pooling method you want to use. Typically, session pooling is used, but we have also seen large-scale statement pooling out there.
If you want to know more about authentication with pgbouncer, check out Laurenz Albe's blog, pgbouncer Authentication Made Easy.
Also, you can check out our pgbouncer blog archive.
You can download pgbouncer for free from pgbouncer.org:
In addition to reducing the repeated connetion overhead, pgBouncer's capability to put the incoming connection into a queue and multiplex it over very limited database connection is the best feature I love.
So effectively hundreds of application connection can be served by very few database connections.
Hi, I think you are wrong about statement pooling. Statement pooling forbids multi-statement transactions. And... that's all. Not very useful, you don't get more performance compared to statement pooling.
Unless I missed something. But I asked Peter Eisentraut one or two years ago, and AFAIR he confirmed this.
Best regards,
Frédéric
I think you wanted to say "compared with transaction pooling".
True, if all your transactions are single statements, transaction pooling is effectively statement pooling and should perform about the same.
You can still have multi-statement transactions in statement pooling mode if you put them inside a single database function, but I agree that statement pooling is not very useful.
Hi Laurenz,
Indeed, I meant "compared with transaction pooling".
Thank you for your reply (and all your great blog posts).
I think the comment "narrowing down" the number of connections is meant to apply to transaction pooling, not session pooling. With session pooling, each app connection is going to become a real backend connection, and so an app that opens a huge connection pool is going to need that same number of connections on the database.
Transaction pooling is where you can really have more live app connections to pgBouncer than from pgBouncer to the database, since any app connection that isn't actively running a transaction doesn't require a real db connection.