In recent years, streaming replication has been one of the major features introduced in PostgreSQL. The idea is to use the PostgreSQL transaction log (WAL) to synchronize an arbitrary number of services and to replicate data inside a cluster. In PostgreSQL replication can be made in two ways:
You can decide on which method is more beneficial to you according to your needs.
In the event of server failure and disaster, it is a good idea to have a standby / replica of your primary server within reach. Fortunately, PostgreSQL offers the means to achieve exactly that. Administrators can create read-only replicas of a primary server easily and use those replicas for various purposes such as:
Asynchronous is the standard way to replicate data in the PostgreSQL world and offers a reliable and easy way to distribute data and make your setups more failsafe.
The main advantages of asynchronous replication are a low overhead, simplicity, and robustness. As a result, asynchronous replication is the ideal solution for automatic failovers and enterprise-grade redundancies.
If you are running asynchronous replication, data might hit the standby AFTER a transaction has been committed on the primary server. There is usually a small replication delay, which can cause (usually) minor data loss in the case of a crash.
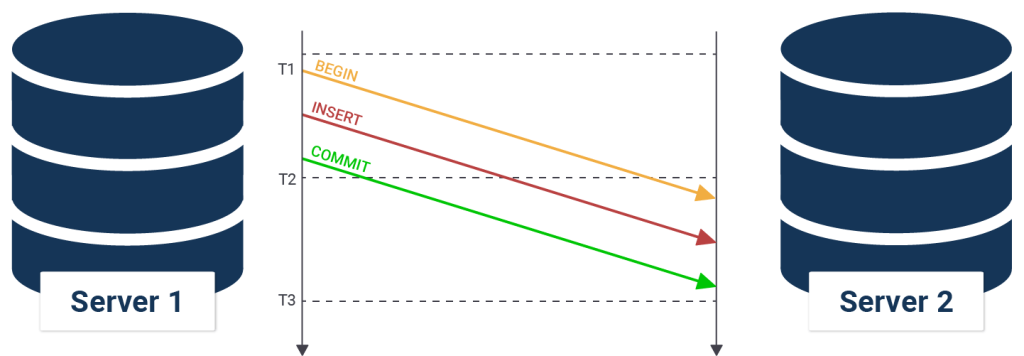
In most cases this is totally acceptable because asynchronous replication promises little overhead and does not slow down the primary.
In PostgreSQL, replication is not only possible from a primary to a single standby, it is also possible to replicate from a single primary to multiple standbys or to use standbys to replicate to even more standbys (cascaded replication). Cascading is especially useful if you are looking for a geographically distributed PostgreSQL replication solution.
Your main database server is based in New York, USA. You want to create replicas in Frankfurt, Stuttgart, Berlin and Aachen (Germany). If all your replicas are directly attached to the New York primary server, data have to be sent across the Atlantic Ocean four times. Cascaded replication is a good alternative. You could attach the Frankfurt server to the primary in the USA and dispatch data inside Germany from the Frankfurt server.
If you are not able to take the risk of losing a single COMMIT, synchronous replication might be what you are looking for. In PostgreSQL, you can replicate synchronously to as many standbys as you want to ensure that a COMMIT is only valid once it has been confirmed by the desired number of PostgreSQL servers.
Synchronous replication ensures the highest possible security for your transactions because a single crashing server can no longer cause data loss.
It ensures that no data can be lost. Here is how it works.
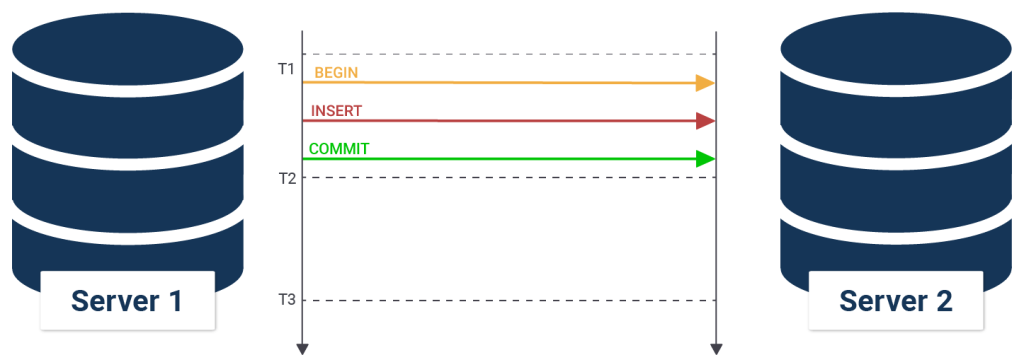
A transaction can return only if a sufficient number of standbys have confirmed the write.
With the introduction of PostgreSQL 10.0, even more sophisticated COMMIT methods are supported. One of the most noteworthy features is the ability to do “quorum COMMITs”.
FIRST num_sync (standby_name [, …]) ANY num_sync (standby_name [, …])
The idea is to give developers and administrators a more fine-grained way to configure replication.
If you are looking to set up streaming replication for PostgreSQL 13, this is the tutorial you have been looking for. We will show you how to configure PostgreSQL replication and how to set up your database servers quickly.

You want to know more about synchronous and asynchronous replication? Contact us today to receive your personal offer from CYBERTEC. We offer timely delivery, professional handling, and over 20 years of PostgreSQL experience.