Recently, I was asked whether Postgres was “covered” in the area of common reporting needs? By reporting I mean ad hoc or predefined chart generation, mostly drag-and-drop style software, used most commonly by Business Intelligence people. The answer is “yes” - you can do reporting on PostgreSQL as easily as with other popular databases.
But what options are out there more specifically? So here’s a small list on some popular options I’m aware of. As a disclaimer, I have to say that I don't have to deal with reporting too often so it’s not a definitive list in any way, there are dozens and dozens of options out there, and I haven’t used all the listed ones but just seen them used or being talked about.
* Tableau
Tableu is definitely one of the most popular and feature rich options. Besides the basics, it provides all kinds of fancy visualizations (geomapping, treemaps, Gantt charts) and supports both ad-hoc queries and loading data to their server for even more options. Commercial product.
* Microstrategy
Microstrategy provides charting but is more of an enterprise analytics suite with a huge feature-set covering all analytics needs - visualizations, predictive analytics, alerts. Commercial product.
* JasperReports
JasperReports is the most popular Open Source reporting software with all the modern features (visual designers, mobile apps) in the Open Source version and even more advanced stuff (ETL, Hadoop integration etc) available in the paid commercial edition.
* QlikView
One of the veterans of business intelligence & visualization software. Quite user friendly but one needs to load data to QlikView first. Commercial product.
NB! For successful ad hoc reporting you should normally make sure your data more or less fits into RAM or you should at least have very fast disks (SSDs).
When your requirements are not so “enterprisy” (you’re ready to set up some software and write some SQL-s) and you’re OK with just the most common graph types, then you also have some options.
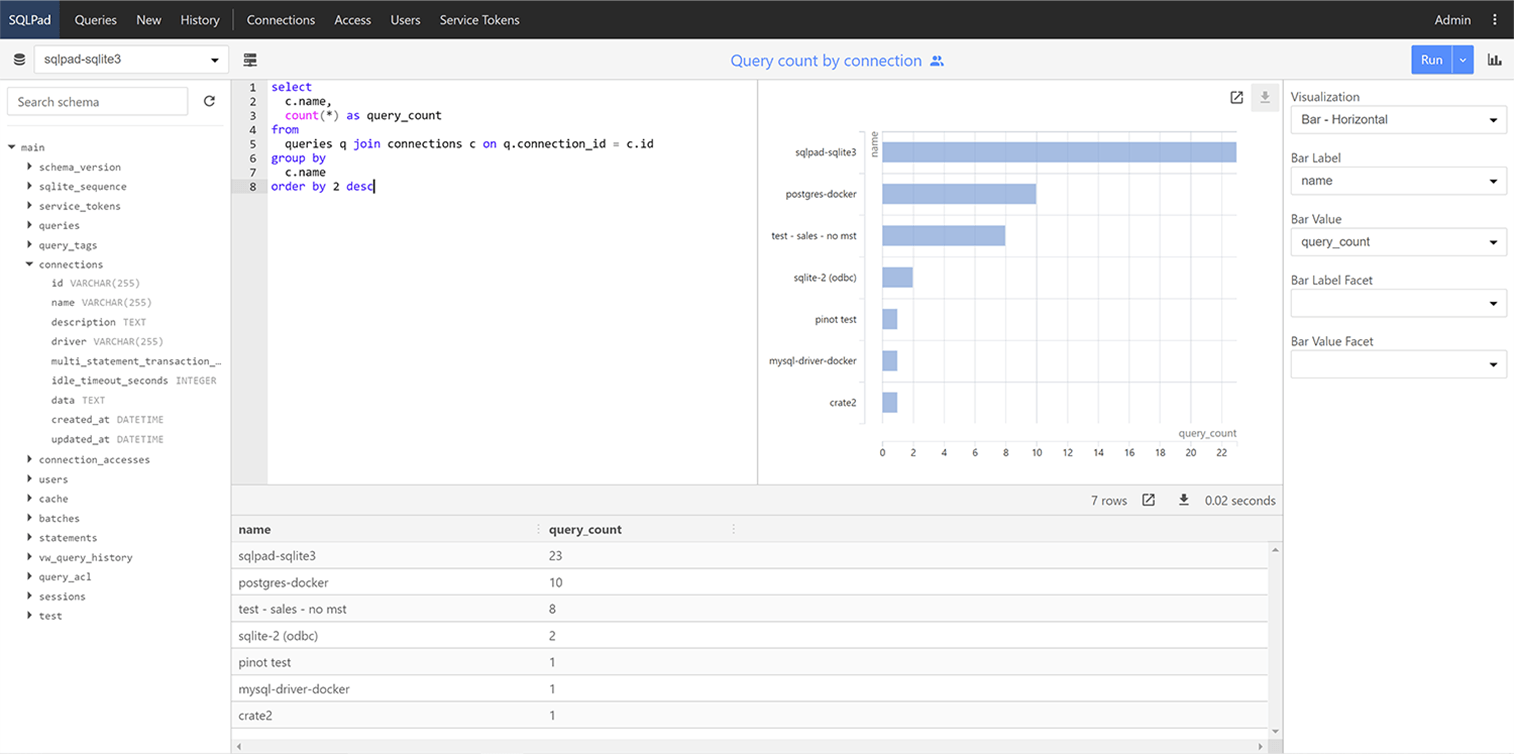
* SqlPad
Currently for my own needs this very active Open Source project would be my first pick. It has all the basic chart types, plus a way to share charts among users. See the SqlPad project Website for more. It looks something like that:
* pgcharts
Simplistic charting for Postgres. Project doesn’t seem to be too active nowadays though. See the GitHub project here.
* Pull the data to you spreadsheet program for DIY charting
Maybe not exactly the most convenient method, but you can still quite easily fetch data from your Postgres database to Libre(Open)Office or MS Excel and do your charting there. How to do it for LibreOffice Calc, for example, can be seen from this YouTube video here and in the end it would look something like my screenshot below. Note that you need also LibreOffice Base and libreoffice-sdbc-postgresql driver (sudo apt install libreoffice-sdbc-postgresql libreoffice-base on Ubuntu).

Please write a comment if there are some other good options out there!

A lot has been said and written about scaling PostgreSQL to many cores and subsequently to many machines. Running PostgreSQL in a server farm is something, which has not been possible for many years. However, this has definitely changed. A lot of development has gone into scaling PostgreSQL and to running a single query on many CPUs. PostgreSQL 9.6 was the first release, which allowed to run a query on many nodes. Development has moved on and things are constantly improving to make PostgreSQL even better.
Currently we have some projects going on here at Cybertec, which require PostgreSQL to scale well beyond a single server. The idea to scale PostgreSQL infinitely is of course not new but it is still exciting to push the limits of our beloved Open Source database further and further every day.
Traditionally PostgreSQL used a single CPU core for a query. Of course this used to be a severe limitation, which has fortunately been removed. Many things inside PostgreSQL can already be done in parallel. As the project moves on, more and more parallelism will be available, and many more queries can benefit from multicore systems.
To show how a simple query can benefit from parallelism, we have compiled a simple data structure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
node=# d t_demo Table 'public.t_demo' Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+------------------------------------ id | integer | | not null | nextval('t_demo_id_seq'::regclass) grp | integer | | | data | real | | | Indexes: 'idx_id' btree (id) |
The query used for this test is pretty: It simply counts the number of rows for each group:
|
1 2 3 4 5 |
SELECT grp, count(data) FROM t_demo GROUP BY 1; |
When running in parallel mode, the best plan produced by the optimizer possible with our version is the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
node=# EXPLAIN SELECT grp, partial.count(data) FROM public.t_demo GROUP BY grp; QUERY PLAN -------------------------------------------------------------------------------------------------- Finalize GroupAggregate (cost=635312.96..635314.26 rows=10 width=12) Group Key: grp -> Sort (cost=635312.96..635313.36 rows=160 width=12) Sort Key: grp -> Gather (cost=635291.01..635307.10 rows=160 width=12) Workers Planned: 16 -> Partial HashAggregate (cost=634291.01..634291.10 rows=10 width=12) Group Key: grp -> Parallel Seq Scan on t_demo (cost=0.00..603041.01 rows=6250000 width=8) |
PostgreSQL will process the large table using 16 worker processes. In case your system contains at least 16 CPU cores, performance will basically increase in a linear way as worker processes are added. Each worker will aggregate data and the partial aggregates are then added up. This linear trend is very important because it is a necessary precondition to use hundreds or thousands of CPUs at the same time.
If you have a normal application it is usually sufficient to have a single box because you can aggregate millions of rows in very little time on a single database node. However, if data grows even further, scaling to many nodes might be necessary.
Assuming that our data node contains 16 CPU cores (Google cloud box) and 100 million rows, performance will improve depending on the number of processes used:
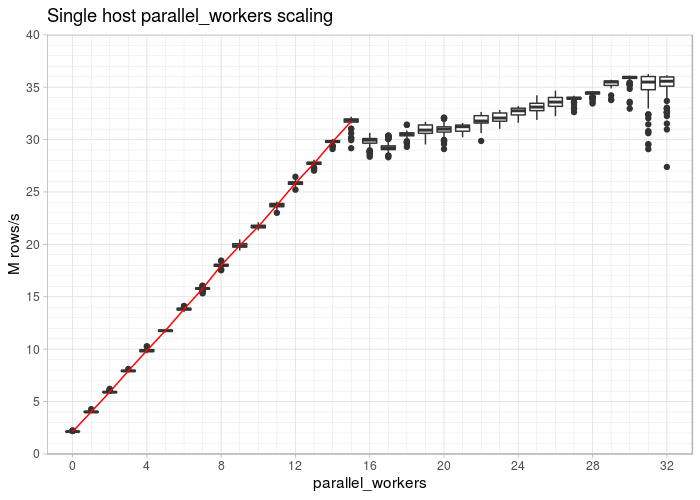
The first important observation is that the line goes straight up to 16 cores. It is also interesting to see that you can still gain a little bit of speed if you are using more than 16 processes to do the job. The benefit you can see here is related to Intel Hyperthreading - you can expect a boost of around 15% given this type of query. On a single database node (VM) you can reach around 40 million rows per second for a simple aggregation.
However, the goal was to reach more than 1 billion rows / second. The way to get there is to add servers.
To reach our goal the following architecture will be used:
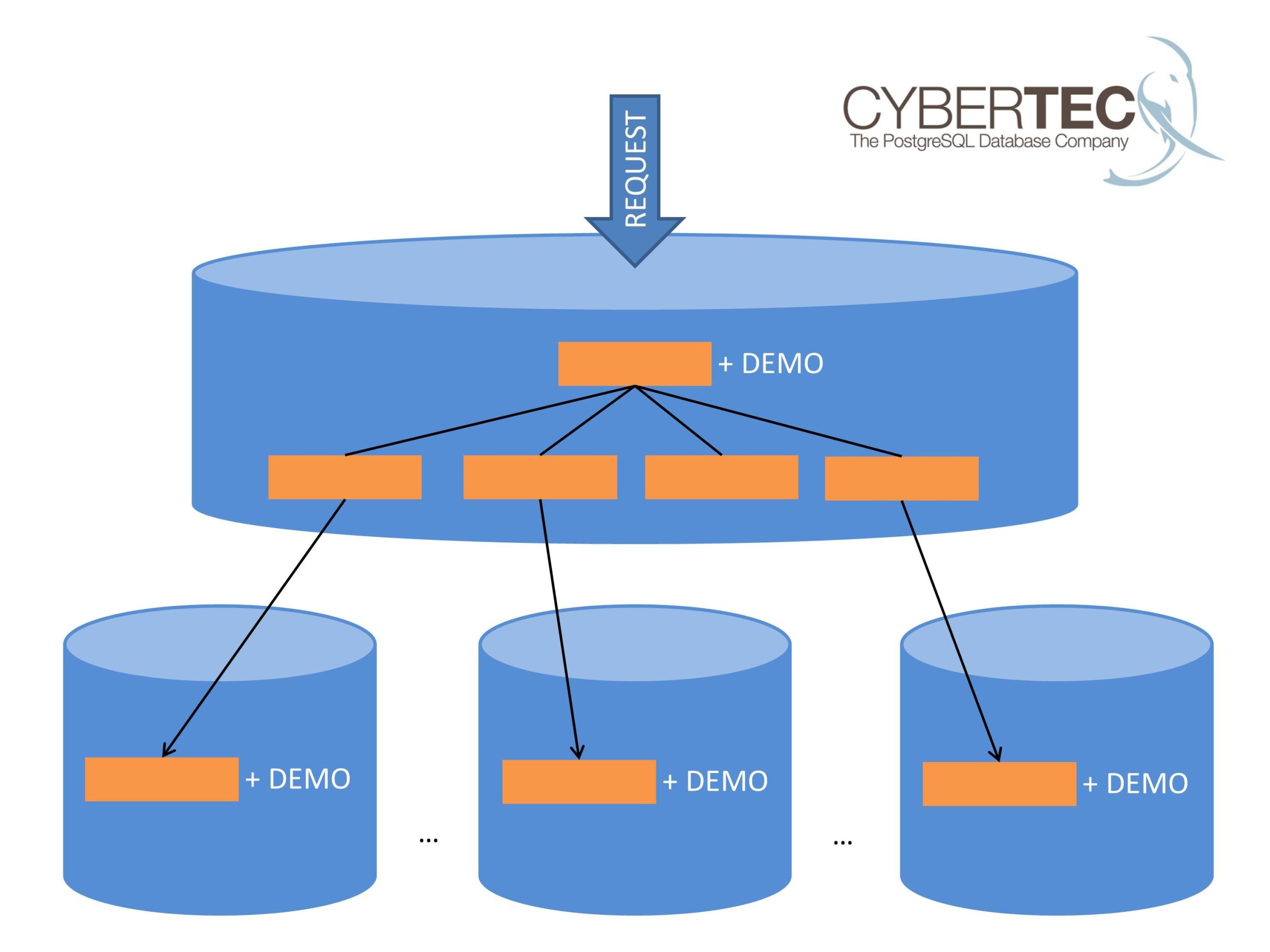
The idea is to have a partitioned table, which is distributed. The data will reside on the actual nodes.
In a first step a second server is added so that we can see that we indeed process twice the amount of data within the same timeframe.
Here is the execution plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
EXPLAIN ANALYZE SELECT grp, COUNT(data) FROM t_demo GROUP BY 1; QUERY PLAN ------------------------------------------------------------------------------------------------------------ Finalize HashAggregate (cost=0.02..0.03 rows=1 width=12) (actual time=2706.764..2706.768 rows=10 loops=1) Group Key: t_demo.grp -> Append (cost=0.01..0.01 rows=1 width=0) (actual time=2486.349..2706.735 rows=20 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.818..0.822 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.755..0.758 rows=10 loops=1) -> Partial HashAggregate (cost=0.01..0.01 rows=1 width=0) (never executed) Group Key: t_demo.grp -> Seq Scan on t_demo (cost=0.00..0.00 rows=1 width=8) (never executed) Planning time: 0.200 ms Execution time: 2710.888 ms |
In this example 100 million rows have been deployed on each database server. The beauty is that the execution time stays the same.
Let us try the same query with 32 x 100 million rows now:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
node=# EXPLAIN ANALYZE SELECT grp, count(data) FROM t_demo GROUP BY 1; QUERY PLAN ------------------------------------------------------------------------------------------------------------ Finalize HashAggregate (cost=0.02..0.03 rows=1 width=12) (actual time=2840.335..2840.340 rows=10 loops=1) Group Key: t_demo.grp -> Append (cost=0.01..0.01 rows=1 width=0) (actual time=2047.930..2840.015 rows=320 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.050..1.052 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.000..1.002 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.793..0.796 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.776..0.779 rows=10 loops=1) ... -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.112..1.116 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.537..1.541 rows=10 loops=1) -> Partial HashAggregate (cost=0.01..0.01 rows=1 width=0) (never executed) Group Key: t_demo.grp -> Seq Scan on t_demo (cost=0.00..0.00 rows=1 width=8) (never executed) Planning time: 0.955 ms Execution time: 2910.367 ms |
Wow, we need less than 3 seconds for 3.2 billion rows!
The result looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
node=# SELECT grp, count(data) FROM t_demo GROUP BY 1; grp | count -----+----------- 6 | 320000000 7 | 320000000 0 | 320000000 9 | 320000000 5 | 320000000 4 | 320000000 3 | 320000000 2 | 320000000 1 | 320000000 8 | 320000000 (10 rows) |
All together there are 3.2 billion rows on those shards.
The most important observation here is that for this kind of query shards can be added on demand as more performance is needed or as the amount of data just grows. PostgreSQL will scale up nicely with every node people add.
So what is actually needed to achieve those results? First of all it does not work with vanilla PostgreSQL 9.6. The first thing we needed was some functionality, which will be in PostgreSQL 10.0: postgres_fdw needs the ability to push down aggregates to a remote host. That is the easy part. The trickier part is to teach PostgreSQL that all shards have to work in parallel. Fortunately there has been a patch out there, which allowed for making “Append” nodes fetch data concurrently. Parallel Append is an important precondition for our code to work.
However, there is more: For many years PostgreSQL could only aggregate data AFTER it has been joined. Basically this restriction has stopped many performance optimizations. Thanks to incredible work done by Kyotaro Horiguchi, who has done a wonderful job removing this restriction, it was possible for us to build on top to aggregate so much data and to actually reach 1 billion rows per second. Given the complexity of the task it is more than necessary to explicitly list Kyotaro's work because without him our achievement would have been close to impossible.
But there is more to making this work: Our solution is heavily based on postgres_fdw. To be able to fetch large amounts of data, postgres_fdw uses a cursor on the remote side. At this point PostgreSQL 9.6 and PostgreSQL 10.0 cannot do cursors fully parallel yet. Therefore we had to lift this restriction to ensure that all CPU cores on the remote hosts can be used at the same time.
Finally it needs a couple of (at this point) handwritten aggregates to do the map-reduce style aggregation here. Achieving that is simple as it can easily be done with a simple extension.
While 1 billion rows per second is certainly a nice achievement, there will be more cool stuff in PostgreSQL in the future. As JIT compilation and various other optimizations start to make their way into PostgreSQL (tuple deforming, column store, etc.), we will see similar results using fewer and fewer CPUs. You will be able to use fewer and smaller servers to achieve similar performance.
Our test has been done without all those optimizations and we know that there is definitely a lot more room for improvements. The important thing here is that we managed to show that PostgreSQL can be made to scale to hundreds or maybe thousands of CPUs, which can cooperate in a cluster to work on the very same query.
At this point a single “master” server and a couple of shards have been used. For most cases this architecture will be sufficient. However, keep in mind that it is also possible to organize servers in a tree, which can make sense for some even more complex calculation.
Also keep in mind that PostgreSQL supports custom aggregates. The idea is that you can create your own aggregation function to do even more complex stuff in PostgreSQL.
Contact: Follow us on Twitter (@PostgresSupport) so that you can stay up to date. More cool stuff is on the way.
To follow up on the previous introductory post here on the new pgwatch2 monitoring tool (Open Source project, GitHub link here), we’ll now look a bit deeper under the hood and provide some more info on customization options. Here we still assume the default Docker installation and I’ll first start by listing and describing all the components inside the Docker image and follow with some advanced topics.
This is a standard (apt-get install postgresql) PostgreSQL database running inside Docker and its purpose is to store the information about which databases are to be monitored and in which configuration. Configurations more specifically are composed of:
Metric definitions – metrics are named SQL queries that can return pretty much everything you find useful and which can have different query text versions for different target PostgreSQL versions. Correct version of the metric definition will be chosen automatically by regularly connecting to the target database and checking the version. For defining metrics definitions you should adhere to a couple of basic concepts though:
Preset configurations - these are named pairs of metrics and their intervals, that can be applied to the databases under monitoring, enabling re-using of configs when you have a group of databases with similar monitoring requirements. Configs are stored as JSON and look like that - {“metricX”: “gathering_intervalX”, “metricY”: “gathering_intervalY”, …}.
Custom configurations – one can define metric-interval pairs also freely for every database.
Exposed port – 5342.
For easy configuration changes (adding databases to monitoring, adding metrics) there is a small Python Web application bundled, making use of the CherryPy Web-framework. For mass changes one could technically also log into the configuration database and change the tables in the “pgwatch2” schema directly. Besides the configuration options the two other useful features would be the possibility to look at the logs of the single components and at the “Stat Statements Overview” page, which will e.g. enable finding out the query with the slowest average runtime for a time period.
Exposed ports - 8080
This component is a daemon written in Go (doesn’t expose any ports) that does the heavy-lifting so to say. After setting up some variables and data exchange processes it actually implements a simple state machine which basically does the following – 1) check the configuration DB for a list of databases that should be monitored. 2) for all the found DB-s make sure they have worker processes (goroutines) for all the metrics, that execute the metric definitions after the interval passes and then sleep for duration of the interval. 3) if some DB was removed from the configuration, remove the workers.
The gatherer also has some fault tolerance built in. When the configuration DB “goes away” nothing happens – last known config will be used. When the storage backend (InfluxDB) goes away, the gathered metric values will be kept in memory and storing is re-tried periodically. At some point though the application will run out of memory and all non-persisted metrics data will be lost. Thus for more critical applications it’s still recommended to set up some kind of external monitoring for the InfluxDB (exposing port 8086).
Error log for the gatherer can be viewed via the Web UI on /logs/pgwatch2. The most common problems I can imagine being connection fails due to pg_hba.conf rules, mistypins of host address, users/passwords.
InfluxDB is a very popular Time Series Database choice (offered in two flavors – community and enterprise) and offers excellent performance and very good data compression making it a perfect fit for bundling it into Docker. Being a NoSQL database, it has though the downside of not supporting SQL but providing an own lighter query language called InfluxQL. It can master a lot things comparable to PostgreSQL, but some more complex analytics (e.g. give me top 10 slowest queries) are not really possible, so there one must fall back to visual problem detection from graphs. In the most recent version of 1.2 it has luckily though introduced support for basic subqueries, signalling that they’re aware of the problem.
InfluxDB also comes with an optional “Admin interface” for ad hoc queries, so we also enable this by default, but this UI might disappear in the future. One can expose it on port 8083 and it’s mostly useful for debugging and looking at metrics data directly in tabular format. But as said, it’s not really needed as most users should be covered by functionality provided by Grafana.
Exposed ports – 8083, 8086, 8088.
Grafana is currently the hottest dashboarding software and provides easy integration to many Time Series Databases, including InfluxDB. And putting together your own custom dashboards is indeed very easy, so please take a look at the excellent documentation and I won’t stop here for longer.
Exposed port - 3000.
By default the main user interface (Grafana) and the management UI have no authentication. To make changes to Grafana dashboards one needs to log in though. To add authentication to the Web UI launch the Docker image with the following environment parameters set:
|
1 |
docker run -d -p 3000:3000 -p 8080:8080 --name pw2 -e PW2_WEBNOANONYMOUS=1 PW2_WEBUSER=admin PW2_WEBPASSWORD=secret cybertec/pgwatch2 |
There are also some other parameters available for launching the Web UI here and from practical perspective to retrospectively change them it might be the easiest to go into the container and relaunch the app.
NB! Currently there’s no built in HTTPS support so one should use some load balancer technique to safely expose the UI over the Internet. We’ll though plan built-in support also for the next bigger version update.
By default pgwatch2 is designed to only monitor metrics that are available in a standard PostgreSQL database (meaning pg_stat_* views), without requiring any Superuser rights. This is perfect for example for developers as it enables already quite good ad hoc monitoring of live databases. But mostly you will still want more – system information like CPU or memory state for example. For such cases the workaround to “break out” from Postgres and to access system information is usually to use an “unsafe” PL-language and write a small wrapper function that returns the needed information as normal SQL results.
Shipped are currently two such “helpers” provided – a PL/Python sproc reading the CPU load and a “security definer” wrapper for pg_stat_statement information, to enable monitoring of all user queries (by default non-superusers will only see their own queries statistics), but you can easily create your own (free memory, disk space,…) and maybe we’ll add some also.
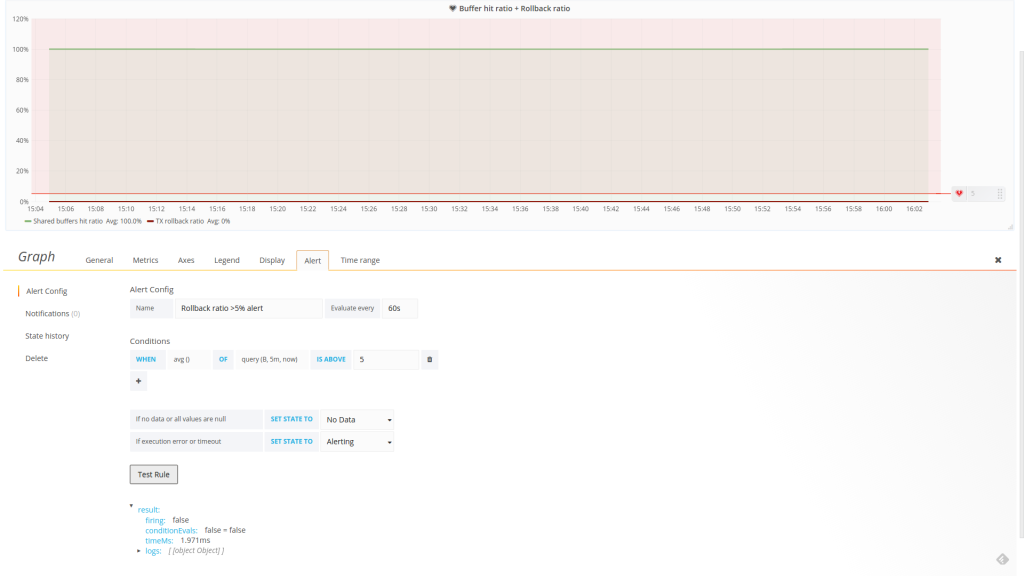
Just on time for our release, the latest major Grafana version added support for basic alerting – see here for documentation. Only graphs are currently supported though and how it works is that you can set a hard limit (constant number) on some value that you’re graphing on – stating e.g. if “DB size growth for 1h” is bigger than 1GB send me message on Slack together with an image of the graph. Other notification options provided are: email, webhook, pagerduty, victorops, opsgenie. For API based services it’s fairly easy to set up via the UI, only for email you need to go into the Grafana config file.
Another option for more advanced alerting needs would be to integrate with Kapacitor, that integrates seamlessly with InfluxDB and enables for example more intelligent detection of anomalies.
If not using a custom setup where you can switch out single components easily, migrating to a new version of Docker image (for example to enjoy benefits of a new Grafana version) needs quite some steps currently. See the take_backup.sh script here for more details.
Basically there are two options – first, go into docker and just update the component yourself – i.e. download the latest Grafana .deb package and install it with “dpkg -i ...”. This is actually the simplest way. The other way would be to fetch the latest pgwatch2 image, which already has the latest version of components, using “docker pull” and then restore the data from a backup of old setup. For restoring one needs to go into Docker again and stop InfluxDB, but that's no rocket science.
And to make the restore process easier it would make already sense to mount the host folder with the backup on the new container with “-v ~/pgwatch2_backups:/pgwatch2_backups” when starting the Docker image. Otherwise one needs to set up SSH or use something like S3 for example.
Ports 5432 and 8088 need to be exposed to take backups outside of Docker.
I’ve got quite some improvement ideas already, just take a look at the GitHub to-do-list here, but please leave a comment or open a feature request issue on GitHub if you’re still missing something that makes pgwatch2 not an option for you or your organization. Thanks!
pgwatch2 is constantly being improved and new features are added.
+43 (0) 2622 93022-0
office@cybertec.at