The ability to run transactions is the core of every modern relational database system. The idea behind a transaction is to allow users to control the way data is written to PostgreSQL. However, a transaction is not only about writing – it is also important to understand the implications on reading data for whatever purpose (OLTP, data warehousing, etc.).
Table of Contents
One important aspect of transactions in PostgreSQL, and therefore in all other modern relational databases, is the ability to control when a row is visible to a user and when it is not. The ANSI SQL standard proposes 4 transaction isolation levels (READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ and SERIALIZABLE) to allow users to explicitly control the behavior of the database engine. Unfortunately, the existence of transaction isolation levels is still not as widely known as it should be. Therefore I decided to blog about this topic, to give more PostgreSQL users the chance to apply this very important, yet under-appreciated feature.
The two most commonly used transaction isolation levels are READ COMMITTED and REPEATABLE READ. In PostgreSQL READ COMMITTED is the default isolation level and should be used for normal OLTP operations. In contrast to other systems, such as DB2 or Informix, PostgreSQL does not provide support for READ UNCOMMITTED, which I personally consider to be a thing of the past anyway.
In READ COMMITTED mode, every SQL statement will see changes which have already been committed (e.g. new rows added to the database) by some other transactions. In other words: If you run the same SELECT statement multiple times within the same transaction, you might see different results. This is something you have to consider when writing an application.
However, within a statement the data you see is constant – it does not change. A SELECT statement (or any other statement) will not see changes committed WHILE the statement is running. Within an SQL statement, data and time are basically “frozen”.
In the case of REPEATABLE READ the situation is quite different: A transaction running in REPEATABLE READ mode will never see the effects of transactions committing concurrently – it will keep seeing the same data and offer you a consistent snapshot throughout the entire transaction. If your goal is to do reporting or if you are running some kind of data warehousing workload, REPEATABLE READ is exactly what you need, because it provides consistency. All pages of your report will see exactly the same set of data. There is no need to worry about concurrent transactions.
Digging through a theoretical discussion might not be what you are looking for. So let us take a look at a picture showing graphically how things work:
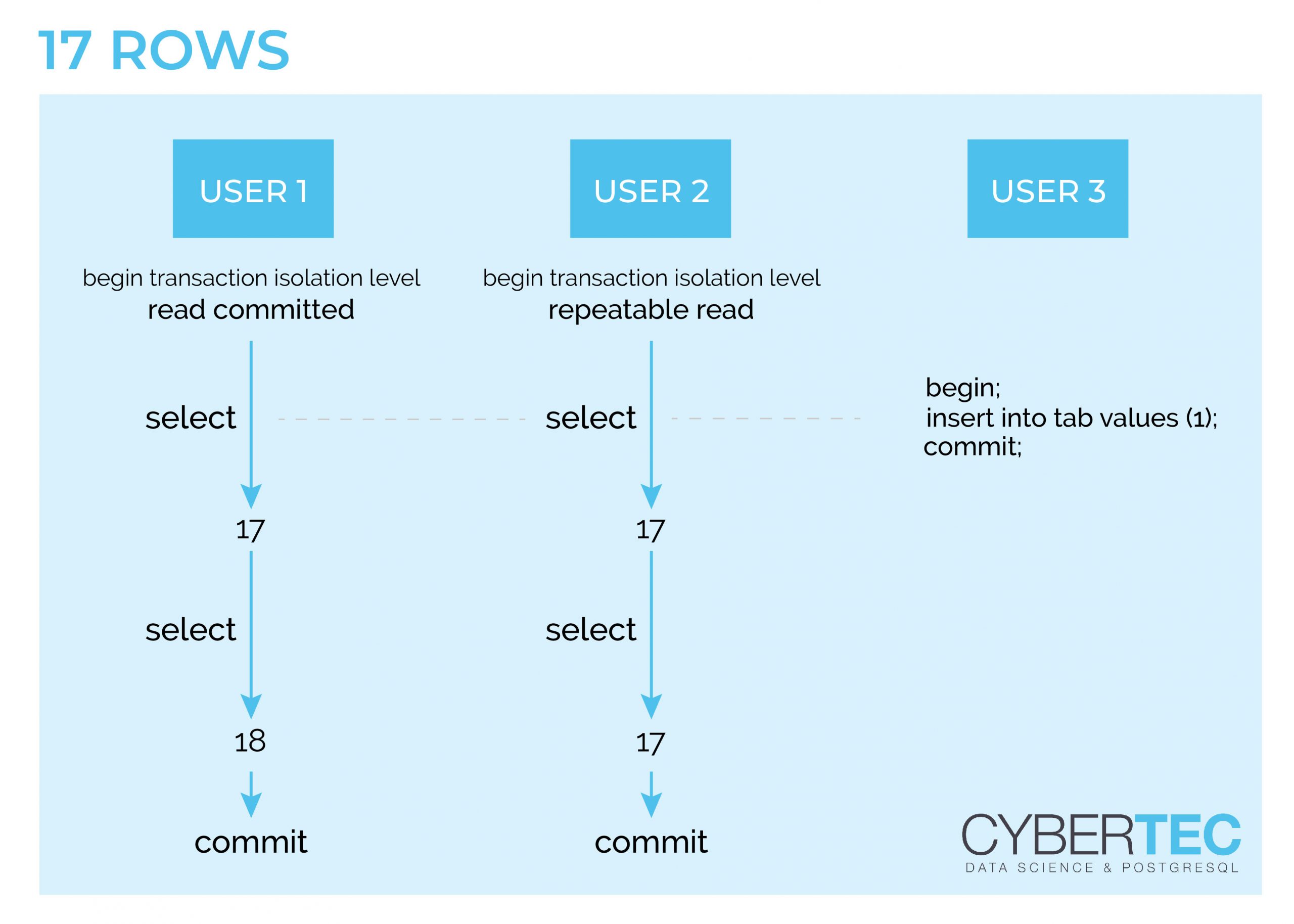
Let us assume that we have 17 rows in a table. In my example three transactions will happen concurrently. A READ COMMITTED, a REPEATABLE READ and a writing transaction. The write happens while our two reads execute their first SELECT statement. The important thing here: The data is not visible to concurrent transactions. This is a really important observation. The situation changes during the second SELECT. The REPEATABLE READ transaction will still see the same data, while the READ COMMITTED transaction will see the changed row count.
REPEATABLE READ is really important for reporting because it is the only way to get a consistent view of the data set even while it is being modified.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
Thank you for covering this. I like that you indicated that transactions control read visibility, not just write atomicity. This is a very important concept.
I suspect the reason why the standard includes the brainless mode UNREPEATABLE_READ was to allow commercial database to be standard compliant while implementing at least READ_COMMITTED.
Will transactions in REPEATABLE READ mode perform better over READ COMMITTED mode?
They will perform marginally better because there is no need to take a new snapshot for each statement.
On the down side, they will block autovacuum progress even if they don't modify data.
What about phantom reads in Repeatable Reads?
Yes, what about them? You won't see phantom reads in PostgreSQL under the
REPEATABLE READisolation level (even though that would not violate the SQL standard).Thank you for the article.
I have one question regarding inserts. If I have 2 concurrent transactions inserting the same row in the table. One transaction is READ_COMMITED and the other one is REPEATABLE_READ, why does the REPEATABLE_READ one wait for the first one to commit if it is insert.
Snapshots should not be visible to the transaction and in case of insert there should be no row lock. I'm trying to dig out is REPEATABLE_READ monitoring the current transaction (xi) while performing INSERT operations.
Thank you in advance, you have a very good blog and are a goto for a lot of info.
For everybody out there, we've worked with Cybertec and these guys are legit 🙂
BR,
Frane