Many people have have been asking for this feature for years and PostgreSQL 11 will finally have it: I am of course talking about CREATE PROCEDURE. Traditionally PostgreSQL has provided all the means to write functions (which were often simply called “stored procedures”). However, in a function you cannot really run transactions - all you can do is to use exceptions, which are basically savepoints. Inside a function, you cannot just commit a transaction or open a new one. CREATE PROCEDURE will change all that and provide you with the means to run transactions in procedural code.
CREATE PROCEDURE will allow you to write procedures just like in most other modern databases. The syntax is quite simple and definitely not hard to use:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
db11=# \h CREATE PROCEDURE Command: CREATE PROCEDURE Description: define a new procedure Syntax: CREATE [ OR REPLACE ] PROCEDURE name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] ) { LANGUAGE lang_name | TRANSFORM { FOR TYPE type_name } [, ... ] | [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER | SET configuration_parameter { TO value | = value | FROM CURRENT } | AS 'definition' | AS 'obj_file', 'link_symbol' } … |
As you can see there are a couple of similarities to CREATE FUNCTION so things should be really easy for most end users.
The next example shows a simple procedure:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
db11=# CREATE PROCEDURE test_proc() LANGUAGE plpgsql AS $$ BEGIN CREATE TABLE a (aid int); CREATE TABLE b (bid int); COMMIT; CREATE TABLE c (cid int); ROLLBACK; END; $$; CREATE PROCEDURE |
The first thing to notice here is that there is a COMMIT inside the procedure. In classical PostgreSQL functions this is not possible for a simple reason. Consider the following code:
|
1 |
SELECT func(id) FROM large_table; |
What would happen if some function call simply commits? Total chaos would be the consequence. Therefore, real transactions are only possible inside a “procedure”, which is never called the way a function is executed. Also: Note that there is more than just one transaction going on inside our procedure. Because of this, a procedure is more of a “batch job”.
The following example shows, how to call the procedure I have just implemented:
|
1 2 |
db11=# CALL test_proc(); CALL |
The first two tables where committed - the third table has not been created because of the rollback inside the procedure.
|
1 2 3 4 5 6 7 8 |
db11=# \d List of relations Schema | Name | Type | Owner --------+------+-------+------- public | a | table | hs public | b | table | hs (2 rows) |
To me CREATE PROCEDURE is definitely one of the most desirable features of PostgreSQL 11.0. The upcoming release will be great and many people will surely welcome CREATE PROCEDURE the way I do.
As some of you might know, CYBERTEC has been helping customers with PostgreSQL consulting, tuning and 24x7 support for many years now. However, one should not only see what is going on in the PostgreSQL market. It also makes sense to look left and right to figure out what the rest of the world is up to these days. I tend to read a lot about Oracle, the cloud, their new strategy and all that on the Internet at the moment.
What I found in an Oracle blog post seems to sum up what is going on: “This is a huge change in Oracle's business model, and the company is taking the transformation very seriously”. The trouble is: Oracle's business model might change a lot more than they think because at this time more and more people are actually moving to PostgreSQL. So yes, the quote is correct - this is a “huge change” in their business model, but maybe not what the way they intended it to be.
As license fees and support costs seem to be ever increasing for Oracle customers, more and more people step back and reflect. The logical consequence is: People are moving to PostgreSQL in ever greater numbers. So why not give people a tool to move to PostgreSQL as fast as possible? In many cases an Oracle database is only used as a simple data store. The majority of systems only contains tables, constraints, indexes, foreign keys and so on. Sure, many databases will also contain procedures and more sophisticated stuff. However, I have seen countless systems, which are simply trivial.
While there are tools such as ora2pg out there, which help people to move from Oracle to PostgreSQL, I found them in general a bit cumbersome and not as efficient as they could be.
So why not build a migration tool, which makes migration as simple as possible? Why not migrate simple database with a single SQL statement?
ora_migrator does exactly that:
|
1 2 |
CREATE EXTENSION ora_migrator; SELECT oracle_migrate(server => 'oracle', only_schemas => '{HANS,PAUL}'); |
Unless you have stored procedures in PL/pgSQL or some other hyper fancy stuff, this is already it. The entire migration will be done in a SINGLE transaction.
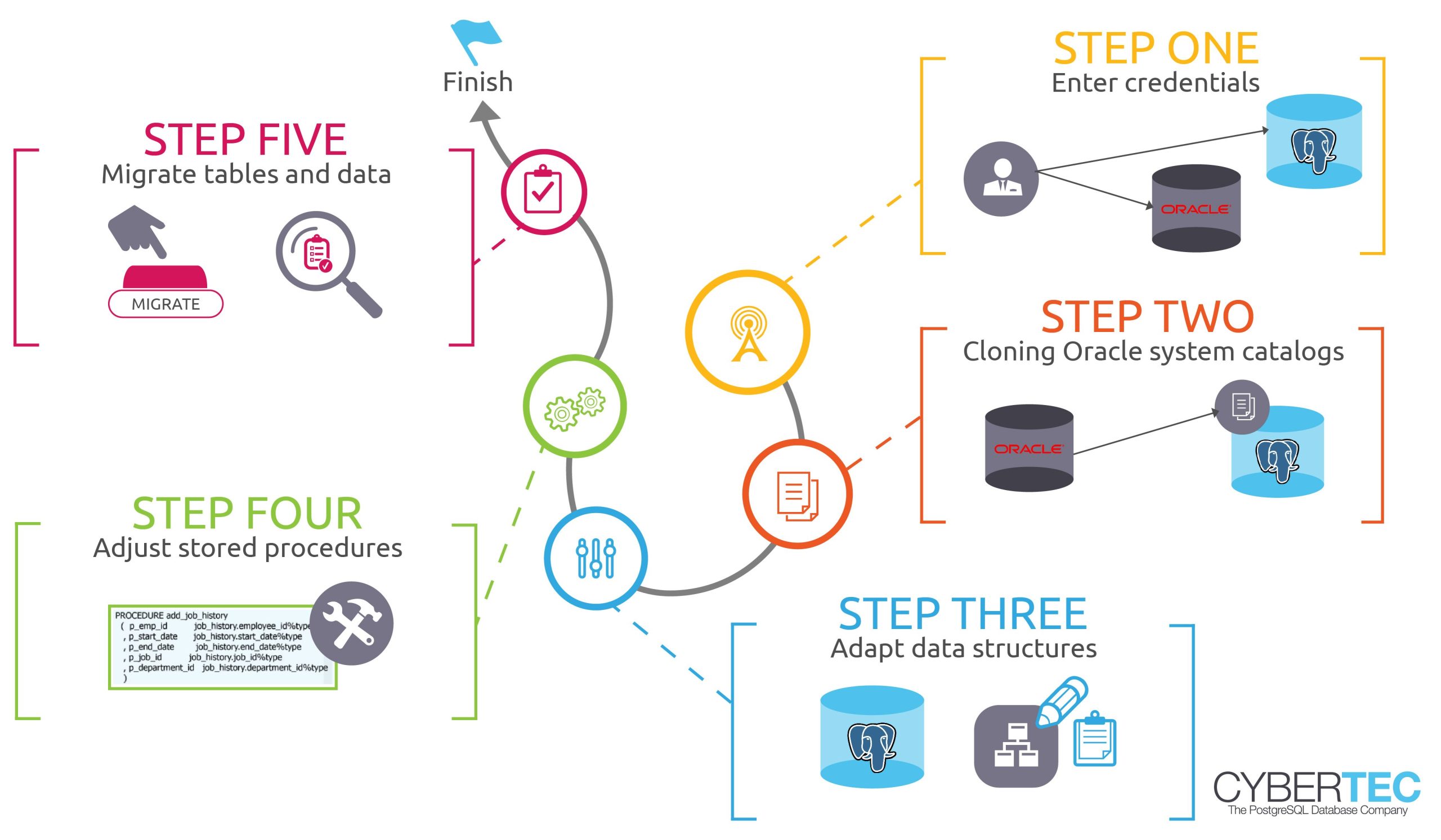
First of all the ora_migrator will connect to Oracle using the oracle_fdw, which is the real foundation of the software. Then we will read the Oracle system catalog and store of a copy of the table definitions, index definitions and all that in PostgreSQL. oracle_fdw will do all the data type mapping and so on for us. Why do we copy the Oracle system catalog to a local table and not just use it directly? During the migration process you might want to make changes to the underlying data structure and so on (a commercial GUI to do that is available). You might not want to copy table definitions and so on blindly.
Once the definitions are duplicated and once you have made your modifications (which might not be the case too often - most people prefer a 1:1 copy), the ora_migrator will create the desired tables in PostgreSQL, load the data from Oracle, create indexes and add constraints. Your transaction will commit and, voila, your migration is done.
Experience has shown that a fully automated migrated process for stored procedures usually fails. We have used ora2pg for a long time and procedure conversion has always been a pain when attempted automatically. Therefore, we decided to skip this point entirely. To avoid nasty bugs, bad performance, or simply mistakes we think that it makes more sense to port stored procedures manually. In the past, automatic conversion has led to a couple of subtle bugs (mostly NULL handling issues) and as a consquence we do not attempt things in the first place. In real life this is not an issue and it does not add too much additional work to the migration process - the minimum amount of additional time is worth spending on quality in my judgement.
If you want to move from Oracle to PostgreSQL, you can download ora_migrator for free from our GitHub page. We also have created a GUI for the ora_migrator, which will be available along with our support and consulting services.
For the easiest way to migrate from Oracle to PostgreSQL, check out the CYBERTEC Migrator – get all information and the free standard edition here:

In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
xmax is a PostgreSQL system column that is used to implement Multiversion Concurrency Control (MVCC). The documentation is somewhat terse:
The identity (transaction ID) of the deleting transaction, or zero for an undeleted row version. It is possible for this column to be nonzero in a visible row version. That usually indicates that the deleting transaction hasn't committed yet, or that an attempted deletion was rolled back.
While this is true, the presence of “weasel words” like “usually” indicates that there is more to the picture. This is what I want to explore in this article.
xmaxI'll follow the PostgreSQL convention to use the word “tuple” for “row version” (remember that PostgreSQL implements MVCC by holding several versions of a row in the table).
xmax is actually used for two purposes in PostgreSQL:
xid”) of the transaction that deleted the tuple, like the documentation says. Remember that UPDATE also deletes a tuple in PostgreSQL!This is possible, because a tuple cannot be locked and deleted at the same time: normal locks are only held for the duration of the transaction, and a tuple is deleted only after the deleting transaction has committed.
Storing row locks on the tuple itself has one vast advantage: it avoids overflows of the “lock table”. The lock table is a fixed-size area that is allocated in shared memory during server startup and could easily be too small to hold all the row locks from a bigger transaction. To cope with this, you'd need techniques like “lock escalation” that are difficult to implement, impact concurrency and lead to all kinds of nasty problems.
There is also a downside to storing row locks in the tuple: each row lock modifies the table, and the modified blocks have to be written back to persistent storage. This means that row locks lead to increased I/O load.
But a number of questions remain:
xmax has in a tuple?xmax is valid or not?We will dive deeper in the rest of this article to answer these questions.
In the following, I'll use a simple schema for demonstration. I am using PostgreSQL v10, but this hasn't changed in the last couple of releases.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE parent( p_id integer PRIMARY KEY, p_val text ); CREATE TABLE child( c_id integer PRIMARY KEY, p_id integer REFERENCES parent(p_id), c_val text ); INSERT INTO parent (p_id, p_val) VALUES (42, 'parent'); |
Now let's look at the relevant system columns:
|
1 2 3 4 5 6 |
session1=# SELECT ctid, xmin, xmax, p_id, p_val FROM parent; ctid | xmin | xmax | p_id | p_val -------+-------+------+------+-------- (0,1) | 53163 | 0 | 42 | parent (1 row) |
This is the simple view we expect to see: ctid is the physical location of the tuple (Block 0, item 1), xmin contains the ID of the inserting transaction, and xmax is zero because the row is alive.
Now let's start a transaction in session 1 and delete the row:
|
1 2 |
session1=# BEGIN; session1=# DELETE FROM parent WHERE p_id = 42; |
Then session 2 can see that xmax has changed:
|
1 2 3 4 5 6 |
session2=# SELECT ctid, xmin, xmax, p_id, p_val FROM parent; ctid | xmin | xmax | p_id | p_val -------+-------+-------+------+-------- (0,1) | 53163 | 53165 | 42 | parent (1 row) |
But wait, we change our mind in session 1 and undo the change:
|
1 |
session1=# ROLLBACK; |
To find out what xmax means in this case, let's call in the cavalry.
pageinspect comes to the rescuePostgreSQL comes with a “contrib” module called pageinspect that can be used to examine the actual contents of table blocks. It is installed with
|
1 |
CREATE EXTENSION pageinspect; |
We'll use two of its functions:
get_raw_page: reads one 8kB block from the table's data fileheap_page_item_attrs: for each tuple in a data block, this returns the tuple metadata and dataNeedless to say, these functions are superuser only.
heap_page_item_attrs returns an integer field named t_infomask that contains several flags, some of which tell us the meaning of xmax. To get the full story, you'll have to read the code in src/include/access/htup_details.h.
Let's have a look at table block 0, which contains our tuple:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
session2=# SELECT lp, t_ctid AS ctid, t_xmin AS xmin, t_xmax AS xmax, (t_infomask & 128)::boolean AS xmax_is_lock, (t_infomask & 1024)::boolean AS xmax_committed, (t_infomask & 2048)::boolean AS xmax_rolled_back, (t_infomask & 4096)::boolean AS xmax_multixact, t_attrs[1] AS p_id, t_attrs[2] AS p_val FROM heap_page_item_attrs( get_raw_page('parent', 0), 'parent' ); -[ RECORD 1 ]----+----------------- lp | 1 ctid | (0,1) xmin | 53163 xmax | 53165 xmax_is_lock | f xmax_committed | f xmax_rolled_back | f xmax_multixact | f p_id | x2a000000 p_val | x0f706172656e74 |
The attributes p_id and p_val are displayed in binary form.
The information in the tuple doesn't tell us whether the transaction that set xmax has been committed or rolled back, so we (and PostgreSQL when it inspects the tuple) still don't know what to make of xmax. That is because PostgreSQL does not update the tuple when a transaction ends.
To resolve that uncertainty, we'd have to look at the commit log that stores the state of each transaction. The commit log is persisted in the pg_xact subdirectory of the PostgreSQL data directory (pg_clog in older versions).
SELECT that modifies dataWe cannot examine the commit log from SQL, but when any database transaction reads the tuple and looks up the commit log, it will persist the result in the tuple so that the next reader does not have to do it again (this is called “setting the hint bits”).
So all we have to do is to read the tuple:
|
1 2 3 4 5 6 |
session2=# SELECT ctid, xmin, xmax, p_id, p_val FROM parent; ctid | xmin | xmax | p_id | p_val -------+-------+-------+------+-------- (0,1) | 53163 | 53165 | 42 | parent (1 row) |
This changes the information stored in the tuple. Let's have another look with pageinspect:
|
1 2 3 4 5 6 7 8 9 10 11 |
-[ RECORD 1 ]----+----------------- lp | 1 ctid | (0,1) xmin | 53163 xmax | 53165 xmax_is_lock | f xmax_committed | f xmax_rolled_back | t xmax_multixact | f p_id | x2a000000 p_val | x0f706172656e74 |
The SELECT statement has set the flags on the tuple, and now we can see that xmax is from a transaction that was rolled back and should be ignored.
As an aside, that means that the first reader of a tuple modifies the tuple, causing surprising write I/O. This is annoying, but it is the price we pay for instant COMMIT and ROLLBACK. It is also the reason why it is a good idea to either use COPY … (FREEZE) to bulk load data or to VACUUM the data after loading.
Now we know how to determine if xmax is from a valid transaction or not, but what about row locks?
xmaxRows are locked by data modifying statements, but there is a simple way to lock a row without inserting or deleting tuples:
|
1 2 3 4 5 6 7 |
session1=# BEGIN; session1=# SELECT * FROM parent WHERE p_id = 42 FOR UPDATE; p_id | p_val ------+-------- 42 | parent (1 row) |
Now what does pageinspect tell us?
|
1 2 3 4 5 6 7 8 9 10 11 |
-[ RECORD 1 ]----+----------------- lp | 1 ctid | (0,1) xmin | 53163 xmax | 53166 xmax_is_lock | t xmax_committed | f xmax_rolled_back | f xmax_multixact | f p_id | x2a000000 p_val | x0f706172656e74 |
We see that the row is locked. In this case, it is a FOR UPDATE lock, but the query does not distinguish between the lock modes for simplicity's sake. You'll notice that xmax again is neither committed nor rolled back, but we don't care because we know it is a row lock.
xmax is set to 53166, which is the transaction ID of the locking transaction. Let's close that transaction to continue:
|
1 |
session1=# COMMIT; |
PostgreSQL does not have to set hint bits here — if xmax contains a row lock, the row is active, no matter what the state of the locking transaction is.
If you think you have seen it all, you are in for a surprise.
In the previous example we have seen that PostgreSQL stores the transaction ID of the locking transaction in xmax. This works fine as long as only a single transaction holds a lock on that tuple. With exclusive locks like the one that SELECT … FOR UPDATE takes, this is always the case.
But PostgreSQL also knows other row locks, for example the FOR KEY SHARE lock that is taken on the destination of a foreign key constraint to prevent concurrent modification of the keys in that row. Let's insert some rows in the child table:
|
1 2 3 4 5 6 7 |
session1=# BEGIN; session1=# INSERT INTO child (c_id, p_id, c_val) VALUES (1, 42, 'first'); session2=# BEGIN; session2=# INSERT INTO child (c_id, p_id, c_val) VALUES (2, 42, 'second'); |
Now let's look at our parent row again:
|
1 2 3 4 5 6 7 8 9 10 11 |
-[ RECORD 1 ]----+----------------- lp | 1 ctid | (0,1) xmin | 53163 xmax | 3 xmax_is_lock | t xmax_committed | f xmax_rolled_back | f xmax_multixact | t p_id | x2a000000 p_val | x0f706172656e74 |
That “3” in xmax cannot be a transaction ID (they keep counting up), and the xmax_multixact flag is set.
This is the ID of a “multiple transaction object”, called “mulitxact” in PostgreSQL jargon for lack of a better word. Such objects are created whenever more than one transaction locks a row, and their IDs are also counted up (you can tell that this database needs few of them). Multixacts are persisted in the pg_multixact subdirectory of the data directory.
You can get information about the members of a multixact with the undocumented pg_get_multixact_members function:
|
1 2 3 4 5 6 |
session2=# SELECT * FROM pg_get_multixact_members('3'); xid | mode -------+------- 53167 | keysh 53168 | keysh (2 rows) |
Now you really know what is in an xmax!
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.

Everybody knows that a database index is a good thing because it can speed up SQL queries. But this does not come for free.
The disadvantages of indexes are:
INSERT into or DELETE from a table, all indexes have to be modified, in addition to the table itself (the “heap”).UPDATE causes a new row version (“tuple”) to be written, and that causes a new entry in every index on the table.VACUUM has to do.Now we know that we don't want unnecessary indexes. The problem is that indexes serve so many purposes that it is difficult to determine if a certain index is needed or not.
Here is a list of all benefits of indexes in PostgreSQL:
WHERE clause.<, <=, =, >= and > operators, while the many other index types in PostgreSQL can support more exotic operators like “overlaps” (for ranges or geometries), “distance” (for words) or regular expression matches.max() and min() aggregates.ORDER BY clauses.FOREIGN KEY constraint avoids a sequential scan when rows are deleted (or keys modified) in the target table. A scan on the origin of the constraint is necessary to make sure that the constraint will not be violated by the modification.PRIMARY KEY and UNIQUE constraints, while exclusion constraints use GiST indexes.ANALYZE and the autoanalyze daemon will not only collect statistics for the data distribution in table columns, but also for each expression that occurs in an index. This helps the optimizer to get a good estimate for the “selectivity” of complicated conditions that contain the indexed expression, which causes better plans to be chosen. This is a widely ignored benefit of indexes!The following query that we at CYBERTEC use will show you all indexes that serve none of the above mentioned purposes.
It makes use of the fact that all uses of indexes in the above list with the exception of the last two result in an index scan.
For completeness' sake, I have to add that the parameter track_counts has to remain “on” for the query to work, otherwise index usage is not tracked in pg_stat_user_indexes. But you must not change that parameter anyway, otherwise autovacuum will stop working.
To find the indexes that have never been used since the last statistics reset with pg_stat_reset(), use
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT s.schemaname, s.relname AS tablename, s.indexrelname AS indexname, pg_relation_size(s.indexrelid) AS index_size FROM pg_catalog.pg_stat_user_indexes s JOIN pg_catalog.pg_index i ON s.indexrelid = i.indexrelid WHERE s.idx_scan = 0 -- has never been scanned AND 0 <>ALL (i.indkey) -- no index column is an expression AND NOT i.indisunique -- is not a UNIQUE index AND NOT EXISTS -- does not enforce a constraint (SELECT 1 FROM pg_catalog.pg_constraint c WHERE c.conindid = s.indexrelid) AND NOT EXISTS -- is not an index partition (SELECT 1 FROM pg_catalog.pg_inherits AS inh WHERE inh.inhrelid = s.indexrelid) ORDER BY pg_relation_size(s.indexrelid) DESC; |
Some remarks:
s.idx_scan = 0 in the query with a different condition, e.g. s.idx_scan < 10. Indexes that are very rarely used are also good candidates for removal.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
When running PostgreSQL on a production system, it might happen that you are facing table bloat. As you might know PostgreSQL has to copy a row on UPDATE to ensure that concurrent transactions can still see the data. At some point VACUUM can clean out dead rows but if transactions are too long, this cleanup might happen quite late and therefore table bloat (= your table keeps growing dramatically) is the logical consequence. Having a table, which has grown out of proportion, will have all kinds of bad side effects including but not limited to bad performance. idle_in_transaction_session_timeout has been added to PostgreSQL 9.6 to prevent bad things from happening in case long idle transactions are around.
Why does PostgreSQL have to copy rows on UPDATE after all? Here is an example:
| Session 1 | Session 2 |
| CREATE TABLE a (aid int); | |
| INSERT INTO a VALUES (5); | |
| BEGIN; | |
| SELECT sum(aid) FROM a; | |
| … running ... | UPDATE a SET aid = 9; |
| … running ... | SELECT * FROM a; |
| … will return 5 ... | … will return 9 ... |
As you can see two results will be returned at the same time at the end of our example. Logically PostgreSQL has to keep both versions of a row. Just imagine if you want to UPDATE 100 million rows – your table will have to keep an additional 100 million rows.
Let us take a look at a second example:
| Session 1 | Session 2 |
| BEGIN; | |
| DELETE FROM a; | |
| … running ... | SELECT * FROM a; |
| … running … | … we will see rows ... |
| COMMIT; | |
| VACUUM a; | |
| … now we can clean out rows ... |
DELETE is not allowed to actually remove those rows. Remember, we can still issue a ROLLBACK so we cannot destroy data yet. The same applies to COMMIT. Concurrent transactions might still see the data. VACUUM can only really reclaim those deleted rows if no other transactions can still see them. And this is exactly where our problem starts: What if a transaction starts but is not closed for a long long time …
A long transaction is actually not a problem – the problem starts if a long transaction and many small changes have to exist. Remember: The long transaction can cause VACUUM to not clean out your dead rows.
Are long transactions evil in general? No: If a long transaction does useful work, it should be allowed to proceed unharmed. But what is a transaction is kept open because of bad coding or for some other reason?
Here is an example:
| Session 1 | Session 2 |
| BEGIN; | |
| SELECT … | |
| … doing nothing ... | UPDATE “huge change” |
| … doing nothing ... | DELETE “huge change” |
| … doing nothing ... | INSERT “huge change” |
| … doing nothing ... | UPDATE “huge change” |
In this case we will end up in trouble at some doing. VACUUM might actually run but it is never allowed to clean out dead rows because a single transaction might still be allowed to see old data. Thus dead rows will keep accumulating as long as “Session 1” exists. PostgreSQL cannot clean dead tuples – even if you keep running VACUUM.
If a transaction is working, it is there for a reason – but if it just hangs around, why not just kill it? This is exactly what idle_in_transaction_session_timeout will do for you. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
test=# SET idle_in_transaction_session_timeout TO '3000'; SET test=# BEGIN; BEGIN test=# SELECT pg_sleep(5); pg_sleep ---------- (1 row) -- going out for a coffee ... test=# SELECT pg_sleep(5); FATAL: terminating connection due to idle-in-transaction timeout server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. |
In this example the timeout is set to 3 seconds (3000 milliseconds). Then we will sleep for 5 seconds, which is no problem at all. However, before the next SELECT there is a long pause – and this is when the session in question will be killed.
In other words: Transactions cannot stay open accidentally anymore as PostgreSQL will clean things out for you.
Note that you don’t have to set things in postgresql.conf globally. The beauty is that you can actually set this variable for a certain database or simply for a specific user. There is no need for making the change globally and suffering from potential side effects.
Settings things for a single user is actually pretty simple. Here is how it works:
|
1 2 3 4 |
test=# CREATE USER joe; CREATE ROLE test=# ALTER USER joe SET idle_in_transaction_session_timeout TO 10000; ALTER ROLE |
If you want to figure out if there is table bloat in your database or not: Consider checking out the pgstattuple extension, which has been covered in one of our older posts: /en/detecting-table-bloat/
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
SQL is a must, if you want to be a Data Analyst or a Data Scientist. However, every once in a while people wonder why a result is the way it is. While on the road in Berlin (Germany) the other day, I found a fairly interesting window function scenario which is pretty counter-intuitive to most people, and which might be worth sharing.
PostgreSQL has provided window functions and analytics for quite some time now and this vital feature has been widely adopted by users, who are using PostgreSQL or SQL in general for more than just trivial queries. A modern database is just so much more than a simple data store and window functions are therefore certainly something to look into.
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# SELECT *, first_value(x) OVER (ORDER BY x) FROM generate_series(1, 5) AS x; x | first_value ---+------------- 1 | 1 2 | 1 3 | 1 4 | 1 5 | 1 (5 rows) |
What we want, is the first value in our data set. The ORDER BY clause will ensure that data is fed to first_value in the right order. The result is therefore not surprising.
DESC to our ORDER BY. The result is totally obvious:|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SELECT *, first_value(x) OVER (ORDER BY x), first_value(x) OVER (ORDER BY x DESC) FROM generate_series(1, 5) AS x; x | first_value | first_value ---+-------------+------------- 5 | 1 | 5 4 | 1 | 5 3 | 1 | 5 2 | 1 | 5 1 | 1 | 5 (5 rows) |
However, what if we use last_value. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SELECT *, last_value(x) OVER (ORDER BY x), last_value(x) OVER (ORDER BY x DESC) FROM generate_series(1, 5) AS x; x | last_value | last_value ---+------------+------------ 5 | 5 | 5 4 | 4 | 4 3 | 3 | 3 2 | 2 | 2 1 | 1 | 1 (5 rows) |
What you can see here is that both columns will return the SAME data – regardless of the different sort order provided by the ORDER BY clause. That comes as a surprise to most people. Actually most people would accept one column to contain only “5” and the other column to contain only “1”.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SELECT *, array_agg(x) OVER (ORDER BY x), array_agg(x) OVER (ORDER BY x DESC) FROM generate_series(1, 5) AS x; x | array_agg | array_agg ---+-------------+------------- 5 | {1,2,3,4,5} | {5} 4 | {1,2,3,4} | {5,4} 3 | {1,2,3} | {5,4,3} 2 | {1,2} | {5,4,3,2} 1 | {1} | {5,4,3,2,1} (5 rows) |
Let us take a look at which values last_value will actually see: array_agg will simply put them all into an array so that we can expect things in detail. As you can see, the last value in the array is identical in both cases, which means that both columns will produce exactly the identical output.