Just like in most databases, in PostgreSQL a trigger is a way to automatically respond to events. Maybe you want to run a function if data is inserted into a table. Maybe you want to audit the deletion of data, or simply respond to some UPDATE statement. That is exactly what a trigger is good for. This post is a general introduction to triggers in PostgreSQL. It is meant to be a tutorial for people who want to get started programming them.
Table of Contents
Writing a trigger is easy. The first important thing you will need is a table. A trigger is always associated with a table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
test=# CREATE TABLE t_temperature ( id serial, tstamp timestamptz, sensor_id int, value float4 ); CREATE TABLE test=# d t_temperature Table 'public.t_temperature' Column | Type | Collation | Nullable | Default -----------+--------------------------+-----------+----------+------------------------------------------- id | integer | | not null | nextval('t_temperature_id_seq'::regclass) tstamp | timestamp with time zone | | | sensor_id | integer | | | value | real | | | |
The goal of this example is to check the values inserted and silently “correct” them if we think that the data is wrong. For the sake of simplicity, all values below zero will be set to -1.
If you want to define a trigger, there are two things which have to be done:
In the following section you will be guided through that process.
Before we get started, let’s first take a look at CREATE TRIGGER:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
test=# h CREATE TRIGGER Command: CREATE TRIGGER Description: define a new trigger Syntax: CREATE [ OR REPLACE ] [ CONSTRAINT ] TRIGGER name { BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] } ON table_name [ FROM referenced_table_name ] [ NOT DEFERRABLE | [ DEFERRABLE ] [ INITIALLY IMMEDIATE | INITIALLY DEFERRED ] ] [ REFERENCING { { OLD | NEW } TABLE [ AS ] transition_relation_name } [ ... ] ] [ FOR [ EACH ] { ROW | STATEMENT } ] [ WHEN ( condition ) ] EXECUTE { FUNCTION | PROCEDURE } function_name ( arguments ) where event can be one of: INSERT UPDATE [ OF column_name [, ... ] ] DELETE TRUNCATE URL: https://www.postgresql.org/docs/15/sql-createtrigger.html |
URL: https://www.postgresql.org/docs/15/sql-createtrigger.html
The first thing you can see is that a trigger can be executed BEFORE or AFTER. But “before” and “after” what? Well, if you insert a row, you can call a function before or after its insertion. If you call the function before the actual insertion, you can modify the row before it finds its way to the table. In case of an AFTER trigger, the trigger function can already see the row which has just been inserted - the data is already inserted.
The following image shows where to insert a trigger:
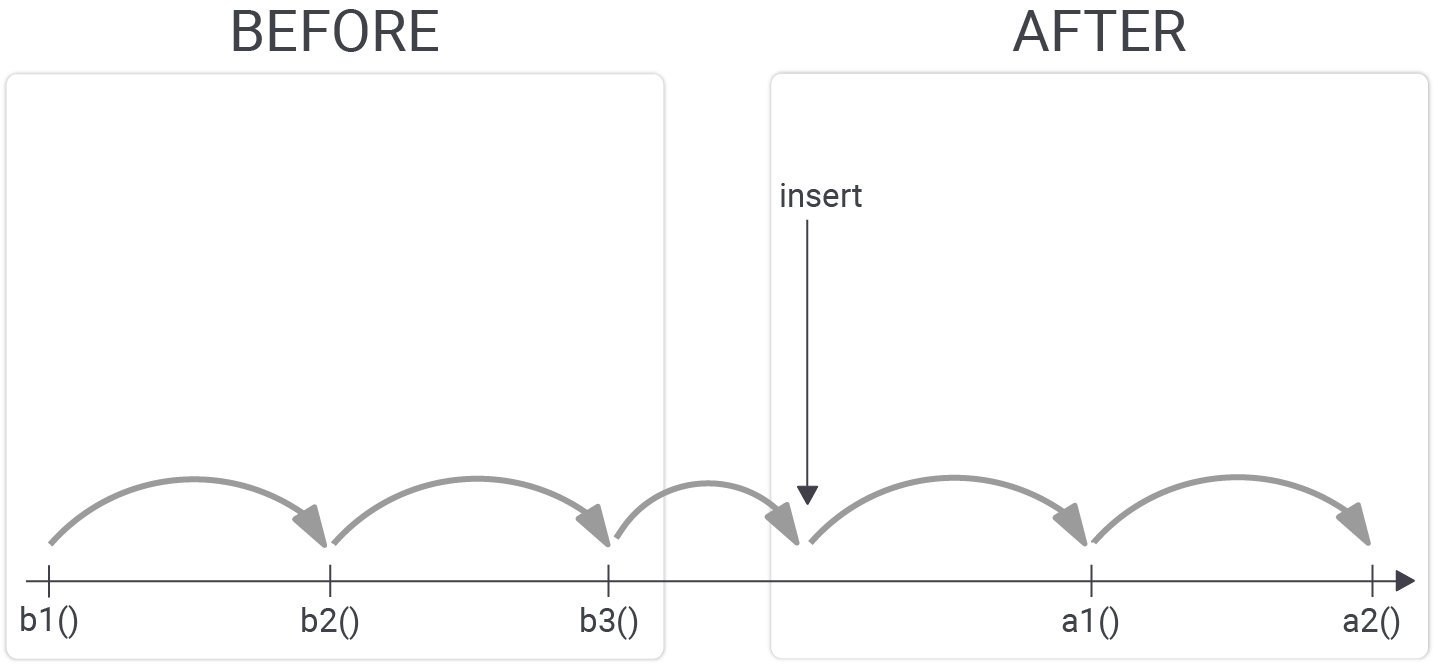
Basically, you can have as many BEFORE and as many AFTER triggers as you like. The important thing is that the execution order of the triggers is deterministic (since PostgreSQL 7.3). Triggers are always executed ordered by name. In other words, PostgreSQL will execute all BEFORE triggers in alphabetical order, do the actual operation, and then execute all AFTER triggers in alphabetical order.
Execution order is highly important, since it makes sure that your code runs in a deterministic order. To see how this plays out, let’s take a look at a practical example.
As stated before, we want to change the value being inserted in case it is negative. To do that, I have written an easy to understand function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE OR REPLACE FUNCTION f_temp () RETURNS trigger AS $ DECLARE BEGIN RAISE NOTICE 'NEW: %', NEW; IF NEW.value < 0 THEN NEW.value := -1; RETURN NEW; END IF; RETURN NEW; END; $ LANGUAGE 'plpgsql'; |
What we see here is this NEW variable. It contains the current row the trigger has been fired for. We can easily access and modify this variable, which in turn will modify the value which ends up in the table.
NOTE: If the function returns NEW, the row will be inserted as expected. However, if you return NULL, the operation will be silently ignored. In case of a BEFORE trigger the row will not be inserted.
The next step is to create a trigger and tell it to call this function:
|
1 2 3 |
CREATE TRIGGER xtrig BEFORE INSERT ON t_temperature FOR EACH ROW EXECUTE PROCEDURE f_temp(); |
Our trigger will only fire on INSERT (shortly before it happens). What is also noteworthy here: In PostgreSQL, a trigger on a table can fire for each row or for each statement. In most cases, people use row level triggers and execute a function for each row modified.
Once the code has been deployed we can already test it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# INSERT INTO t_temperature (tstamp, sensor_id, value) VALUES ('2021-05-04 13:23', 1, -196.4), ('2021-06-03 12:32', 1, 54.5) RETURNING *; NOTICE: NEW: (4,'2021-05-04 13:23:00+02',1,-196.4) NOTICE: NEW: (5,'2021-06-03 12:32:00+02',1,54.5) id | tstamp | sensor_id | value ----+------------------------+-----------+------- 4 | 2021-05-04 13:23:00+02 | 1 | -1 5 | 2021-06-03 12:32:00+02 | 1 | 54.5 (2 rows) INSERT 0 2 |
In this example two rows are inserted. One row is modified - the second one is taken as it is. In addition to that, our trigger issues two log messages so that we can see the content of NEW.
The previous example focuses on INSERT and therefore the NEW variable is readily available. However, if you want to write a trigger handling UPDATE and DELETE, the situation is quite different. Depending on the operation, different variables are available:
In other words: If you want to write a trigger for UPDATE, you have full access to the old as well as the new row. In case of DELETE you can see the row which is about to be deleted.
So far we have seen NEW and OLD - but there is more.
PostgreSQL offers a variety of additional predefined variables which can be accessed inside a trigger function. Basically, the function knows when it has been called, what kind of operation it is called for, and so on.
Let's take a look at the following code snippet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE OR REPLACE FUNCTION f_predefined () RETURNS trigger AS $ DECLARE BEGIN RAISE NOTICE 'NEW: %', NEW; RAISE NOTICE 'TG_RELID: %', TG_RELID; RAISE NOTICE 'TG_TABLE_SCHEMA: %', TG_TABLE_SCHEMA; RAISE NOTICE 'TG_TABLE_NAME: %', TG_TABLE_NAME; RAISE NOTICE 'TG_RELNAME: %', TG_RELNAME; RAISE NOTICE 'TG_OP: %', TG_OP; RAISE NOTICE 'TG_WHEN: %', TG_WHEN; RAISE NOTICE 'TG_LEVEL: %', TG_LEVEL; RAISE NOTICE 'TG_NARGS: %', TG_NARGS; RAISE NOTICE 'TG_ARGV: %', TG_ARGV; RAISE NOTICE ' TG_ARGV[0]: %', TG_ARGV[0]; RETURN NEW; END; $ LANGUAGE 'plpgsql'; CREATE TRIGGER trig_predefined BEFORE INSERT ON t_temperature FOR EACH ROW EXECUTE PROCEDURE f_predefined('hans'); INSERT INTO t_temperature (tstamp, sensor_id, value) VALUES ('2025-02-12 12:21', 2, 534.4); |
As you can see, there are various TG_* variables. Let’s take a look at them and see what they contain:
Let's run the code shown in the previous listing and see what happens:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
NOTICE: NEW: (8,'2025-02-12 12:21:00+01',2,534.4) NOTICE: TG_RELID: 98399 NOTICE: TG_TABLE_SCHEMA: public NOTICE: TG_TABLE_NAME: t_temperature NOTICE: TG_RELNAME: t_temperature NOTICE: TG_OP: INSERT NOTICE: TG_WHEN: BEFORE NOTICE: TG_LEVEL: ROW NOTICE: TG_NARGS: 1 NOTICE: TG_ARGV: [0:0]={hans} NOTICE: TG_ARGV[0]: hans NOTICE: NEW: (8,'2025-02-12 12:21:00+01',2,534.4) |
The trigger shows us exactly what's going on. That's important if you want to make your functions more generic. You can use the same function and apply it to more than just one table.
Triggers can do a lot more and it certainly makes sense to dig into this subject deeper to understand the inner workings of this important technique.
If you want to learn more about important features of PostgreSQL, you might want to check out one of my posts about sophisticated temporary tables which can be found here.
cool!