PostgreSQL TDE is an Open Source version of PostgreSQL which encrypts data before storing it safely on disk. It’s therefore a more secure and thus a more enterprise-ready variation of the database. It is a part of CYBERTEC PostgreSQL Enterprise Edition (PGEE).
People often ask about the performance differences between encrypted and unencrypted PostgreSQL. To answer this question, we have conducted a comprehensive performance analysis to shed some light on this important topic, and to give users a way to compare various PostgreSQL settings and their performance. Our performance tests have been conducted using the following hardware and software components:
CPU: AMD Ryzen 5950X — 16 cores / 32 thread, 72MB cache, support for AES-NI
MEMORY: 64GB RAM — DDR4 2666 ECC dual channel
STORAGE: SSD Samsung 980 PRO — nvme, PCIe v4 ×4
simple lvm volume, XFS filesystem, exclusive use
OS: Linux Centos 7.9.2009, kernel 5.10.11-1.el7.elrepo.x86_64
PostgreSQL: postgresql13-13.1-3PGDG.rhel7.x86_64 from PGDG repo
PostgreSQL 13.1 TDE: built locally with the standard compile options used for PGDG packages using base GCC 4.8.5 20150623 (Red Hat 4.8.5-44)
PostgreSQL 13.1 TDE: built locally with the standard compile options used for PGDG packages using software collection devtoolset-9 GCC 9.3.1 20200408 (Red Hat 9.3.1-2) and -march=znver2
Since results were performed on a solid-state drive without proper TRIM management, the second version of all these analysis is being prepared, with proper TRIM (-o discard mount option) and scales adjusted to better emphasize the impact of a data set on available memory:
Other params and tooling will be the same.
All tests were performed locally using a freshly initialized, empty cluster (fresh initdb). Therefore caching effects on the PostgreSQL-side are not relevant.
The following configurations were tested:
Note that we did not just compare standard PostgreSQL with PostgreSQL TDE, but also tried various compiler versions. You will find out that the compiler does indeed have a major impact, which might come as a surprise to many.
The following PostgreSQL configuration has been used (postgresql.conf). These variables have been determined using the CYBERTEC configurator:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
max_connections = 100 unix_socket_directories = '/var/run/postgresql' port = 15432 shared_preload_libraries = 'pg_stat_statements' shared_buffers = 16GB work_mem = 64MB maintenance_work_mem = 620MB effective_cache_size = 45GB effective_io_concurrency = 100 huge_pages = try track_io_timing = on track_functions = pl wal_level = logical max_wal_senders = 10 synchronous_commit = on checkpoint_timeout = '15 min' checkpoint_completion_target = 0.9 max_wal_size = 1GB min_wal_size = 512MB wal_compression = on wal_buffers = -1 wal_writer_delay = 200ms wal_writer_flush_after = 1MB bgwriter_delay = 200ms bgwriter_lru_maxpages = 100 bgwriter_lru_multiplier = 2.0 bgwriter_flush_after = 0 max_worker_processes = 16 max_parallel_workers_per_gather = 8 max_parallel_maintenance_workers = 8 max_parallel_workers = 16 parallel_leader_participation = on enable_partitionwise_join = on enable_partitionwise_aggregate = on jit = on |
Database sizes used during the benchmark were as follows:
For each scale factor, the following benchmarks were measured (using default options):
Concurrency is a major factor if you want to benchmark in a professional environment. The following settings were used:
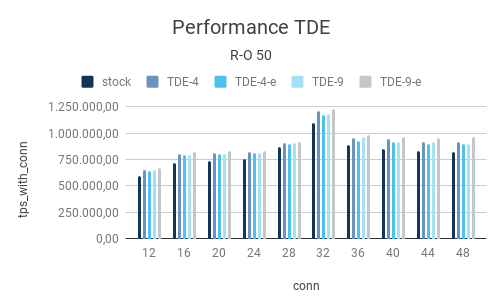
The following section contains the results of our investigation. Let’s start with a read-only benchmark and a scale factor of 50, which translates to 880 MB of data (small database):
| R-O | |||||
| 50 | |||||
| connections | stock | TDE-4 | TDE-4-e | TDE-9 | TDE-9-e |
| 12 | 598.004,94 | 652.870,65 | 640.867,94 | 651.161,67 | 668.317,19 |
| 16 | 717.080,83 | 806.152,21 | 795.300,37 | 794.494,71 | 821.915,21 |
| 20 | 735.584,04 | 813.589,44 | 801.139,14 | 807.197,44 | 829.891,65 |
| 24 | 757.834,24 | 818.350,37 | 809.893,87 | 817.332,59 | 832.810,15 |
| 28 | 865.626,22 | 911.020,73 | 896.977,27 | 909.858,10 | 916.804,18 |
| 32 | 1.095.158,47 | 1.212.918,76 | 1.175.538,12 | 1.182.331,49 | 1.233.930,94 |
| 36 | 885.519,57 | 958.732,55 | 931.091,56 | 967.514,37 | 986.631,16 |
| 40 | 847.388,93 | 943.701,45 | 915.369,45 | 919.076,23 | 964.899,29 |
| 44 | 830.018,15 | 914.696,79 | 901.860,60 | 913.789,27 | 954.813,04 |
| 48 | 818.142,23 | 916.199,48 | 894.018,17 | 901.936,11 | 964.656,08 |
Take a look at the first row (12 connections). Standard PostgreSQL will yield 598.000 read-only transactions per second which is a good number. In general, we have found that AMD CPUs are really efficient these days, and greatly outperform IBM POWER9 and many others. What we do notice is that the compiler makes a real difference. 651k TPS vs. 598k TPS is a whopping 9% improvement which basically comes for “free”. gcc 9 is doing really well here.
The following image shows the basic architecture of PostgreSQL TDE:
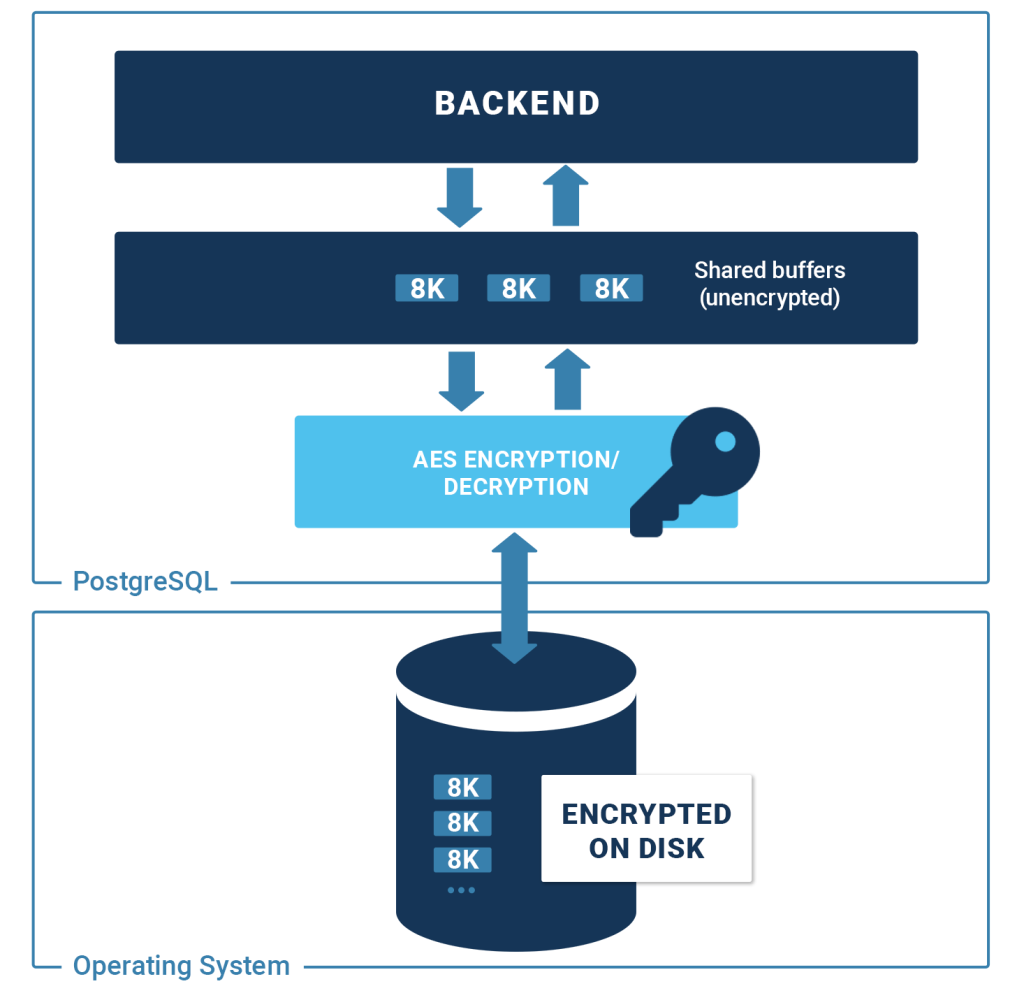
What is also important to see is that there is basically no difference between encrypted and non-encrypted runs. The reason for that is simple: PostgreSQL encrypts 8k blocks before sending them to disk and decrypts them when a block is fetched from the operating system. Therefore, there is no difference between the encrypted and unencrypted performance. What you see are, basically, fluctuations, which are totally expected.
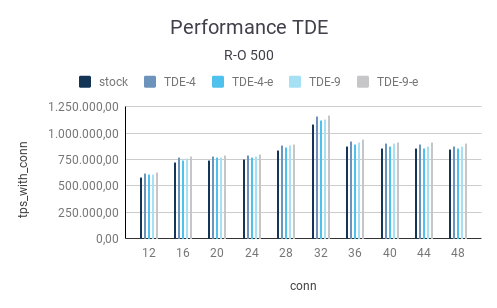
Let’s take a look at the same data. In this case, we are using a scale factor 500 which translates to 8 GB of data
| R-O | |||||
| 500 | |||||
| connections | stock | TDE-4 | TDE-4-e | TDE-9 | TDE-9-e |
| 12 | 583.003,70 | 623,487,99 | 611.303,93 | 615.277,51 | 628.507,18 |
| 16 | 723.460,41 | 772.852,04 | 750.083,11 | 761.129,07 | 782.628,12 |
| 20 | 750.054,44 | 782.333,97 | 770.649,65 | 778.393,73 | 795.200,14 |
| 24 | 755.796,29 | 792.365,30 | 773.744,79 | 787.903,80 | 802.164,80 |
| 28 | 842.270,11 | 890.584,06 | 872.163,41 | 886.265,42 | 895.721,71 |
| 32 | 1.087.753,87 | 1.166.292,93 | 1.124.810,04 | 1.133.026,80 | 1.170.395,10 |
| 36 | 881.376,33 | 926.521,14 | 901.508,03 | 914.466,29 | 948.293,12 |
| 40 | 860.762,15 | 911.308,67 | 875.478,96 | 911.961,05 | 912.369,46 |
| 44 | 857.354,28 | 895.126,03 | 863.349,07 | 878.027,97 | 916.855,40 |
| 48 | 853.062,65 | 881.192,84 | 858.566,69 | 882.463,09 | 910.616,50 |
The picture is pretty similar to what we observed with the small database. We are still 100% in RAM and therefore there is no real performance difference between PostgreSQL TDE with encryption on or encryption off. What you see are mostly fluctuations:
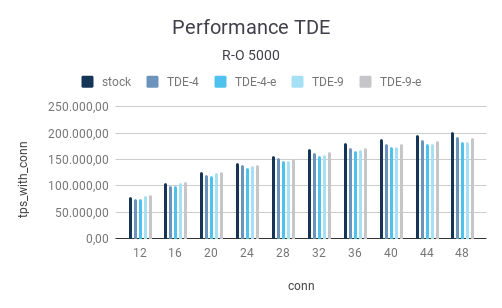
The final test was conducted with a scale factor of 5000. The important part is that the database has grown so large that there is no way to keep it in RAM anymore. Thus we can observe a major drop in performance:
| R-O | |||||
| 5000 | |||||
| connections | stock | TDE-4 | TDE-4-e | TDE-9 | TDE-9-e |
| 12 | 78.858,92 | 75.226,39 | 74.968,65 | 80.913,53 | 82.063,75 |
| 16 | 104.880,27 | 99.974,75 | 99.921,82 | 106.414,78 | 107.763,35 |
| 20 | 126.328,88 | 120.898,40 | 119.139,41 | 124.199,94 | 125.980,44 |
| 24 | 143.740,06 | 139.041,17 | 134.917,30 | 136.937,95 | 140.407,50 |
| 28 | 156.813,58 | 152.443,32 | 147.754,62 | 148.286,04 | 152.065,41 |
| 32 | 170.999,35 | 162.929,84 | 156.527,94 | 157.810,55 | 164.181,20 |
| 36 | 180.937,04 | 171.578,25 | 165.513,33 | 167.660,63 | 172.848,70 |
| 40 | 189.501,24 | 180.439,46 | 173.084,98 | 174.142,58 | 179.936,11 |
| 44 | 196.615,29 | 187.607,67 | 178.765,27 | 179.044,87 | 185.212,72 |
| 48 | 201.491,30 | 192.716,50 | 183.124,81 | 183.379,49 | 190.149,00 |
You have to keep in mind that going to disk is many many times more expensive than doing some pointer arithmetic in shared memory. A lot of latency is added to each individual query which leads to low TPS if there are not enough connections. On SSD’s this effect can be reduced a bit by adding a bit more concurrency. However, adding concurrency only works up to a certain point until the capacity of the disk is exceeded.
After this brief introduction to read-only benchmarks, we can focus our attention on read-write workloads. We use the standard mechanisms provided by pgbench here.
The first thing we notice is that performance is a lot lower. There are two reasons for that:
Let’s take a look at the data:
| TPC | |||||
| 50 | |||||
| connections | stock | TDE-4 | TDE-4-e | TDE-9 | TDE-9-e |
| 12 | 3.580,13 | 3.520,69 | 2.014,56 | 2.014,16 | 2.024,19 |
| 16 | 4.537,57 | 4.493,65 | 2.548,15 | 2.565,76 | 2.547,17 |
| 20 | 5.311,45 | 5.374,37 | 3.002,80 | 5.091,04 | 2.995,52 |
| 24 | 6.192,00 | 6.208,62 | 3.432,04 | 4.998,44 | 3.420,59 |
| 28 | 6.904,77 | 6.766,71 | 3.784,67 | 4.923,47 | 3.803,69 |
| 32 | 7.626,48 | 7.473,48 | 4.134,59 | 4.725,00 | 4.139,35 |
| 36 | 8.040,79 | 7.838,61 | 4.456,76 | 5.474,01 | 4.463,35 |
| 40 | 8.389,51 | 8.408,85 | 4.697,79 | 7.043,24 | 4.713,90 |
| 44 | 8.971,14 | 8.853,69 | 4.983,57 | 4.982,57 | 4.965,51 |
| 48 | 9.246,47 | 9.085,38 | 5.191,75 | 7.751,70 | 5.170,42 |
The price of encryption starts to tell. We see that the performance of the encrypted variants can be significantly lower than that of the non-encrypted setup.
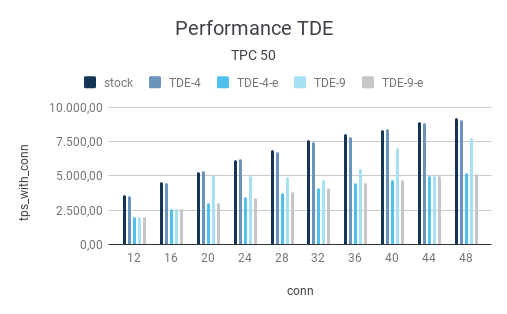
The picture is similar in case the amount of data is increased to a pgbench scale factor of 500:
| TPC | |||||
| 500 | |||||
| connections | stock | TDE-4 | TDE-4-e | TDE-9 | TDE-9-e |
| 12 | 4.088,59 | 4.098,60 | 2.201,37 | 3.106,54 | 3.080,33 |
| 16 | 5.417,76 | 5.372,61 | 2.818,17 | 3.400,99 | 3.278,76 |
| 20 | 6.716,89 | 6.688,04 | 3.437,78 | 3.712,33 | 3.672,65 |
| 24 | 7.792,77 | 7.903,35 | 4.021,37 | 4.484,28 | 4.576,07 |
| 28 | 9.061,49 | 7.850,11 | 4.631,35 | 4.926,10 | 5.150,77 |
| 32 | 10.399,70 | 10.428,75 | 5.235,09 | 5.515,01 | 5.818,24 |
| 36 | 11.631,82 | 11.737,26 | 5.811,99 | 6.056,26 | 6.381,50 |
| 40 | 12.998,91 | 12.986,14 | 6.349,06 | 6.911,43 | 6.526,33 |
| 44 | 14.201,98 | 14.301,64 | 6.913,72 | 7.360,12 | 7.472,31 |
| 48 | 14.908,41 | 15.259,67 | 7.489,46 | 8.097,42 | 7.650,18 |
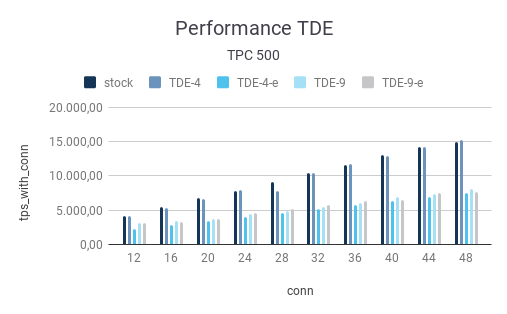
Now let’s inspect the test using a scale-factor of 5000. What we clearly see is that overall performance dramatically decreases. The reason is of course that a lot of the data has to come from the disk. We therefore see a fair amount of disk wait and latency:
| TPC | |||||
| 5000 | |||||
| connections | stock | TDE-4 | TDE-4-e | TDE-9 | TDE-9-e |
| 12 | 4.232,58 | 4.350,82 | 2.176,31 | 2.183,95 | 2.167,18 |
| 16 | 5.466,42 | 5.259,30 | 2.908,34 | 2.960,76 | 2.908,90 |
| 20 | 4.791,08 | 6.854,99 | 3.385,01 | 3.415,35 | 3.381,12 |
| 24 | 4.676,96 | 5.967,64 | 3.983,86 | 3.993,32 | 3.994,85 |
| 28 | 4.568,79 | 4.544,86 | 4.514,53 | 4.547,60 | 4.537,21 |
| 32 | 5.151,62 | 5.085,77 | 5.058,35 | 5.087,52 | 5.029,79 |
| 36 | 5.658,66 | 5.718,43 | 5.507,31 | 5.616,75 | 5.511,39 |
| 40 | 6.138,71 | 6.167,15 | 5.952,18 | 5.948,25 | 6.007,10 |
| 44 | 6.437,95 | 6.569,21 | 6.453,01 | 6.356,46 | 6.432,60 |
| 48 | 6.968,81 | 7.012,23 | 6.807,95 | 6.845,92 | 6.791,73 |
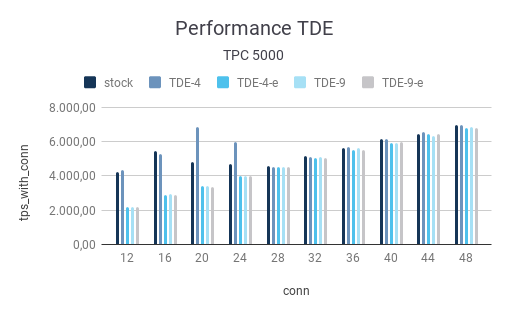
Note that all results have to be taken with a grain of salt. Run-times can always vary slightly. This is especially true if SSD’s are in use. We have seen that over and over again. The performance level we can expect will also highly depend on the PostgreSQL cache performance. Remember: every time a block is sent to disk or read into shared buffers, the encryption/decryption magic has to happen. Thus it can make a lot of sense to run PostgreSQL TDE with higher shared_buffers settings than you would normally do, in order to reduce the impact of security.
If you are aiming for better PostgreSQL database performance, we suggest checking out our consulting services. We can help you to speed up your database considerably. We offer timely delivery, professional handling, and over 20 years of PostgreSQL experience.