Concurrent counting in PostgreSQL: Recently we covered “count” quite extensively in this blog. We discussed optimizing count(*) and also talked about “max(id) - min(id)” which is of course a bad idea to count data in any relational database (not just in PostgreSQL). Today I want to focus your attention on a different kind of problem and its solution: Suppose you want to grant a user access to a certain piece of data only a limited number of times. How can you safely implement that?
Table of Contents
One might argue that this is easy. Here is some pseudo code:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BEGIN; SELECT count(*) FROM log WHERE customer_id = 10 AND tdate = '2020-04-09' if count >= limit ROLLBACK else INSERT INTO log “do some work” COMMIT; |
Looks easy, doesn't it? Well, not really.
What happens if two people run this concurrently. Both sessions will receive the same result for count(*) and therefore one session will come to the wrong conclusion. Both transactions will proceed and do the work even if only one is allowed to do it. That is clearly a problem.
To solve the problem one could do...
|
1 |
LOCK TABLE log IN ACCESS EXCLUSIVE MODE; |
... to eliminate concurrency all together. But, this is clearly a problem because it would block pg_dump or some analytics jobs or even VACUUM. Obviously not an attractive option. Alternatively we could try a SERIALIZABLE transaction but that might lead to many transactions failing due to concurrency issue.
One more problem is that count(*) might be really slow if there are already many entries. In short this approach has many problems:
But how can we do better?
To solve the problem we can introduce a “count table” but let us start right at the beginning. Let me create a table structure first:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE EXTENSION btree_gist; CREATE TABLE t_customer ( id serial PRIMARY KEY, customer_email text NOT NULL UNIQUE, login_whatever_else text ); CREATE TABLE t_customer_limit ( id serial PRIMARY KEY, customer_id int REFERENCES t_customer (id) ON UPDATE CASCADE ON DELETE SET NULL, clicks_per_day int CHECK (clicks_per_day > 0) NOT NULL, trange tstzrange, EXCLUDE USING gist (trange WITH &&, customer_id WITH =) ); CREATE INDEX idx_limit ON t_customer_limit(customer_id); |
First of all I have installed an extension which is needed for one of the tables (more on that later).The customer table contains an id, some login email address and some other fields for whatever purpose. Note that this is mostly a prototype implementation.
Then comes an important table: t_customer_limit. It tells us how many clicks per day which customer can have. PostgreSQL supports “range types”. A period can be stored in a single column. Using range types has a couple of advantages. PostgreSQL will automatically check if the period is valid (end > start and so on). In addition to that the database provides a couple of operators to make handling really easy.
In the next step I have created a table to track all requests thrown at us. Creating such a table has the advantage that you can do a lot of analytics later on:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE t_log ( id serial PRIMARY KEY, tstamp timestamptz DEFAULT now() NOT NULL, customer_id int NOT NULL, http_referrer inet, http_other_fields text NOT NULL, -- put in more fields request_infos jsonb -- what else we know from the request ); CREATE INDEX idx_log ON t_log (tstamp, customer_id); |
If you decide to store whatever there is in the HTTP header you might be able to identify spammers, access patterns and a lot more later on. This data can be really beneficial later on.
But due to the problems outlined before it is pretty tricky and inefficient to limit the number of entries per day for a single user. Therefore I have added a “count” table which has some interesting information:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE t_log_count ( customer_id int REFERENCES t_customer (id) ON UPDATE CASCADE ON DELETE SET NULL, tdate date NOT NULL, counter_limit int DEFAULT 0, counter_limit_real int DEFAULT 0, UNIQUE (customer_id, tdate) ) WITH (FILLFACTOR=60); CREATE INDEX idx_log_count ON t_log_count (tdate, customer_id); |
For each day we store the counter_limit which is the number of hits served to the client on a given day. This number will never go higher than the limit of the user for the day. Then we got the counter_limit_real which contains the number of requests the user has really sent. If counter_limit_real is higher than counter_limit we know that we had to reject requests due to high consumption. It is also trivial to figure out how many requests we already had to reject on a given day for a user.
Let us add some sample data:
|
1 2 3 4 5 |
-- sample data INSERT INTO t_customer (customer_email) VALUES ('hans company'); INSERT INTO t_customer_limit (customer_id, clicks_per_day, trange) VALUES (1, 4, '['2020-01-01', '2020-06-30']'); |
'hans_company' is allowed to make 4 requests per day for the period I have specified.
Now that the data structure is in place I have created a simple SQL function which contains the entire magic we need to make this work efficiently:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE FUNCTION register_call(int) RETURNS t_log_count AS $ WITH x AS (SELECT * FROM t_customer_limit WHERE now() <@ trange AND customer_id = $1), y AS (INSERT INTO t_log (customer_id, http_other_fields) VALUES ($1, 'whatever info') ) INSERT INTO t_log_count (customer_id, tdate, counter_limit, counter_limit_real) VALUES ($1, now()::date, 1, 1) ON CONFLICT (customer_id, tdate) DO UPDATE SET counter_limit_real = t_log_count.counter_limit_real + 1, counter_limit = CASE WHEN t_log_count.counter_limit < (SELECT clicks_per_day FROM x) THEN t_log_count.counter_limit + 1 ELSE t_log_count.counter_limit END WHERE EXCLUDED.customer_id = $1 AND EXCLUDED.tdate = now()::date RETURNING *; $ LANGUAGE 'sql'; |
This might look a bit nasty at first glance but let us dissect the query bit by bit. The first CTE (x) tells today's limits for a specific user. We will need this information later on. “x” is not needed explicitly because we can also use a simple subselect. But if you want to sophisticate my prototype it might come in handy if “x” can be reused in the query multiple times.
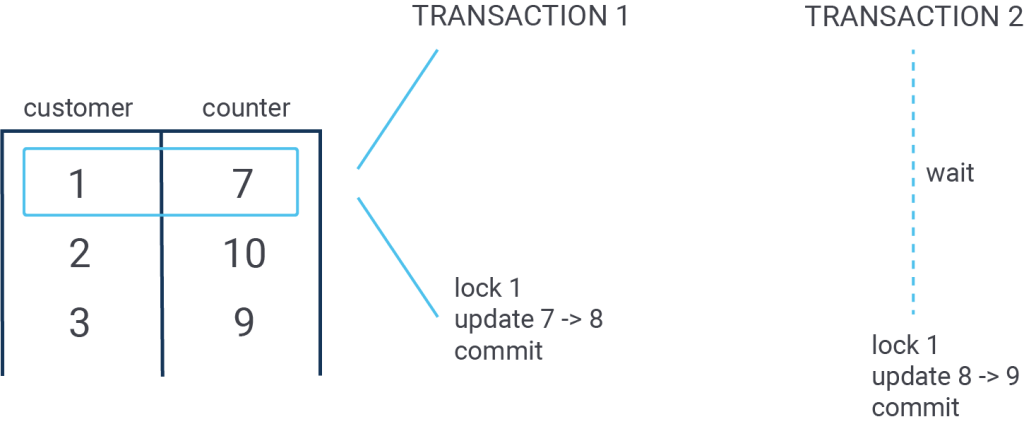
Then the query inserts a row into t_log. This should be a pretty straight forward operation. Then we attempt to insert into t_log_count. If there is no entry for the customer for the day yet the insert will go through. The important part is that if two INSERT statements happen at the same time PostgreSQL will report a key violation and we cannot end up with a duplicate entry under and circumstances.
But what happens if the key is violated? In this case the ON CONFLICT clause we show its worth: If the INSERT goes wrong we want to perform an UPDATE. If we have reached the limit we only increment counter_limit_real - otherwise we increment both values. Then the updated row is returned. If counter_limit_real and counter_limit are identical we can allow the request - otherwise the user has to be rejected.
The count table has some nice attributes: When it is updated only ONE row will be locked at a time. That means that no operations on t_log will be blocked for reporting, VACUUM and so on. The row lock on the second table will perfectly synchronize things and there is no chance of serving requests which are not allowed. Minimal locking, maximum performance while maintaining flexibility.
Of course this is only a prototype which leaves some room for improvements (such as partitioning). From a locking and efficiency point of view this is promising.
A simple test on my (relatively old) iMac has shown that I can run around 20.000 requests in around 10 seconds (single connection). This is more than enough for most applications assuming that there will be many clients and a lot of parallelism.
What you have to keep in mind is bloat. Keep an eye on the updated table at all time and make sure that it does not grow out of proportion.
Avoiding bloat is important. Check out our post about VACUUM and PostgreSQL database bloat here. You will learn all you need to know to ensure your database is small and efficient.
Also: If you happen to be interested in stored procedures we recommend to check out our latest blog dealing with stored procedures in PostgreSQL.
how is the performance, when i just add a FOR UPDATE?
select * from t_log_count where customer_id = 10 and tdate = '2020-04-09' FOR UPDATE;.normally i just check the return-value of my update (0 or 1 rows):
update t_log_count set counter_limit_real = counter_limit_real 1 where customer_id = 1 and tdate = current_date and counter_limit_real < counter_limit;