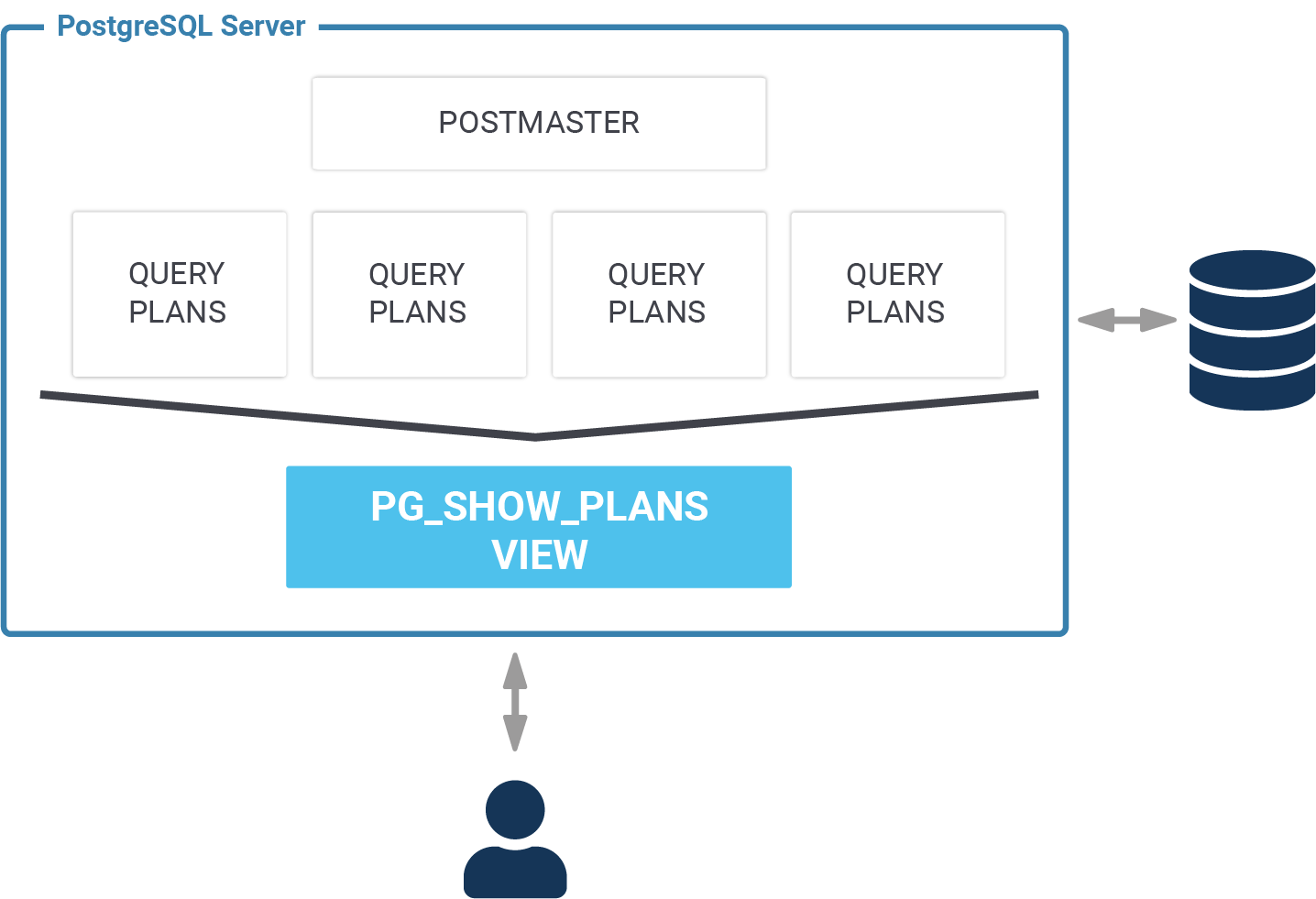
After 20 years in professional PostgreSQL support and consulting we are finally able to answer one of the most frequently asked questions: “How can I see all active query/ execution plans?" Ladies and gentlemen, let me introduce you to pg_show_plans, an extension which does exactly that. pg_show_plans is Open Source and can be used free of charge as a standard PostgreSQL extension. It will help people to diagnose problems more efficiently and help to digging into more profound performance issues.
pg_show_plans uses a set of hooks in the PostgreSQL core to extract all the relevant information. These plans are then stored in shared memory and exposed via a view. This makes it possible to access these plans in an easy way.
The performance overhead of pg_show_plans will be discussed in a future blog post. Stay tuned for more information and visit our blog on a regular basis.
pg_show_plans is available on GitHub for free and can be used free of charge.
Just clone the GitHub repo:
|
1 2 3 4 5 6 7 |
iMac:src hs$ git clone https://github.com/cybertec-postgresql/pg_show_plans.git Cloning into 'pg_show_plans'... remote: Enumerating objects: 54, done. remote: Counting objects: 100% (54/54), done. remote: Compressing objects: 100% (25/25), done. remote: Total 54 (delta 31), reused 52 (delta 29), pack-reused 0 Unpacking objects: 100% (54/54), done. |
Then “cd” into the directory and set USE_PGXS. USE_PGXS is important if you want to compile the code outside of the PostgreSQL source tree:
|
1 2 |
iMac:src hs$ cd pg_show_plans iMac:pg_show_plans hs$ export USE_PGXS=1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
iMac:pg_show_plans hs$ make gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -Wno-unused-command-line-argument -g -O2; -I. -I./ -I/Users/hs/pg12/include/postgresql/server -I/Users/hs/pg12/include/postgresql/internal; -c -o pg_show_plans.o pg_show_plans.c gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -Wno-unused-command-line-argument -g -O2; -bundle -multiply_defined suppress -o pg_show_plans.so pg_show_plans.o -L/Users/hs/pg12/lib -Wl,-dead_strip_dylibs -bundle_loader /Users/hs/pg12/bin/postgres iMac:pg_show_plans hs$ make install /opt/local/bin/gmkdir -p '/Users/hs/pg12/lib/postgresql' /opt/local/bin/gmkdir -p '/Users/hs/pg12/share/postgresql/extension' /opt/local/bin/gmkdir -p '/Users/hs/pg12/share/postgresql/extension' /opt/local/bin/ginstall -c -m 755 pg_show_plans.so '/Users/hs/pg12/lib/postgresql/pg_show_plans.so' /opt/local/bin/ginstall -c -m 644 .//pg_show_plans.control '/Users/hs/pg12/share/postgresql/extension/' /opt/local/bin/ginstall -c -m 644 .//pg_show_plans--1.0.sql '/Users/hs/pg12/share/postgresql/extension/' |
If things work properly, the code is now successfully installed.
To activate the module, you have to set shared_preload_libraries in postgresql.conf:
|
1 2 3 4 5 |
test=# SHOW shared_preload_libraries; shared_preload_libraries ----------------------------------- pg_stat_statements, pg_show_plans (1 row) |
Once this is done, the extension can be activated in your database:
|
1 2 |
test=# CREATE EXTENSION pg_show_plans; CREATE EXTENSION |
To see how this module works we need two connections: In the first connection I will run a long SQL statement which selects data from a fairly complex system view. To make sure that the query takes forever I have added pg_sleep:
|
1 |
test=# SELECT *, pg_sleep(10000) FROM pg_stats; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
test=# x Expanded display is on. test=# SELECT * FROM pg_show_plans ; -[ RECORD 1 ]---------------------------------------------------------------------------------------------------- pid | 34871 level | 0 userid | 10 dbid | 26534 plan | Function Scan on pg_show_plans (cost=0.00..10.00 rows=1000 width=56) -[ RECORD 2 ]---------------------------------------------------------------------------------------------------- pid | 34881 level | 0 userid | 10 dbid | 26534 plan | Subquery Scan on pg_stats (cost=129.30..169.05 rows=5 width=405) + | -> Nested Loop Left Join (cost=129.30..168.99 rows=5 width=401) + | -> Hash Join (cost=129.17..167.68 rows=5 width=475) + | Hash Cond: ((s.starelid = c.oid) AND (s.staattnum = a.attnum)) + | -> Seq Scan on pg_statistic s (cost=0.00..34.23 rows=423 width=349) + | -> Hash (cost=114.40..114.40 rows=985 width=142) + | -> Hash Join (cost=23.05..114.40 rows=985 width=142) + | Hash Cond: (a.attrelid = c.oid) + | Join Filter: has_column_privilege(c.oid, a.attnum, 'select'::text) + | -> Seq Scan on pg_attribute a (cost=0.00..83.56 rows=2956 width=70) + | Filter: (NOT attisdropped) + | -> Hash (cost=18.02..18.02 rows=402 width=72) + | -> Seq Scan on pg_class c (cost=0.00..18.02 rows=402 width=72) + | Filter: ((NOT relrowsecurity) OR (NOT row_security_active(oid))) + | -> Index Scan using pg_namespace_oid_index on pg_namespace n (cost=0.13..0.18 rows=1 width=68)+ | Index Cond: (oid = c.relnamespace) |
pg_show_plans is going to return information for every database connection. Therefore it is possible to see everything at a glance and you can react even before a slow query has ended. As far as we know, pg_show_plans is the only module capable of providing you with this level of detail.
If you want to know more about execution plans we suggest checking out one of our other posts dealing with index scans, bitmap index scans and alike.
We are looking forward to seeing you on our blog soon for more interesting stuff.

Embedded SQL is by no means a new feature — in fact it is so old-fashioned that many people may not know about it at all. Still, it has lots of advantages for client code written in C. So I'd like to give a brief introduction and talk about its benefits and problems.
Typically you use a database from application code by calling the API functions or methods of a library. With embedded SQL, you put plain SQL code (decorated with “EXEC SQL”) smack in the middle of your program source. To turn that into correct syntax, you have to run a pre-processor on the code that converts the SQL statements into API function calls. Only then you can compile and run the program.
Embedded SQL is mostly used with old-fashioned compiled languages like C, Fortran, Pascal, PL/I or COBOL, but with SQLJ there is also a Java implementation. One reason for its wide adoption (at least in the past) is that it is specified by the SQL standard ISO/IEC 9075-2 (SQL/Foundation). This enables you to write fairly portable applications.
To be able to discuss the features in some more detail, I'll introduce a sample C program using embedded SQL.
The sample program operates on a database table defined like this:
|
1 2 3 4 |
CREATE TABLE atable( key integer PRIMARY KEY, value character varying(20) ); |
The program is in a file sample.pgc and looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
#include <stdlib.h> #include <stdio.h> /* error handlers for the whole program */ EXEC SQL WHENEVER SQLERROR CALL die(); EXEC SQL WHENEVER NOT FOUND DO BREAK; static void die(void) { /* avoid recursion on error */ EXEC SQL WHENEVER SQLERROR CONTINUE; fprintf( stderr, 'database error %s:n%sn', sqlca.sqlstate, sqlca.sqlerrm.sqlerrmc ); EXEC SQL ROLLBACK; EXEC SQL DISCONNECT; exit(1); /* restore the original handler */ EXEC SQL WHENEVER SQLERROR CALL die(); } int main(int argc, char **argv) { EXEC SQL BEGIN DECLARE SECTION; int v_key, v_val_ind; char v_val[81]; EXEC SQL END DECLARE SECTION; EXEC SQL DECLARE c CURSOR FOR SELECT key, value FROM atable ORDER BY key; /* connect to the database */ EXEC SQL CONNECT TO tcp:postgresql://localhost:5432/test?application_name=embedded USER laurenz; /* open a cursor */ EXEC SQL OPEN c; /* loop will be left if the cursor is done */ for(;;) { /* get the next result row */ EXEC SQL FETCH NEXT FROM c INTO :v_key, :v_val :v_val_ind; printf( 'key = %d, value = %sn', v_key, v_val_ind ? '(null)' : v_val ); } EXEC SQL CLOSE c; EXEC SQL COMMIT; EXEC SQL DISCONNECT; return 0; } |
Each SQL statement or declaration starts with the magic words EXEC SQL and ends with a semicolon.
Most statements are translated by the preprocessor right where they are.
|
1 2 3 |
EXEC SQL CONNECT TO tcp:postgresql://localhost:5432/test?application_name=embedded USER laurenz; |
There are several ways to specify a connect string to the database, and of course the value does not have to be hard-coded. You can also use CONNECT TO DEFAULT and use libpq environment variables and a password file to connect.
It is possible to open several database connections at once; then you have to name the connections. Connections are like global variables: they are available everywhere once opened, and you don't have to pass them to functions.
Special “host variables” exchange data between the program and the SQL statements.
They have to be declared in the declare section:
|
1 2 3 4 |
EXEC SQL BEGIN DECLARE SECTION; int v_key, v_val_ind; char v_val[81]; EXEC SQL END DECLARE SECTION; |
This is just like any other C variable declaration, but only these variables can be used in SQL statements. They have to be prepended with a colon (:) in SQL statements:
|
1 |
EXEC SQL FETCH NEXT FROM c INTO :v_key, :v_val :v_val_ind; |
The last variable, v_val_ind, is an indicator variable: it is set to a negative number to indicate a NULL value.
One advantage of embedded SQL is that the conversion between PostgreSQL data types and C data types is done automatically. With libpq, you can either get strings or the internal PostgreSQL representation. There is the additional (non-standard) libpgtypes library that provides convenient support for data types like timestamp or numeric.
Note that v_val was declared as char[81] so that it can contain any 20 UTF-8 characters. If you cannot predict the size of the result, you can use descriptor areas to exchange data.
If SQL statements cause an error or warning or return no data, you define the program behavior with WHENEVER declarations:
|
1 2 |
EXEC SQL WHENEVER SQLERROR CALL die(); EXEC SQL WHENEVER NOT FOUND DO BREAK; |
These slightly diverge from the SQL standard, which only has CONTINUE and GO TO label actions. Also, the standard uses SQLEXCEPTION instead of SQLERROR. The DO BREAK action inserts a break; statement to break out of the containing loop.
Different from other embedded SQL statements, these directives apply to all embedded SQL statements below them in the source file. They define how the pre-processor translates SQL statements and are independent of the control flow in the program.
To avoid recursion, it is best to set the action to CONTINUE (ignore) in the exception handler.
Note that this syntax allows to write code without adding error handling to every database call, which is convenient and makes the code concise and readable.
libpqSome advanced or PostgreSQL-specific features of libpq are not available in embedded SQL, for example the Large Object API or, more importantly, COPY.
To use these, you can call the function ECPGget_PGconn(const char *connection_name), which returns the underlying libpq connection object.
The pre-processor is called ecpg and part of the PostgreSQL core distribution. By default, ecpg assumes that source files have the extension .pgc.
To compile the resulting C program, you can use any C compiler, and you have to link with the libecpg library.
Here is a Makefile that can be used to build the sample program with PostgreSQL v12 on RedHat-like systems:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CFLAGS ::= $(CFLAGS) -I/usr/pgsql-12/include -g -Wall LDFLAGS ::= $(LDFLAGS) -L/usr/pgsql-12/lib -Wl,-rpath,/usr/pgsql-12/lib LDLIBS ::= $(LDLIBS) -lecpg PROGRAMS = sample .PHONY: all clean %.c: %.pgc ecpg $< all: $(PROGRAMS) clean: rm -f $(PROGRAMS) $(PROGRAMS:%=%.c) $(PROGRAMS:%=%.o) |
We have only scratched the surface, but I hope I could demonstrate that embedded SQL is a convenient way of writing database client code in C.
Here is a list of advantages and disadvantages of embedded SQL compared to directly using the C API of libpq:
Disadvantages:
libpq (e.g., no direct COPY support)Advantages:
Hello there, this is your developer speaking...
I'm struggling with how to start this post, since I've procrastinated a lot. There should be at least 5 published posts on this topic already. But there is only one by Hans-Jürgen Schönig. I'm thanking him for trying to cover my back, but the time has come!
Well, that's a tricky question. We've started working on pg_timetable a year ago, aiming our own targets. Then we've found out that this project might be interesting for other people and we opened it.
Soon we received some feedback from users and improved our product. There were no releases and versions at that time. But suddenly, we faced a situation where you cannot grow or fix anything vital, until you introduce changes in your database schema. Since we are not a proprietary project anymore, we must provide back-compatibility for current users.
Precisely at this time, you understand that there is a need for releases (versions) and database migrations to the new versions.
Major versions usually change the internal format of system tables and data representation. That's why we go for the new major version 2, considering the initial schema as version 1.
This means that, if you have a working installation of the pg_timetable, you will need to use --upgrade command-line option, but don't forget to make a backup beforehand.
So what are those dramatic changes?
How scheduling information was stored before:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE timetable.chain_execution_config ( ... run_at_minute INTEGER, run_at_hour INTEGER, run_at_day INTEGER, run_at_month INTEGER, run_at_day_of_week INTEGER, ... ); |
Turned out, it's incredibly inconvenient to store schedules one job per line because of the UI. Consider this simple cron syntax:
0 */6 * * * which stands for "every 6th hour".
So in the old model, it will produce 4 rows for hours 6, 12, 18, 24.
It's not a problem for the database itself to store and work with a large number of rows. However, now if a user wants to update the schedule, he/she either must update each entrance row by row or delete old rows and insert new ones.
So we've come out with the new syntax:
|
1 2 3 4 5 6 7 |
CREATE DOMAIN timetable.cron AS TEXT CHECK(...); CREATE TABLE timetable.chain_execution_config ( ... run_at timetable.cron, ... ); |
To be honest, these guys are the main reasons why we've changed the database schema. 🙂
If a job is marked as @reboot, it will be executed once after pg_timetable connects to the database or after connection reestablishment.
This kind of job is useful for initialization or for clean-up actions. Consider to remove leftovers from the unfinished tasks, e.g., delete downloaded or temporary files, clean tables, reinitialize schema, etc. One may rotate the log of the previous session, backup something, send logs by email.
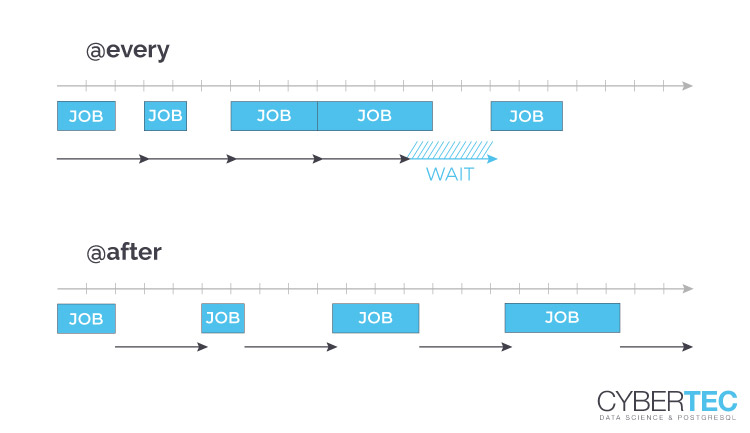
@every and @after are interval tasks, meaning they are not scheduled for a particular time but will be executed repeatedly. The syntax consists of the keyword (@every or @after) followed by proper interval type value.
The only difference is that @every task will be repeated within at equal intervals of time. In contrast, @after task will repeat itself in an interval only after the previous job was finished. See the figure below for details.
Here is the list of possible syntaxes:
|
1 2 3 4 5 6 7 8 9 |
SELECT '* * * * *' :: timetable.cron; SELECT '0 1 1 * 1' :: timetable.cron; SELECT '0 1 1 * 1,2,3' :: timetable.cron; SELECT '0 * * 0 1-4' :: timetable.cron; SELECT '0 * * * 2/4' :: timetable.cron; SELECT '*/2 */2 * * *' :: timetable.cron; SELECT '@reboot' :: timetable.cron; SELECT '@every 1 hour 30 sec' :: timetable.cron; SELECT '@after 30 sec' :: timetable.cron; |
We've added a startup option that forbids the execution of shell tasks. The reason is simple. If you are in a cloud deployment, you probably won't like shell tasks.
Ants Aasma, Cybertec expert:
Linux container infrastructure is basically taking a sieve and trying to make it watertight. It has a history of security holes. So unless you do something like KubeVirt, somebody is going to break out of the container.
Even with KubeVirt, you have to keep an eye out for things like Spectre that can break through the virtualization layer.
It's not the database we are worried about in this case. It's other people's databases running on the same infrastructure.
Starting on this release, we will provide you with pre-built binaries and packages. Currently, we build binaries:
We consider including our packages into official Yum and Apt PostgreSQL repositories.
And last but not least! Continuous testing was implemented using GitHub Actions, meaning all pull requests and commits are checked automatically to facilitate the development and integration of all kinds of contributors.
Cheers!
When designing a database application, the layout of data in disk is often neglected. However, the way data is clustered by PostgreSQL can have a major performance impact. Therefore it makes sense to take a look at what can be done to improve speed and throughput. In this post you will learn one of the most important tricks.
To demonstrate the importance of the on-disk layout I have created a simple test set:
|
1 2 3 4 5 6 7 |
test=# CREATE TABLE t_test AS SELECT * FROM generate_series(1, 10000000); SELECT 10000000 test=# CREATE TABLE t_random AS SELECT * FROM t_test ORDER BY random(); SELECT 10000000 |
Note that both data sets are absolutely identical. I have loaded 10 million rows into a simple table. However, in the first case data has been sorted, then inserted. generate_series returns data in ascending order and because the table is new data will be written to disk in that order.
In the second case I decided to shuffle the data before insertion. We are still talking about the same data set. However, it is not in the same order:
|
1 2 3 4 5 6 7 |
test=# d+ List of relations Schema | Name | Type | Owner | Size | Description --------+----------+-------+-------+--------+------------- public | t_random | table | hs | 346 MB | public | t_test | table | hs | 346 MB | (2 rows) |
In both cases the size on disk is the same. There are no changes in terms of space consumption which can be an important factor as well.
Let us create an index on both tables:
|
1 2 3 4 5 6 7 8 |
test=# timing Timing is on. test=# CREATE INDEX idx_test ON t_test (generate_series); CREATE INDEX Time: 3699.416 ms (00:03.699) test=# CREATE INDEX idx_random ON t_random (generate_series); CREATE INDEX Time: 5084.823 ms (00:05.085) |
Even creating the index is already faster on sorted data for various reasons. However, creating initial indexes does not happen too often, so you should not worry too much.
In the next step we can already create optimizer statistics and make sure that all hint bits are set to ensure a fair performance comparison:
|
1 2 |
test=# VACUUM ANALYZE; VACUUM |
Now that all the test data sets are in place we can run a simple test: Let us fetch 49000 rows from the sorted data set first:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# explain (analyze, buffers) SELECT * FROM t_test WHERE generate_series BETWEEN 1000 AND 50000; QUERY PLAN ------------------------------------------------------------------------------------- Index Only Scan using idx_test on t_test (cost=0.43..1362.62 rows=43909 width=4) (actual time=0.017..7.810 rows=49001 loops=1) Index Cond: ((generate_series >= 1000) AND (generate_series <= 50000)) Heap Fetches: 0 Buffers: shared hit=138 Planning Time: 0.149 ms Execution Time: 11.785 ms (6 rows) |
Not bad. We need 11.785 milliseconds to read the data. What is most important to consider here is that the number of 8k blocks needed is 138, which is not much. “shared hit” means that all the data has come from memory.
Let me run the same test again:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# explain (analyze, buffers) SELECT * FROM t_random WHERE generate_series BETWEEN 1000 AND 50000; QUERY PLAN ------------------------------------------------------------------------------------------ Index Only Scan using idx_random on t_random (cost=0.43..1665.17 rows=53637 width=4) (actual time=0.013..9.892 rows=49001 loops=1) Index Cond: ((generate_series >= 1000) AND (generate_series <= 50000)) Heap Fetches: 0 Buffers: shared hit=18799 Planning Time: 0.102 ms Execution Time: 13.386 ms (6 rows) |
In this case the query took a bit longer: 13.4 ms. However, let us talk about the most important number here: The number of blocks needed to return this result. 18799 blocks. Wow. That is roughly 150 times more.
One could argue that the query is not really that much slower. This is true. However, in my example all data is coming from memory. Let us assume for a moment that data has to be read from disk because for some reason we get no cache hits. The situation would change dramatically. Let us assume that reading one block from disk takes 0.1 ms:
138 * 0.1 + 11.7 = 25.5 ms
vs.
18799 * 0.1 + 13.4 = 1893.3 ms
That is a major difference. This is why the number of blocks does make a difference – even if it might not appear to be the case at first glance. The lower your cache hit rates are, the bigger the problem will become.
There is one more aspect to consider in this example: Note that if you want to read a handful of rows only the on-disk layout does not make too much of a difference. However, if the subset of data contains thousands of rows, the way is ordered on disk does have an impact on performance.
The CLUSTER command has been introduced many years ago to address exactly the issues I have just outlined. It allows you to organize data according to an index. Here is the syntax:
|
1 2 3 4 5 6 |
test=# h CLUSTER Command: CLUSTER Description: cluster a table according to an index Syntax: CLUSTER [VERBOSE] table_name [ USING index_name ] CLUSTER [VERBOSE] |
URL: https://www.postgresql.org/docs/12/sql-cluster.html
Utilizing the CLUSTER command is easy. The following code snipped will show how you can do that:
|
1 2 |
test=# CLUSTER t_random USING idx_random; CLUSTER |
To see what happens I have executed the same query as before again. However, there is something important to be seen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
test=# explain (analyze, buffers) SELECT * FROM t_random WHERE generate_series BETWEEN 1000 AND 50000; QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on t_random (cost=1142.21..48491.32 rows=53637 width=4) (actual time=3.328..9.564 rows=49001 loops=1) Recheck Cond: ((generate_series >= 1000) AND (generate_series <= 50000)) Heap Blocks: exact=218 Buffers: shared hit=2 read=353 -> Bitmap Index Scan on idx_random (cost=0.00..1128.80 rows=53637 width=0) (actual time=3.284..3.284 rows=49001 loops=1) Index Cond: ((generate_series >= 1000) AND (generate_series <= 50000)) Buffers: shared hit=2 read=135 Planning Time: 1.024 ms Execution Time: 13.077 ms (9 rows) |
PostgreSQL has changed the execution plan. This happens due to wrong statistics. Therefore it is important to run ANALYZE to make sure that the optimizer has up-to date information:
|
1 2 |
test=# ANALYZE; ANALYZE |
Once the new optimizer statistics is in place the execution plan will be as expected again:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# explain (analyze, buffers) SELECT * FROM t_random WHERE generate_series BETWEEN 1000 AND 50000; QUERY PLAN ----------------------------------------------------------------------------------------- Index Only Scan using idx_random on t_random (cost=0.43..1807.12 rows=50884 width=4) (actual time=0.012..11.737 rows=49001 loops=1) Index Cond: ((generate_series >= 1000) AND (generate_series <= 50000)) Heap Fetches: 49001 Buffers: shared hit=355 Planning Time: 0.220 ms Execution Time: 15.267 ms (6 rows) |
If you have decided to cluster a table it does NOT mean that order on disk is maintained forever. If you run UPDATES etc. frequently the table might gradually loose order again. Therefore, CLUSTER is especially useful if your data is rather static. It can also make sense to order data as you import it to ensure physical order.
If you want to learn more about database performance and storage consider checking out my post about shrinking the storage footprint of PostgreSQL.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
(Last updated on 2023-01-24) Recently, while troubleshooting PostgreSQL performance problems, I ran into problems with subtransactions twice. So I thought this was a nice topic for another blog post.
Everybody knows database transactions. In PostgreSQL, which is operating in autocommit mode, you have to start a transaction that spans multiple statements explicitly with BEGIN or START TRANSACTION and close it with END or COMMIT. If you abort the transaction with ROLLBACK (or end the database session without committing) all work done inside the transaction becomes undone.
Now subtransactions allow you to roll back part of the work done in a transaction. You start a subtransaction inside a transaction with the standard SQL statement:
|
1 |
SAVEPOINT name; |
“name” is an identifier (no single quotes!) for the subtransaction. You cannot commit a subtransaction in SQL (it is automatically committed with the transaction that contains it), but you can roll it back with:
|
1 |
ROLLBACK TO SAVEPOINT name; |
Subtransactions are useful in longer transactions. In PostgreSQL, any error inside a transaction will abort the transaction:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
test=> BEGIN; BEGIN test=*> SELECT 'Some work is done'; ?column? ------------------- Some work is done (1 row) test=*> SELECT 12 / (factorial(0) - 1); ERROR: division by zero test=!> SELECT 'try to do more work'; ERROR: current transaction is aborted, commands ignored until end of transaction block test=!> COMMIT; ROLLBACK |
With a transaction that does a lot of work this is quite annoying, because it means that all work done so far is lost. Subtransactions can help you recover from such a situation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=> BEGIN; BEGIN test=*> SELECT 'Some work is done'; ?column? ------------------- Some work is done (1 row) test=*> SAVEPOINT a; SAVEPOINT test=*> SELECT 12 / (factorial(0) - 1); ERROR: division by zero test=!> ROLLBACK TO SAVEPOINT a; ROLLBACK test=*> SELECT 'try to do more work'; ?column? --------------------- try to do more work (1 row) test=*> COMMIT; COMMIT |
Note that ROLLBACK TO SAVEPOINT starts another subtransaction called a when it rolls back the old one.
Even if you have never used the SAVEPOINT statement, you may already have encountered subtransactions. Written in PL/pgSQL, the code in the previous section looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BEGIN PERFORM 'Some work is done'; BEGIN -- a block inside a block PERFORM 12 / (factorial(0) - 1); EXCEPTION WHEN division_by_zero THEN NULL; -- ignore the error END; PERFORM 'try to do more work'; END; |
Every time you enter a block with an EXCEPTION clause, a new subtransaction is started. The subtransaction is committed when you leave the block, and rolled back when you enter the exception handler.
Many other databases handle errors inside a transaction differently. Rather than aborting the complete transaction, they roll back only the statement that caused the error, leaving the transaction itself active.
When migrating or porting from such a database to PostgreSQL, you might be tempted to wrap every single statement in a subtransaction to emulate the above behavior.
The PostgreSQL JDBC driver even has a connection parameter “autosave” that you can set to “always” to automatically set a savepoint before each statement and rollback in case of failure.
As the following will show, this alluring technique will lead to serious performance problems.
To demonstrate the problems caused by overuse of subtransactions, I created a test table:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE UNLOGGED TABLE contend ( id integer PRIMARY KEY, val integer NOT NULL ) WITH (fillfactor='50'); INSERT INTO contend (id, val) SELECT i, 0 FROM generate_series(1, 10000) AS i; VACUUM (ANALYZE) contend; |
The table is small, unlogged and has a low fillfactor to reduce the required I/O as much as possible. This way, I can observe the effects of subtransactions better.
I'll use pgbench, the benchmarking tool shipped with PostgreSQL, to run the following custom SQL script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
BEGIN; PREPARE sel(integer) AS SELECT count(*) FROM contend WHERE id BETWEEN $1 AND $1 + 100; PREPARE upd(integer) AS UPDATE contend SET val = val + 1 WHERE id IN ($1, $1 + 10, $1 + 20, $1 + 30); SAVEPOINT a; set rnd random(1,990) EXECUTE sel(10 * :rnd + :client_id + 1); EXECUTE upd(10 * :rnd + :client_id); SAVEPOINT a; set rnd random(1,990) EXECUTE sel(10 * :rnd + :client_id + 1); EXECUTE upd(10 * :rnd + :client_id); ... SAVEPOINT a; set rnd random(1,990) EXECUTE sel(10 * :rnd + :client_id + 1); EXECUTE upd(10 * :rnd + :client_id); DEALLOCATE ALL; COMMIT; |
The script will set 60 savepoints for test number 1, and 90 for test number 2. It uses prepared statements to minimize the overhead of query parsing.
pgbench will replace :client_id with a number unique to the database session. So as long as there are no more than 10 clients, each client's UPDATEs won't collide with those of other clients, but they will SELECT each other's rows.
Since my machine has 8 cores, I'll run the tests with 6 concurrent clients for ten minutes.
To see meaningful information with “perf top”, you need the PostgreSQL debugging symbols installed. This is particularly recommended on production systems.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
pgbench -f subtrans.sql -n -c 6 -T 600 transaction type: subtrans.sql scaling factor: 1 query mode: simple number of clients: 6 number of threads: 1 duration: 600 s number of transactions actually processed: 100434 latency average = 35.846 ms tps = 167.382164 (including connections establishing) tps = 167.383187 (excluding connections establishing) |
This is what “perf top --no-children --call-graph=fp --dsos=/usr/pgsql-12/bin/postgres” shows while the test is running:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
+ 1.86% [.] tbm_iterate + 1.77% [.] hash_search_with_hash_value 1.75% [.] AllocSetAlloc + 1.36% [.] pg_qsort + 1.12% [.] base_yyparse + 1.10% [.] TransactionIdIsCurrentTransactionId + 0.96% [.] heap_hot_search_buffer + 0.96% [.] LWLockAttemptLock + 0.85% [.] HeapTupleSatisfiesVisibility + 0.82% [.] heap_page_prune + 0.81% [.] ExecInterpExpr + 0.80% [.] SearchCatCache1 + 0.79% [.] BitmapHeapNext + 0.64% [.] LWLockRelease + 0.62% [.] MemoryContextAllocZeroAligned + 0.55% [.] _bt_checkkeys 0.54% [.] hash_any + 0.52% [.] _bt_compare 0.51% [.] ExecScan |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
pgbench -f subtrans.sql -n -c 6 -T 600 transaction type: subtrans.sql scaling factor: 1 query mode: simple number of clients: 6 number of threads: 1 duration: 600 s number of transactions actually processed: 41400 latency average = 86.965 ms tps = 68.993634 (including connections establishing) tps = 68.993993 (excluding connections establishing) |
This is what “perf top --no-children --call-graph=fp --dsos=/usr/pgsql-12/bin/postgres” has to say:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
+ 10.59% [.] LWLockAttemptLock + 7.12% [.] LWLockRelease + 2.70% [.] LWLockAcquire + 2.40% [.] SimpleLruReadPage_ReadOnly + 1.30% [.] TransactionIdIsCurrentTransactionId + 1.26% [.] tbm_iterate + 1.22% [.] hash_search_with_hash_value + 1.08% [.] AllocSetAlloc + 0.77% [.] heap_hot_search_buffer + 0.72% [.] pg_qsort + 0.72% [.] base_yyparse + 0.66% [.] SubTransGetParent + 0.62% [.] HeapTupleSatisfiesVisibility + 0.54% [.] ExecInterpExpr + 0.51% [.] SearchCatCache1 |
Even if we take into account that the transactions in test 2 are one longer, this is still a performance regression of 60% compared with test 1.
To understand what is going on, we have to understand how transactions and subtransactions are implemented.
Whenever a transaction or subtransaction modifies data, it is assigned a transaction ID. PostgreSQL keeps track of these transaction IDs in the commit log, which is persisted in the pg_xact subdirectory of the data directory.
However, there are some differences between transactions and subtransactions:
The information which (sub)transaction is the parent of a given subtransaction is persisted in the pg_subtrans subdirectory of the data directory. Since this information becomes obsolete as soon as the containing transaction has ended, this data do not have to be preserved across a shutdown or crash.
The visibility of a row version (“tuple”) in PostgreSQL is determined by the xmin and xmax system columns, which contain the transaction ID of the creating and destroying transactions. If the transaction ID stored is that of a subtransaction, PostgreSQL also has to consult the state of the containing (sub)transaction to determine if the transaction ID is valid or not.
To determine which tuples a statement can see, PostgreSQL takes a snapshot of the database at the beginning of the statement (or the transaction). Such a snapshot consists of:
A snapshot is initialized by looking at the process array, which is stored in shared memory and contains information about all currently running backends. This, of course, contains the current transaction ID of the backend and has room for at most 64 non-aborted subtransactions per session. If there are more than 64 such subtransactions, the snapshot is marked as suboverflowed.
A suboverflowed snapshot does not contain all data required to determine visibility, so PostgreSQL will occasionally have to resort to pg_subtrans. These pages are cached in shared buffers, but you can see the overhead of looking them up in the high rank of SimpleLruReadPage_ReadOnly in the perf output. Other transactions have to update pg_subtrans to register subtransactions, and you can see in the perf output how they vie for lightweight locks with the readers.
Apart from looking at “perf top”, there are other symptoms that point at the direction of this problem:
SubtransSLRU” (“SubtransControlLock” in older releases) in pg_stat_activitypg_stat_slru and check if blks_read in the row with name = 'Subtrans' keeps growing. That indicates that PostgreSQL has to read disk pages because it needs to access subtransactions that are no longer cached.pg_export_snapshot()” function, the resulting file in the pg_snapshots subdirectory of the data directory will contain the line “sof:1” to indicate that the subtransaction array overflowedpg_stat_get_backend_subxact(integer) to return the number of subtransactions for a backend process and whether the subtransaction cache overflowed or notSubtransactions are a great tool, but you should use them wisely. If you need concurrency, don't start more than 64 subtransactions per transaction.
The diagnostics shown in this article should help you determine whether you are suffering from the problem, or not.
Finding the cause of that problem can be tricky. For example, it may not be obvious that a function with an exception handler that you call for each result row of an SQL statement (perhaps in a trigger) starts a new subtransaction.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
If you are running PostgreSQL in production you might have already noticed that adjusting checkpoints can be a very beneficial thing to tune the server and to improve database performance overall. However, there is more to this: Increasing checkpoint distances can also help to actually reduce the amount of WAL that is created in the first place. That is right. It is not just a performance issue, but it also has an impact on the volume of log created.
You want to know why? Let us take a closer look!
For my test I am using a normal PostgreSQL 12 installation. To do that I am running initdb by hand:
|
1 |
% initdb -D /some_where/db12 restart |
Then I have adjusted two parameters in postgresql.conf:
|
1 2 |
max_wal_size = 128MB synchronous_commit = off |
and restarted the server:
|
1 |
% pg_ctl -D /some_where/db12 restart |
First of all I have reduced max_wal_size to make sure that PostgreSQL checkpoint a lot more often than this would be the case in the default installation. Performance will drop like a stone. The second parameter is to tell PostgreSQL to use asynchronous commits. This does not impact WAL generation but will simply speed up the benchmark to get results faster.
Finally I am using pgbench to create a test database containing 10 million rows (= 100 x 100.000)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
% createdb test % pgbench -s 100 -i test dropping old tables... NOTICE: table 'pgbench_accounts' does not exist, skipping NOTICE: table 'pgbench_branches' does not exist, skipping NOTICE: table 'pgbench_history' does not exist, skipping NOTICE: table 'pgbench_tellers' does not exist, skipping creating tables... generating data... 100000 of 10000000 tuples (1%) done (elapsed 0.13 s, remaining 12.90 s) 200000 of 10000000 tuples (2%) done (elapsed 0.28 s, remaining 13.79 s) … 9700000 of 10000000 tuples (97%) done (elapsed 12.32 s, remaining 0.38 s) 9800000 of 10000000 tuples (98%) done (elapsed 12.46 s, remaining 0.25 s) 9900000 of 10000000 tuples (99%) done (elapsed 12.59 s, remaining 0.13 s) 10000000 of 10000000 tuples (100%) done (elapsed 12.68 s, remaining 0.00 s) vacuuming... creating primary keys... done. |
Let us run a test now: We want to run 10 x 1 million transactions. If you want to repeat the tests on your database make sure the test runs long enough. Let us take a look at the test!
|
1 2 3 4 5 6 7 8 9 10 11 12 |
% pgbench -c 10 -j 5 -t 1000000 test starting vacuum...end. transaction type: scaling factor: 100 query mode: simple number of clients: 10 number of threads: 5 number of transactions per client: 1000000 number of transactions actually processed: 10000000/10000000 latency average = 0.730 ms tps = 13699.655677 (including connections establishing) tps = 13699.737288 (excluding connections establishing) |
As you can see we managed to run roughly 13.700 transactions per second (on my personal laptop). Let us take a look at the amount of WAL created:
|
1 2 3 4 5 |
test=# SELECT pg_current_wal_insert_lsn(); pg_current_wal_insert_lsn --------------------------- 13/522921E8 (1 row) |
The way to figure out the current WAL position is to call the pg_current_insert_lsn() function. To most people this format might be incomprehensible and therefore it is easier to transform the value into a readable number:
|
1 2 3 4 5 |
test=# SELECT pg_current_wal_insert_lsn() - '0/00000000'::pg_lsn; ?column? ------------- 82982805992 (1 row) |
The pg_size_pretty() function will return the number in a readily understandable format:
|
1 2 3 4 5 |
test=# SELECT pg_size_pretty(pg_current_wal_insert_lsn() - '0/00000000'::pg_lsn); pg_size_pretty ---------------- 77 GB (1 row) |
Let us stop the database, delete the data directory and initialize it again. This time my postgresql.conf parameters will be set to way higher values:
|
1 2 3 |
max_wal_size = 150GB checkpoint_timeout = 1d synchronous_commit = off |
Then we start the database again, populate it with data and run pgbench with the exact same parameters. Keep in mind that to repeat the process it is necessary to run a fixed number of transactions instead of running the test for a certain time. This way we can fairly compare the amount of WAL created.
Let us take a look and see how much WAL has been created this time:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SELECT pg_current_wal_insert_lsn(); pg_current_wal_insert_lsn --------------------------- 1/4F210328 (1 row) test=# SELECT pg_size_pretty(pg_current_wal_insert_lsn() - '0/00000000'::pg_lsn); pg_size_pretty ---------------- 5362 MB (1 row) |
Wow, only 5.3 GB of WAL. This is a major improvement but why did it happen?
The idea of the transaction log is to make sure that in case of a crash the system will be able to recover nicely. However, PostgreSQL cannot keep the transaction log around forever. The purpose of a checkpoint is ensuring that all data is safe in the data file before the WAL can be removed from disk.
Here comes the trick: If a block is modified after a checkpoint for the first time it has to be logged completely. The entire block will be written to the WAL. Every additional change does not require the entire block to be written – only the changes have to be logged which is, of course, a lot less.
This is the reason for the major difference we see here. By increasing the checkpoint distances to a really high value, we basically reduced checkpoints to an absolute minimum which in turn reduces the number of “first blocks” written.
Changing WAL settings is not just good for performance in the long run – it will also reduce the volume of WAL.
If you want to know more about PostgreSQL and want to learn something about VACUUM check out my blog about this important topic.
Also, if you like our posts you might want to share them on LinkedIn or on Facebook. We are looking forward to your comments.