
Sometimes you want to enforce a condition on a table that cannot be implemented by a constraint. In such a case it is tempting to use triggers instead. This article describes how to do this and what to watch out for.
It will also familiarize you with the little-known PostgreSQL feature of “constraint triggers”.
Suppose we have a table of prisons and a table of prison guards:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE SCHEMA jail_app; CREATE TABLE jail_app.prison ( prison_id integer PRIMARY KEY, prison_name text NOT NULL ); INSERT INTO jail_app.prison (prison_id, prison_name) VALUES (1, 'Karlau'), (2, 'Stein'); CREATE TABLE jail_app.guard ( guard_id integer PRIMARY KEY, guard_name text NOT NULL ); INSERT INTO jail_app.guard (guard_id, guard_name) VALUES (41, 'Alice'), (42, 'Bob'), (43, 'Chris'); |
Then we have a junction table that stores which guard is on duty in which prison:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE jail_app.on_duty ( prison_id integer REFERENCES prison, guard_id integer REFERENCES guard, PRIMARY KEY (prison_id, guard_id) ); INSERT INTO jail_app.on_duty (prison_id, guard_id) VALUES (1, 41), (2, 42), (2, 43); |
So, Alice is on duty in Karlau, and Bob and Chris are on duty in Stein.
As guards go on and off duty, rows are added to and deleted from on_duty. We want to establish a constraint that at least one guard has to be on duty in any given prison.
Unfortunately there is no way to write this as a normal database constraint (if you are tempted to write a CHECK constraint that counts the rows in the table, think again).
But it would be easy to write a BEFORE DELETE trigger that ensures the condition:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE FUNCTION jail_app.checkout_trig() RETURNS trigger LANGUAGE plpgsql AS $$BEGIN IF (SELECT count(*) FROM jail_app.on_duty WHERE prison_id = OLD.prison_id ) < 2 THEN RAISE EXCEPTION 'sorry, you are the only guard on duty'; END IF; RETURN OLD; END;$$; CREATE TRIGGER checkout_trig BEFORE DELETE ON jail_app.on_duty FOR EACH ROW EXECUTE PROCEDURE jail_app.checkout_trig(); |
But, as we will see in the next section, we made a crucial mistake here.
Imagine Bob wants to go off duty.
The prison guard application runs a transaction like the following:
|
1 2 3 4 5 6 7 8 |
START TRANSACTION; DELETE FROM jail_app.on_duty WHERE guard_id = (SELECT guard_id FROM jail_app.guard WHERE guard_name = 'Bob'); COMMIT; |
Now if Chris happens to have the same idea at the same time, the following could happen (the highlighted lines form a second, concurrent transaction):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
START TRANSACTION; DELETE FROM jail_app.on_duty WHERE guard_id = (SELECT guard_id FROM jail_app.guard WHERE guard_name = 'Bob'); START TRANSACTION; DELETE FROM jail_app.on_duty WHERE guard_id = (SELECT guard_id FROM jail_app.guard WHERE guard_name = 'Chris'); COMMIT; COMMIT; |
Now the first transaction has not yet committed when the second UPDATE runs, so the trigger function running in the second transaction cannot see the effects of the first update. That means that the second transaction succeeds, both guards go off duty, and the prisoners can escape.
You may think that this is a rare occurrence and you can get by ignoring that race condition in your application. But don't forget there are bad people out there, and they may attack your application using exactly such a race condition (in the recent fad of picking impressive names for security flaws, this has been called an ACIDRain attack).
Given the above, you may wonder if regular constraints are subject to the same problem. After all, this is a consequence of PostgreSQL's multi-version concurrency control (MVCC).
When checking constraints, PostgreSQL also checks rows that would normally not be visible to the current transaction. This is against the normal MVCC rules but guarantees that constraints are not vulnerable to this race condition.
You could potentially do the same if you write a trigger function in C, but few people are ready to do that. With trigger functions written in any other language, you have no way to “peek” at uncommitted data.
We can avoid the race condition by explicitly locking the rows we check. This effectively serializes data modifications, so it reduces concurrency and hence performance.
Don't consider locking the whole table, even if it seems a simpler solution.
Our trigger now becomes a little more complicated. We want to avoid deadlocks, so we will make sure that we always lock rows in the same order. For this we need a statement level trigger with a transition table (new since v10):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE OR REPLACE FUNCTION jail_app.checkout_trig() RETURNS trigger LANGUAGE plpgsql AS $$BEGIN IF EXISTS ( WITH remaining AS ( /* of the prisons where somebody went off duty, select those which have a guard left */ SELECT on_duty.prison_id FROM jail_app.on_duty JOIN deleted ON on_duty.prison_id = deleted.prison_id ORDER BY on_duty.prison_id, on_duty.guard_id /* lock those remaining entries */ FOR KEY SHARE OF on_duty ) SELECT prison_id FROM deleted EXCEPT SELECT prison_id FROM remaining ) THEN RAISE EXCEPTION 'cannot leave a prison without guards'; END IF; RETURN NULL; END;$$; DROP TRIGGER IF EXISTS checkout_trig ON jail_app.on_duty; CREATE TRIGGER checkout_trig AFTER DELETE ON jail_app.on_duty REFERENCING OLD TABLE AS deleted FOR EACH STATEMENT EXECUTE PROCEDURE jail_app.checkout_trig(); |
This technique is called “pessimistic locking” since it expects that there will be concurrent transactions that “disturb” our processing. Such concurrent transactions are preemptively blocked. Pessimistic locking is a good strategy if conflicts are likely.
Different from pessimistic locking, “optimistic locking” does not actually lock the contended objects. Rather, it checks that no concurrent transaction has modified the data between the time we read them and the time we modify the database.
This improves concurrency, and we don't have to change our original trigger definition. The downside is that we must be ready to repeat a transaction that failed because of concurrent data modifications.
The most convenient way to implement optimistic locking is to raise the transaction isolation level. In our case, REPEATABLE READ is not enough to prevent inconsistencies, and we'll have to use SERIALIZABLE.
All transactions that access jail_app.on_duty must start like this:
|
1 |
START TRANSACTION ISOLATION LEVEL SERIALIZABLE; |
Then PostgreSQL will make sure that concurrent transactions won't succeed unless they are serializable. That means that the transactions can be ordered so that serial execution of the transactions in this order would produce the same result.
If PostgreSQL cannot guarantee this, it will terminate one of the transactions with
|
1 2 3 |
ERROR: could not serialize access due to read/write dependencies among transactions HINT: The transaction might succeed if retried. |
This is a serialization error (SQLSTATE 40001) and doesn't mean that you did something wrong. Such errors are normal with isolation levels above READ COMMITTED and tell you to simply retry the transaction.
Optimistic locking is a good strategy if conflicts are expected to occur only rarely. Then you don't have to pay the price of repeating the transaction too often.
It should be noted that SERIALIZABLE comes with a certain performance hit. This is because PostgreSQL has to maintain additional “predicate locks”. See the documentation for performance considerations.
Finally, PostgreSQL has the option to create “constraint triggers” with CREATE CONSTRAINT TRIGGER. It sounds like such triggers could be used to avoid the race condition.
Constraint triggers respect the MVCC rules, so they cannot “peek” at uncommitted rows of concurrent transactions. But the trigger execution can be deferred to the end of the transaction. They also have an entry in the pg_constraint system catalog.
Note that constraint triggers have to be AFTER triggers FOR EACH ROW, so we will have to rewrite the trigger function a little:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE OR REPLACE FUNCTION jail_app.checkout_trig() RETURNS trigger LANGUAGE plpgsql AS $$BEGIN -- the deleted row is already gone in an AFTER trigger IF (SELECT count(*) FROM jail_app.on_duty WHERE prison_id = OLD.prison_id ) < 1 THEN RAISE EXCEPTION 'sorry, you are the only guard on duty'; END IF; RETURN OLD; END;$$; DROP TRIGGER IF EXISTS checkout_trig ON jail_app.on_duty; CREATE CONSTRAINT TRIGGER checkout_trig AFTER DELETE ON jail_app.on_duty DEFERRABLE INITIALLY DEFERRED FOR EACH ROW EXECUTE PROCEDURE jail_app.checkout_trig(); |
By making the trigger INITIALLY DEFERRED, we tell PostgreSQL to check the condition at COMMIT time. This will reduce the window for the race condition a little, but the problem is still there. If concurrent transactions run the trigger function at the same time, they won't see each other's modifications.
If constraint triggers don't live up to the promise in their name, why do they have that name? The answer is in the history of PostgreSQL: CREATE CONSTRAINT TRIGGER was originally used “under the hood” to create database constraints. Even though that is no more the case, the name has stuck. “Deferrable trigger” would be a better description.
If you don't want to be vulnerable to race conditions with a trigger that enforces a constraint, use locking or higher isolation levels.
Constraint triggers are not a solution.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
Have you ever heard about cursors in PostgreSQL or in SQL in general? If not you should definitely read this article in depth and learn how to reduce memory consumption in PostgreSQL easily. Cursors have been around for many years and are in my judgement one of the most underappreciated feature of all times. Therefore, it makes sense to take a closer look at cursors and see what they can be used for.
Consider the following example:
|
1 2 3 4 5 |
test=# CREATE TABLE t_large (id int); CREATE TABLE test=# INSERT INTO t_large SELECT * FROM generate_series(1, 10000000); INSERT 0 10000000 |
I have created a table, which contains 10 million rows so that we can play with the data. Let us run a simple query now:
|
1 2 3 4 5 6 7 |
test=# SELECT * FROM t_large; id ---------- 1 2 3 … |
The first thing you will notice is that the query does not return immediately. There is a reason for that: PostgreSQL will send the data to the client and the client will return as soon as ALL the data has been received. If you happen to select a couple thousand rows, life is good, and everything will be just fine. However, what happens if you do a “SELECT * ...” on a table containing 10 billion rows? Usually the client will die with an “out of memory” error and your applications will simply die. There is no way to keep such a large table in memory. Throwing even more RAM at the problem is not feasible either.
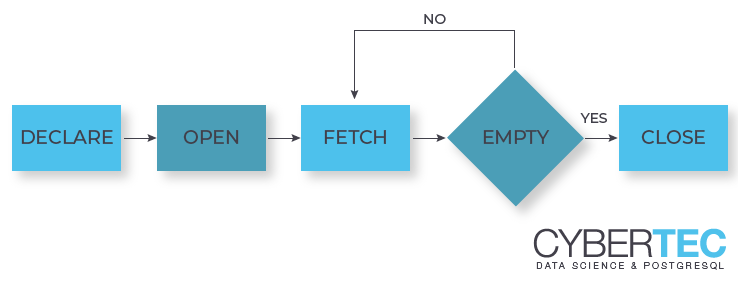
DECLARE CURSOR and FETCH can come to the rescue. What is the core idea? We can fetch data in small chunks and only prepare the data at the time it is fetched - not earlier. Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=# BEGIN; BEGIN test=# DECLARE mycur CURSOR FOR SELECT * FROM t_large WHERE id > 0; DECLARE CURSOR test=# FETCH NEXT FROM mycur; id ---- 1 (1 row) test=# FETCH 4 FROM mycur; id ---- 2 3 4 5 (4 rows) test=# COMMIT; COMMIT |
The first important thing to notice is that a cursor can only be declared inside a transaction. However, there is more: The second important this is that DECLARE CURSOR itself is lightning fast. It does not calculate the data yet but only prepares the query so that your data can be created when you call FETCH. To gather all the data from the server you can simply run FETCH until the resultset is empty. At the you can simply commit the transaction.
Note that a cursor is closed on commit as you can see in the next listing:
|
1 2 3 |
test=# FETCH 4 FROM mycur; ERROR: cursor 'mycur' does not exist test |
The FETCH command is ways more powerful than most people think. It allows you to navigate in your resultset and fetch rows as desired:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=# h FETCH Command: FETCH Description: retrieve rows from a query using a cursor Syntax: FETCH [ direction [ FROM | IN ] ] cursor_name where direction can be empty or one of: NEXT PRIOR FIRST LAST ABSOLUTE count RELATIVE count count ALL FORWARD FORWARD count FORWARD ALL BACKWARD BACKWARD count BACKWARD ALL |
Cursors are an easy and efficient way to retrieve data from the server. However, you have to keep one thing in mind: Latency. Asking the network for one row at a time will add considerable network overhead (latency). It therefore makes sense to fetch data in reasonably large chunks. I found it useful to fetch 10.000 rows at a time. 10.000 can still reside in memory easily while still ensuring reasonably low networking overhead. Of course, I highly encourage you to do your own experience to see, what is best in your specific cases.
Cursors are treated by the optimizer in a special way. If you are running a “normal” statement PostgreSQL will optimize for total runtime. It will assume that you really want all the data and optimize accordingly. However, in case of a cursor it assumes that only a fraction of the data will actually be consumed by the client. The following example shows, how this works:
|
1 2 3 4 5 6 7 8 |
test=# CREATE TABLE t_random AS SELECT random() AS r FROM generate_series(1, 1000000); SELECT 1000000 test=# CREATE INDEX idx_random ON t_random (r); CREATE INDEX test=# ANALYZE ; ANALYZE |
I have created a table, which contains 1 million random rows. Finally, I have created a simple index. To make sure that the example works I have told the optimizer that indexes are super expensive (random_page_cost):
|
1 2 |
test=# SET random_page_cost TO 100; SET |
Let us take a look at an example now: If the query is executed as cursor you will notice that PostgreSQL goes for an index scan to speed up the creation of the first 10% of the data. If the entire resultset is fetched, PostgreSQL will go for a sequential scan and sort the data because the index scan is considered to be too expensive:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
test=# BEGIN; BEGIN test=# explain DECLARE cur CURSOR FOR SELECT * FROM t_random ORDER BY r; QUERY PLAN ------------------------------------------------------------------------------------------- Index Only Scan using idx_random on t_random (cost=0.42..732000.04 rows=1000000 width=8) (1 row) test=# explain SELECT * FROM t_random ORDER BY r; QUERY PLAN ------------------------------------------------------------------------------------- Gather Merge (cost=132326.50..229555.59 rows=833334 width=8) Workers Planned: 2 -> Sort (cost=131326.48..132368.15 rows=416667 width=8) Sort Key: r -> Parallel Seq Scan on t_random (cost=0.00..8591.67 rows=416667 width=8) (5 rows) test=# COMMIT; COMMIT |
The main question arising now is: How does the optimizer know that the first 10% should be fast and that we are not looking for the entire resultset? A runtime setting is going to control this kind of behavior: cursor_tuple_fraction will configure this kind of behavior:
|
1 2 3 4 5 |
test=# SHOW cursor_tuple_fraction; cursor_tuple_fraction ----------------------- 0.1 (1 row) |
The default value is 0.1, which means that PostgreSQL optimizes for the first 10%. The parameter can be changed easily in postgresql.conf just for your current session.
So far you have seen that a cursor can only be used inside a transaction. COMMIT or ROLLBACK will destroy the cursor. However, in some (usually rare) cases it can be necessary to have cursors, which actually are able to survive a transaction. Fortunately, PostgreSQL has a solution to the problem: WITH HOLD cursors.
Here is how it works:
|
1 2 3 4 5 6 7 8 9 10 |
test=# BEGIN; BEGIN test=# DECLARE cur CURSOR WITH HOLD FOR SELECT * FROM t_random ORDER BY r; DECLARE CURSOR test=# timing Timing is on. test=# COMMIT; COMMIT Time: 651.211 ms |
As you can see the WITH HOLD cursor has been declared just like a normal cursor. The interesting part is the COMMIT: To make sure that the data can survive the transaction PostgreSQL has to materialize the result. Therefore, the COMMIT takes quite some time. However, the FETCH can now happen after the COMMIT:
|
1 2 3 4 5 6 7 8 |
test=# FETCH 4 FROM cur; r ---------------------- 2.76602804660797e-07 6.17466866970062e-07 3.60095873475075e-06 4.77954745292664e-06 (4 rows) |
If you are making use of WITH HOLD cursors you have to keep in mind that the cursor has to be closed as well. Otherwise your connection will keep accumulating new cursors and store the result.
|
1 2 3 4 5 |
test=# h CLOSE Command: CLOSE Description: close a cursor Syntax: CLOSE { name | ALL } |
Do you want to learn more about PostgreSQL and the optimizer in general consider? Check out one of our blog posts right now.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
Needless to say, security is a topic that nobody in the wider IT industry can ignore nowadays, with a constant flow of reports on data breaches of various scales. Most of such cases don’t result from direct attacks against databases though, but more from targeting Application / API / Webserver problems as database servers are usually just not directly exposed to the Internet. And even if they were, PostgreSQL installations at least have a good starting point there, as the default settings are sane enough to only listen to local connections by default, preventing from most embarrassing kind of headlines. But of course, PostgreSQL setups can also be compromised in many ways, so here’s a short listing of possible threats and some simple suggestions to mitigate those PostgreSQL security threats, if possible.
This my friends, is the #1 point of danger in my opinion, so an appropriate time to repeat the classics - ”with great power comes great responsibility”. Superuser accounts are of course needed for maintenance so cannot be really disabled...but mostly they are vastly overused, even for simple things like normal schema evolution, which can be (mostly) perfectly managed with standard "owner privileges". But Ok, about the threats - there's the obvious: pumping out / dropping all table data. But the most important thing to remember – superusers can execute random commands on the OS level, under PostgreSQL process owner privileges. The easiest way to do that is to use the relatively unknown PROGRAM variation of the COPY command, which is also nicely documented as such. Some other methods to achieve the same that are quite hidden and sneaky:
This attack assumes that the server has been setup for passwordless communication / data transfer over SSH using default settings (which is very common). The trick itself is disturbingly easy - just create a table with a single text field and execute something like that:
|
1 2 3 4 |
krl@postgres=# create table ssh(data text); CREATE TABLE krl@postgres=# copy ssh from program 'cat ~/.ssh/id_rsa.pub' COPY 1 |
The rest should be obvious - copy the key to a local RSA key file...and “ssh” to the machine. Given here you know the operating system user under which Postgres is running – most often it will be the default “postgres” or the key itself could include it. From there a malicious use can easily find some security holes on old unpatched systems and possibly advance to “root”, doing additional harm outside of PostgreSQL, meaning possible “game over” situation for the whole business. FYI - “COPY PROGRAM” works with Postgres 9.3 and newer, and sadly there’s no configuration flag to disable it. Functionality is only available to superusers though.
When archiving is enabled, this seemingly innocent parameter can be abused to do nasty things. An example:
|
1 2 3 |
ALTER SYSTEM SET archive_command = 'rm -rf /home/postgres'; SELECT pg_reload_conf(); SELECT pg_switch_wal(); -- oopsie |
From version 10 onward, it’s possible to define “virtual” tables that gather data from an external program’s output, with “legal” use cases encompassing reading compressed files and maybe some Webservice usage...but the command could be abused the same way as with previous example, Postgres just executes the command “as is”.
|
1 2 3 4 |
CREATE EXTENSION file_fdw; CREATE SERVER csv FOREIGN DATA WRAPPER file_fdw; CREATE FOREIGN TABLE test(data text) SERVER csv OPTIONS (program 'rm -rf /home/postgres'); SELECT * FROM test; -- #$@&%*! |
When for example PL/Pythonu is installed it also childs' play to execute random commands:
|
1 2 3 4 5 6 7 8 |
CREATE FUNCTION evil_stuff() RETURNS void LANGUAGE plpythonu AS $SQL$ import subprocess subprocess.call(['rm', '-rf', '/var/lib/postgresql/']) $SQL$; SELECT evil_stuff(); |
Mitigation: as limiting superuser actions is very difficult (the provided threat examples, excluding COPY PROGRAM, can be mitigated with careful setup though) so the only real strategy is - applications should be designed so that superuser access is not needed. And this should be very doable for 99% of users as for example fully managed PostgreSQL services, where you never get superuser access, have become quite popular among developers. Basic principle – hand out superuser access only to those who have physical server access also, as one can basically draw an equality sign between the two (see the above section about COPY PROGRAM).
Second place on my personal threat list goes to weak passwords. What makes up for a weak password is probably debatable...but for me they are some shortish (<10 chars) words or names taken from English speaking domain, combined maybe with some number, i.e. anything that is too short and not randomly generated. The problem is that for such password there are quite some “top” lists available for download after some short Googling, like the “Top 1 Million most common passwords” here.
So, what can you do with such lists in PostgreSQL context? Well, quite a bit...given that by default Postgres weirdly enough has no protection against brute-force password guessing! And brute force is extremely easy to perform, for example with something like that (disclaimer: you might get into trouble if trying to run that on a database that you don’t control anyways):
|
1 2 3 4 5 6 7 |
sudo apt install -y hydra curl -s https://raw.githubusercontent.com/danielmiessler/SecLists/master/Passwords/Common-Credentials/10-million-password-list-top-1000000.txt > top-1m-pw.txt hydra -l postgres -P top-1m-pw.txt postgres://mydb:5432 ... [STATUS] 17389.00 tries/min, 17389 tries in 00:01h, 982643 to do in 00:57h, 16 active ... # … and maybe after some time, voila! |
Couldn’t be easier. On my laptop, connecting to ‘localhost’, the tool managed ~290 connection attempts per second...which is not too much though, being a generic framework. So with some simple (single-threaded only, leaving lots to improve) custom Go code I managed to double it...so in short if you have a really weak password it could only take less than an hour before someones eyes will start glowing with excitement:)
Mitigation: 1) Use long, random passwords. 2) Install and configure the relatively unknown “auth_delay” contrib extension, that will halt the communication for a moment (configurable) in case a login attempt fails, making it slower to guess the passwords, even when opening many connections in parallel. Attention RDS Postgres users - funnily enough the extension is not whitelisted, so better make sure your passwords are good. 3) Actively monitor the server logs – doing full power brute-forcing generates many GB-s of logs per hour with FATAL entries, which should be picked up by a good monitoring setup.
Out of the box PostgreSQL is not immune to this quite a known security risk, where the main threat is that with some work someone can intercept / proxy all communication and also reverse engineer the password hashes (given default md5 hashes used) when they have access to the network for longer periods.
Mitigation: 1) As a minimum force SSL connections. Just remember that enabling “ssl” in the postgresql.conf doesn’t cut it, it needs to be enforced additionally also in the pg_hba.conf. 2) Phase out “md5” passwords in favor of the newer and more secure “scram-sha-256” - not all drivers sadly support it still as it's relatively new :/ 3) When highest confidence is needed – employ certificates i.e. use “verify-ca“ or “verify-full” SSL modes when connecting.
That’s a classic mistake. I’ve seen plenty of setups with very tight “online” access...but where at the end of the day Postgres backups or server logs (server logs can possibly also contain plain text passwords!) are placed onto a backup server together with some application server logs where more people have access to them, to for example analyze some other aspects of application behaviour. In encrypted form this would be of course somewhat OK, but just using a different folder and hoping application is a disaster waiting to happen.
Mitigation: 1) Clearly separate database backups / logs from anything else so that only DBAs would have access. 2) Use "at rest" encryption.
This one might be also a minor one as it assumes a malicious inside job or an accident by non-aware Postgres user. The fact is that at default settings, all users with login rights, even the normal unprivileged ones, could create both persistent and temporary objects (mostly tables) in the default "public" schema. That is of course not bad "per se" and adds convenience but can again be abused - to create a table and insert so many rows into it (think generate_series) that server IO is depleted, or the disk space runs eventually out and Postgres crashes.
Mitigation: 1) Don't use "public" schema at all for important applications and create app specific schemas. 2) When already using "public" schema, then for those systems where temporary / auxiliary tables should actually not be needed for normal users, one should strip the CREATE rights from everyone besides maybe the schema owner. In SQL this would be something like:
|
1 2 3 |
REVOKE CREATE ON SCHEMA public FROM PUBLIC; -- then hand out grants for those who really need them GRANT CREATE ON SCHEMA public TO app_owner_role; |
3) For more or less similar reasons also set the "temp_file_limit" parameter to some reasonably low value. The parameter controls how much disk space all temporary files of a query can maximally occupy. This is relevant only for transparent temp files caused by heavy queries though.
As a last threat, as with any services accessible over the Internet, also databases could fall under a DDoS attack if you have managed to annoy some competing companies or interest groups enough. And here actually there’s nothing that can be done on the Postgres side – even when you’ll configure the Host-based access config (pg_hba.conf) to “reject” all connection attempts from all unwanted IP ranges, it would be too much for the server to handle. This kind of filtering needs to happen one level lower in the stack, but luckily there are lots of software products / services acting as gateways to your DB (just Google “cloud based ddos protection”) filtering packets coming from known botnets and such. Some IaaS providers on who's hardware your VMs are possibly running also have some basic protection often built-in. With DDoS the only consolidation is that you’re not losing any data but "just" revenue / customers.
Mitigation: 1) Try to avoid direct public access to your database. 2) Invest in some anti-DDoS service.
So that was my security checklist. Hope it made you think and maybe also go and check / change some server settings 🙂 Thanks for reading and please let me know in the comments section if I missed something important.
Read on to find out the latest about PostgreSQL and security: investigate our security tag archive.

It is a frequent complaint that count(*) is so slow on PostgreSQL.
In this article I want to explore the options you have to get your result as fast as possible. Added bonus: I'll show you how to estimate query result counts.
count(*) so slow?Most people have no trouble understanding that the following is slow:
|
1 2 |
SELECT count(*) FROM /* complicated query */; |
After all, it is a complicated query, and PostgreSQL has to calculate the result before it knows how many rows it will contain.
But many people are appalled if the following is slow:
|
1 |
SELECT count(*) FROM large_table; |
Yet if you think again, the above still holds true: PostgreSQL has to calculate the result set before it can count it. Since there is no “magical row count” stored in a table (like it is in MySQL's MyISAM), the only way to count the rows is to go through them.
So count(*) will normally perform a sequential scan of the table, which can be quite expensive.
*” in count(*) the problem?The “*” in SELECT * FROM ... is expanded to all columns. Consequently, many people think that using count(*) is inefficient and should be written count(id) or count(1) instead.
But the “*” in count(*) is quite different, it just means “row” and is not expanded at all (actually, that is a “zero-argument aggregate”). Writing count(1) or count(id) are actually slower than count(*), because they have to test if the argument IS NULL or not (count, like most aggregates, ignores NULL arguments).
So there is nothing to be gained by avoiding the “*”.
It is tempting to scan a small index rather than the whole table to count the number of rows.
However, this is not so simple in PostgreSQL because of its multi-version concurrency control strategy. Each row version (“tuple”) contains the information to which database snapshot it is visible. But this information is not (redundantly) stored in the indexes. So it usually isn't enough to count the entries in an index, because PostgreSQL has to visit the table entry (“heap tuple”) to make sure an index entry is visible.
To mitigate this problem, PostgreSQL has introduced the visibility map, a data structure that stores if all tuples in a table block are visible to everybody or not.
If most table blocks are all-visible, an index scan doesn't need to visit the heap tuple often to determine visibility. Such an index scan is called “index only scan”, and with that it is often faster to scan the index to count the rows.
Now it is VACUUM that maintains the visibility map, so make sure that autovacuum runs often enough on the table if you want to use a small index to speed up count(*).
I wrote above that PostgreSQL does not store the row count in the table.
Maintaining such a row count would be an overhead that every data modification has to pay for a benefit that no other query can reap. This would be a bad bargain. Moreover, since different queries can see different row versions, the counter would have to be versioned as well.
But there is nothing that keeps you from implementing such a row counter yourself.
Suppose you want to keep track of the number of rows in the table mytable. You can do that as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
START TRANSACTION; CREATE TABLE mytable_count(c bigint); CREATE FUNCTION mytable_count() RETURNS trigger LANGUAGE plpgsql AS $$BEGIN IF TG_OP = 'INSERT' THEN UPDATE mytable_count SET c = c + 1; RETURN NEW; ELSIF TG_OP = 'DELETE' THEN UPDATE mytable_count SET c = c - 1; RETURN OLD; ELSE UPDATE mytable_count SET c = 0; RETURN NULL; END IF; END;$$; CREATE CONSTRAINT TRIGGER mytable_count_mod AFTER INSERT OR DELETE ON mytable DEFERRABLE INITIALLY DEFERRED FOR EACH ROW EXECUTE PROCEDURE mytable_count(); -- TRUNCATE triggers must be FOR EACH STATEMENT CREATE TRIGGER mytable_count_trunc AFTER TRUNCATE ON mytable FOR EACH STATEMENT EXECUTE PROCEDURE mytable_count(); -- initialize the counter table INSERT INTO mytable_count SELECT count(*) FROM mytable; COMMIT; |
We do everything in a single transaction so that no data modifications by concurrent transactions can be “lost” due to race conditions.
This is guaranteed because CREATE TRIGGER locks the table in SHARE ROW EXCLUSIVE mode, which prevents all concurrent modifications.
The down side is of course that all concurrent data modifications have to wait until the SELECT count(*) is done.
This provides us with a really fast alternative to count(*), but at the price of slowing down all data modifications on the table. Using a deferred constraint trigger will make sure that the lock on the row in mytable_count is held as short as possible to improve concurrency.
Even though this counter table might receive a lot of updates, there is no danger of “table bloat” because these will all be HOT updates.
count(*)Sometimes the best solution is to look for an alternative.
Often an approximation is good enough and you don't need the exact count. In that case you can use the estimate that PostgreSQL uses for query planning:
|
1 2 3 |
SELECT reltuples::bigint FROM pg_catalog.pg_class WHERE relname = 'mytable'; |
This value is updated by both autovacuum and autoanalyze, so it should never be much more than 10% off. You can reduce autovacuum_analyze_scale_factor for that table so that autoanalyze runs more often there.
Up to now, we have investigated how to speed up counting the rows of a table.
But sometimes you want to know how many rows a SELECT statement will return without actually running it.
Obviously the only way to get an exact answer to this is to execute the query. But if an estimate is good enough, you can use PostgreSQL's optimizer to get it for you.
The following simple function uses dynamic SQL and EXPLAIN to get the execution plan for the query passed as argument and returns the row count estimate:
|
1 2 3 4 5 6 7 8 9 |
CREATE FUNCTION row_estimator(query text) RETURNS bigint LANGUAGE plpgsql AS $$DECLARE plan jsonb; BEGIN EXECUTE 'EXPLAIN (FORMAT JSON) ' || query INTO plan; RETURN (plan->0->'Plan'->>'Plan Rows')::bigint; END;$$; |
Do not use this function to process untrusted SQL statements, since it is by nature vulnerable to SQL injection.
For further information on this topic, see Hans' blog post about Speeding up count(*): Why you shouldn't use max(id) – min(id)
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
+43 (0) 2622 93022-0
office@cybertec.at