PostgreSQL replication (synchronous and asynchronous replication) is one of the most widespread features in the database community. Nowadays, people are building high-availability clusters or use replication to create read-only replicas to spread out the workload. What is important to note here is that if you are using replication, you must make sure that your clusters are properly monitored.
The purpose of this post is to explain some of the fundamentals, to make sure that your PostgreSQL clusters stay healthy.
The best way to monitor replication is to use pg_stat_replication, which contains a lot of vital information. Here is what the view looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
test=# \d pg_stat_replication View 'pg_catalog.pg_stat_replication' Column | Type | Collation | Nullable | Default -----------------+-------------------------+-----------+----------+--------- pid | integer | | | usesysid | oid | | | usename | name | | | application_name | text | | | client_addr | inet | | | client_hostname | text | | | client_port | integer | | | backend_start | timestamp with time zone| | | backend_xmin | xid | | | state | text | | | sent_lsn | pg_lsn | | | write_lsn | pg_lsn | | | flush_lsn | pg_lsn | | | replay_lsn | pg_lsn | | | write_lag | interval | | | flush_lag | interval | | | replay_lag | interval | | | sync_priority | integer | | | sync_state | text | | | reply_time | timestamp with time zone| | | |
The number of columns in this view has grown substantially over the years. However, let’s discuss some fundamentals first.
People often say that pg_stat_replication is on the “primary”. That’s not quite true. What the view does is to expose information about the wal_sender process. In other words: if you are running cascaded replication, it means that a secondary might also show entries in case it replicates to further slaves. Here is an image illustrating the situation:
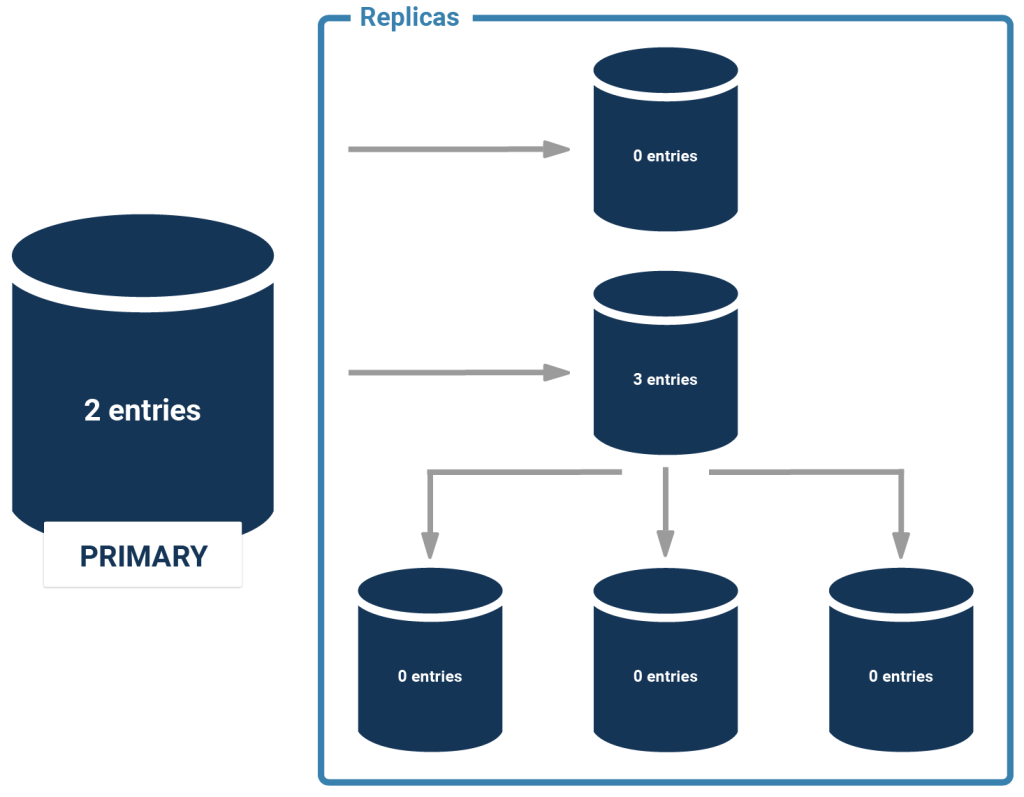
For every WAL sender process you will get exactly one entry. What is important is that each server is only going to see the next ones in the chain - a sending server is never going to see “through” a slave. In other words: In the case of cascading replication, you have to ask every sending server to get an overview.
But there’s more: often people have to determine if a slave is up to date or not. There are various things which are relevant here:
The following picture illustrates those fields:
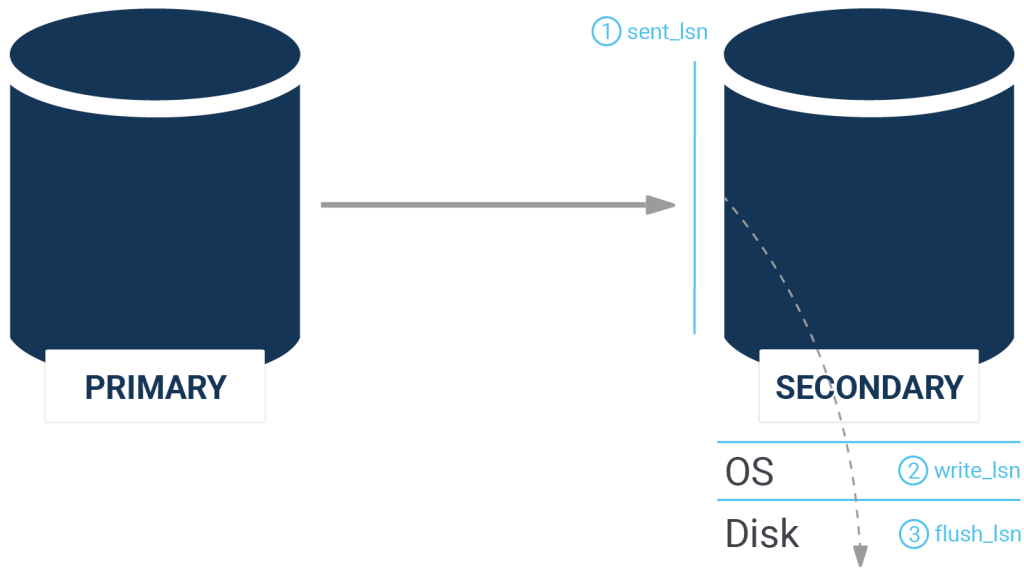
What’s important to note here is that PostgreSQL offers a special data type to represent this data: pg_lsn
One can figure out the current WAL position easily. Here is how it works:
|
1 2 3 4 5 |
test=# SELECT pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 3/DA06D240 (1 row) |
What’s noteworthy here is that it’s possible to make calculations:
|
1 2 3 4 5 |
test=# SELECT pg_current_wal_lsn() - '3/B549A845'::pg_lsn; ?column? ----------- 616376827 (1 row) |
PostgreSQL provides various operators to do such calculations. In other words: it’s easy to figure out how far a replica has fallen behind.
People keep asking us what the difference between the flush_lsn and the replay_lsn might be. Well, let’s dig in and find out: when WAL is flowing from the master to the slave, it is first sent over the network, then sent to the operating system and finally transactions are flushed to disk to assure durability (= crash safety). The flush_lsn obviously represents the last WAL position flushed to disk. The question now is: is data visible as soon as it is flushed? The answer is: no, there might be replication conflicts as described in one of our older blog posts. In case of a replication conflict, the WAL is persisted on the replica - but it is only replayed when the conflict is resolved. In other words, it might happen that data is stored on the slave which is not yet replayed and thus accessible by end users.
This is important to note, because replication conflicts occur more often than you might think. If you see a message as follows, you have hit a replication conflict:
|
1 2 |
ERROR: canceling statement due to conflict with recovery DETAIL: User query might have needed to see row versions that must be removed. |
Sometimes it’s necessary to determine the amount of replication lag in seconds. So far, we have seen the distance between two servers in bytes. If you want to measure the lag, you can take a look at the _lag columns. The data type of those columns is “interval” so you can see what the delay is in seconds or even minutes. If replication is working properly, the lag is usually very very small (milliseconds). However, you might want to monitor that.
A word of caution: if you are running large scale imports such as VACUUM or some other expensive operations, it might easily happen that the disk throughput is higher than the network bandwidth. In this case, it is possible and quite likely that the slave falls behind. You have to tolerate that and make sure that alerting does not kick in too early.
To monitor replication, you can rely on the manual magic I have just shown. However, there is also a lot of ready-made tooling out there to facilitate this task. One of the things we can recommend is pgwatch2, which can be downloaded for free as a container.
If you want to check out a demo showing how pgwatch works, consider checking out our pgwatch2 website.
If you want to learn more about PostgreSQL in general we recommend to check out some of our other posts. In case you are interested in storage you may want to take a look at one of our posts about pgsqueeze.
by Kaarel Moppel
So, you’re building the next unicorn startup and are thinking feverishly about a future-proof PostgreSQL architecture to house your bytes? My advice here, having seen dozens of hopelessly over-engineered / oversized solutions as a database consultant over the last 5 years, is short and blunt: Don’t overthink, and keep it simple on the database side! Instead of getting fancy with the database, focus on your application. Turn your microscope to the database only when the need actually arises, m'kay! When that day comes, first of all, try all the common vertical scale-up approaches and tricks. Try to avoid using derivative Postgres products, or employing distributed approaches, or home-brewed sharding at all costs - until you have, say, less than 1 year of breathing room available.
Wow, what kind of advice is that for 2021? I’m talking about a simple, single-node approach in the age of Big Data and hyper-scalability...I surely must be a Luddite or just still dizzy from too much New Year’s Eve champagne. Well, perhaps so, but let’s start from a bit further back...
Over the holidays, I finally had a bit of time to catch up on my tech reading / watching TODO-list (still dozens of items left though, arghh)...and one pretty good talk was on the past and current state of distributed MySQL architectures by Peter Zaitsev of Percona. Oh, MySQL??? No no, we haven’t changed “horses” suddenly, PostgreSQL is still our main focus 🙂 It’s just that in many key points pertaining to scaling, the same constraints actually also apply to PostgreSQL. After all, they’re both designed as single-node relational database management engines.
In short, I’m summarizing some ideas out of the talk, plus adding some of my own. I would like to provide some food for thought to those who are overly worried about database performance - thus prematurely latching onto some overly complex architectures. In doing so, the “worriers” sacrifice some other good properties of single-node databases - like usability, and being bullet-proof.
If you’re new to this realm, just trust me on the above, OK? There’s a bunch of abandoned or stale projects which have tried to offer some fully or semi-automatically scalable, highly available, easy-to-use and easy-to-manage DBMS...and failed! It’s not an utterly bad thing to try though, since we can learn from it. Actually, some products are getting pretty close to the Holy Grail of distributed SQL databases (CockroachDB comes to mind first). However, I’m afraid we still have to live with the CAP theorem. Also, remember that to go from covering 99.9% of corner cases of complex architectures to covering 99.99% is not a matter of linear complexity/cost, but rather exponential complexity/cost!
Although after a certain amount of time a company like Facebook surely needs some kind of horizontal scaling, maybe you’re not there yet, and maybe stock Postgres can still provide you some years of stress-free cohabitation. Consider: Do you even have a runway for that long?
On my average workstation, I can achieve around 25k simple read transactions per CPU core on an "in memory" pgbench dataset using the default Postgres v13 configuration. After tuning, this increased to ~32k TPS per core, allowing a high-end server to handle about 1 million short reads. Replicas can further multiply this by 10, though query routing needs to be managed, potentially using the new LibPQ connection string syntax (targetsessionattrs). Postgres doesn't limit replicas, and with cascading, you could likely run dozens without significant issues.
On my humble workstation with 6 cores (12 logical CPUs) and NVMe SSD storage, the default very write-heavy (3 UPD, 1 INS, 1 SEL) “pgbench” test greets me with a number of around 45k TPS - for example, after some checkpoint tuning - and there are even more tuning tricks available.
Given that you have separated “hot” and “cold” data sets, and there’s some thought put into indexing, etc., a single Postgres instance can cope with quite a lot of data. Backups and standby server provisioning, etc. will be a pain, since you’ll surely meet some physical limits even on the finest hardware. However, these issues are common to all database systems. From the query performance side, there is no reason why it should suddenly be forced to slow down!
Given that 1) you declare your constraints correctly, 2) don’t fool around with some “fsync” or asynchronous commit settings, and 3) your disks don’t explode, a single node instance provides rock-solid data consistency. Again, the last item applies to any data storage, so hopefully, you have “some” backups somewhere...
Meaning: that even if something very bad happens and the primary node is down, the worst outcome is that your application is just currently unavailable. Once you do your recovery magic (or better, let some bot like Patroni take care of that) you’re exactly where you were previously. Now compare that with some partial failure scenarios or data hashing errors in a distributed world! Believe me, when working with critical data, in a lot of cases it’s better to have a short downtime than to have to sort out some runaway datasets for days or weeks to come, which is confusing for yourself and your customers.
In the beginning of the post, I said that when starting out, you shouldn’t worry too much about scaling from the architectural side. That doesn’t mean that you should ignore some common best practices, in case scaling could theoretically be required later. Some of them might be:
This might be the most important thing on the list - with modern real hardware (or some metal cloud instances) and the full power of config and filesystem tuning and extensions, you’ll typically do just fine on a single node for years. Remember that if you get tired of running your own setup, nowadays you can always migrate to some cloud providers - with minimal downtime - via Logical Replication! If you want to know how, see here. Note that I specifically mentioned “real” hardware above, due to the common misconception that a single cloud vCPU is pretty much equal to a real one...the reality is far from that of course - my own impression over the years has been that there is around a 2-3x performance difference, depending on the provider/region/luck factor in question.
You’d be surprised how often we see that...so slice and dice early, or set up some partitioning. Partitioning will also do a lot of good to the long-term health of the database, since it allows multiple autovacuum workers on the same logical table, and it can speed up IO considerably on enterprise storage. If IO indeed becomes a bottleneck at some point, you can employ Postgres native remote partitions, so that some older data lives on another node.
Initially, the data can just reside on a single physical node. If your data model revolves around the “millions of independent clients” concept for example, then it might even be best to start with many “sharded” databases with identical schemas, so that transferring out the shards to separate hardware nodes will be a piece of cake in the future.
There are benefits to systems that can scale 1000x from day one...but in many cases, there’s also an unreasonable (and costly) desire to be ready for scaling. I get it, it’s very human - I’m also tempted to buy a nice BMW convertible with a maximum speed of 250 kilometers per hour...only to discover that the maximum allowed speed in my country is 110, and even that during the summer months.
The thing that resonated with me from the Youtube talk the most was that there’s a definite downside to such theoretical scaling capability - it throttles development velocity and operational management efficiency at early stages! Having a plain rock-solid database that you know well, and which also actually performs well - if you know how to use it - is most often a great place to start with.
By the way, here’s another good link on a similar note from a nice Github collection and also one pretty detailed overview here about how an Alexa top 250 company managed to get by with a single database for 12 years before needing drastic scaling action!
To sum it all up: this is probably a good place to quote the classics: premature optimization is the root of all evil…
As CYBERTEC keeps expanding, we need a lot more office space than we previously did. Right now, we have a solution in the works: a new office building. We wanted something beautiful, so we started to dig into mathematical proportions to achieve a reasonable level of beauty. We hoped to make the building not just usable, but also to have it liked by our staff.
I stumbled upon some old books about proportions in architecture and went to work. Fortunately, one can use PostgreSQL to do some of the more basic calculations needed.
This is of course a post about PostgreSQL, and not about architecture-- but let me explain a very basic concept: golden proportions. Beauty is not random; it tends to follow some mathematical rules. The same is true in music. “Golden proportions” are a common concept: Let’s take a look:
|
1 2 3 4 5 6 7 |
test=# SELECT 1.618 AS constant, round(1 / 1.618, 4) AS inverted, round(pow(1.618, 2), 4) AS squared; constant | inverted | squared ----------+----------+--------- 1.618 | 0.6180 | 2.6179 (1 row) |
We are looking at a magic number here: 1.618. It has some nice attributes. If we invert it is basically “magic number - 1”. If we square it, what we get is “magic number + 1”. If we take a line and break it up into two segments we can use 1 : 1.618. Humans will tend to find this more beautiful than splitting the line using 1 : 1.8976 or so.
Naturally we can make use of this wisdom to create a basic rectangle:
In the case of our new building, we decided to use the following size:
|
1 2 3 4 5 |
test=# SELECT 16.07, 16.07 * 1.618; ?column? | ?column? ----------+---------- 16.07 | 26.00126 (1 row) |
The basic layout is 16 x 26 meters. It matches all mathematical proportions required in the basic layout.
To make the building look more appealing, we decided to add a small semi-circle to the rectangle. The question is: What is the ideal diameter of the semi-circle? We can use the same formula as before:
|
1 2 3 4 5 6 7 |
test=# WITH semi_circle AS (SELECT 16.07 * 0.618 AS size) SELECT size, size / 2 FROM semi_circle; size | ?column? ---------+-------------------- 9.93126 | 4.9656300000000000 (1 row) |
I have used a CTE (common table expression) here. PostgreSQL 13 has a nice feature to handle those expressions. Let’s take a look at the execution plan:
|
1 2 3 4 5 6 7 |
test=# explain WITH semi_circle AS (SELECT 16.07 * 0.618 AS size) SELECT size, size / 2 FROM semi_circle; QUERY PLAN ------------------------------------------- Result (cost=0.00..0.01 rows=1 width=64) (1 row) |
The optimizer has inlined the expression. What we get is:
|
1 |
SELECT 16.07 * 0.618, SELECT 16.07 * 0.618 / 2 |
Then, the optimizer does “constant” folding. All that is left in the execution plan is a “result” node which just displays the answer. The CTE has been removed from the plan entirely.
To make sure the front of the building is not too boring, we need to figure out which numbers are “allowed” and which ones are not. The way to do that is to use recursion:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
test=# WITH RECURSIVE x AS ( SELECT 26::numeric AS base, 26*0.382::numeric AS short, 26*0.618::numeric AS long UNION ALL SELECT round((base * 0.618)::numeric, 4), round((long * 0.382)::numeric, 4), round((long * 0.618)::numeric, 4) FROM x WHERE base > 0.5 ) SELECT * FROM x WHERE base > 0.5; base | short | long ---------+--------+-------- 26 | 9.932 | 16.068 16.0680 | 6.1380 | 9.9300 9.9300 | 3.7933 | 6.1367 6.1367 | 2.3442 | 3.7925 3.7925 | 1.4487 | 2.3438 2.3438 | 0.8953 | 1.4485 1.4485 | 0.5533 | 0.8952 0.8952 | 0.3420 | 0.5532 0.5532 | 0.2113 | 0.3419 (9 rows) |
The idea is to make sure that all components are related to all other components. What we do here is start with 26 meters and calculate the “long” and the “short sides”. Then we use this input for the next iteration, so that we can get a series of valid numbers which guarantee that things fit perfectly. Fortunately, PostgreSQL can do recursion in a nice, ANSI-compatible way. Inside the WITH the first SELECT will assign the start values of the recursion. Then the second part after the UNION ALL will call the recursion which is terminated by the WHERE-clause. At the end of the day, we get a sequence of mathematically correct numbers.
However, once in a while you want to see which iteration a line belongs to. Here is how this can be achieved:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
test=# WITH RECURSIVE x AS ( SELECT 26::numeric AS base, 26*0.382::numeric AS short, 26*0.618::numeric AS long UNION ALL SELECT round((base * 0.618)::numeric, 4), round((long * 0.382)::numeric, 4), round((long * 0.618)::numeric, 4) FROM x WHERE base > 0.5 ) SELECT row_number() OVER (), * FROM x WHERE base > 0.5; row_number | base | short | long ------------+---------+--------+-------- 1 | 26 | 9.932 | 16.068 2 | 16.0680 | 6.1380 | 9.9300 3 | 9.9300 | 3.7933 | 6.1367 4 | 6.1367 | 2.3442 | 3.7925 5 | 3.7925 | 1.4487 | 2.3438 6 | 2.3438 | 0.8953 | 1.4485 7 | 1.4485 | 0.5533 | 0.8952 8 | 0.8952 | 0.3420 | 0.5532 9 | 0.5532 | 0.2113 | 0.3419 (9 rows) |
row_number() is a function returning a simple number indicating the line we are looking at.
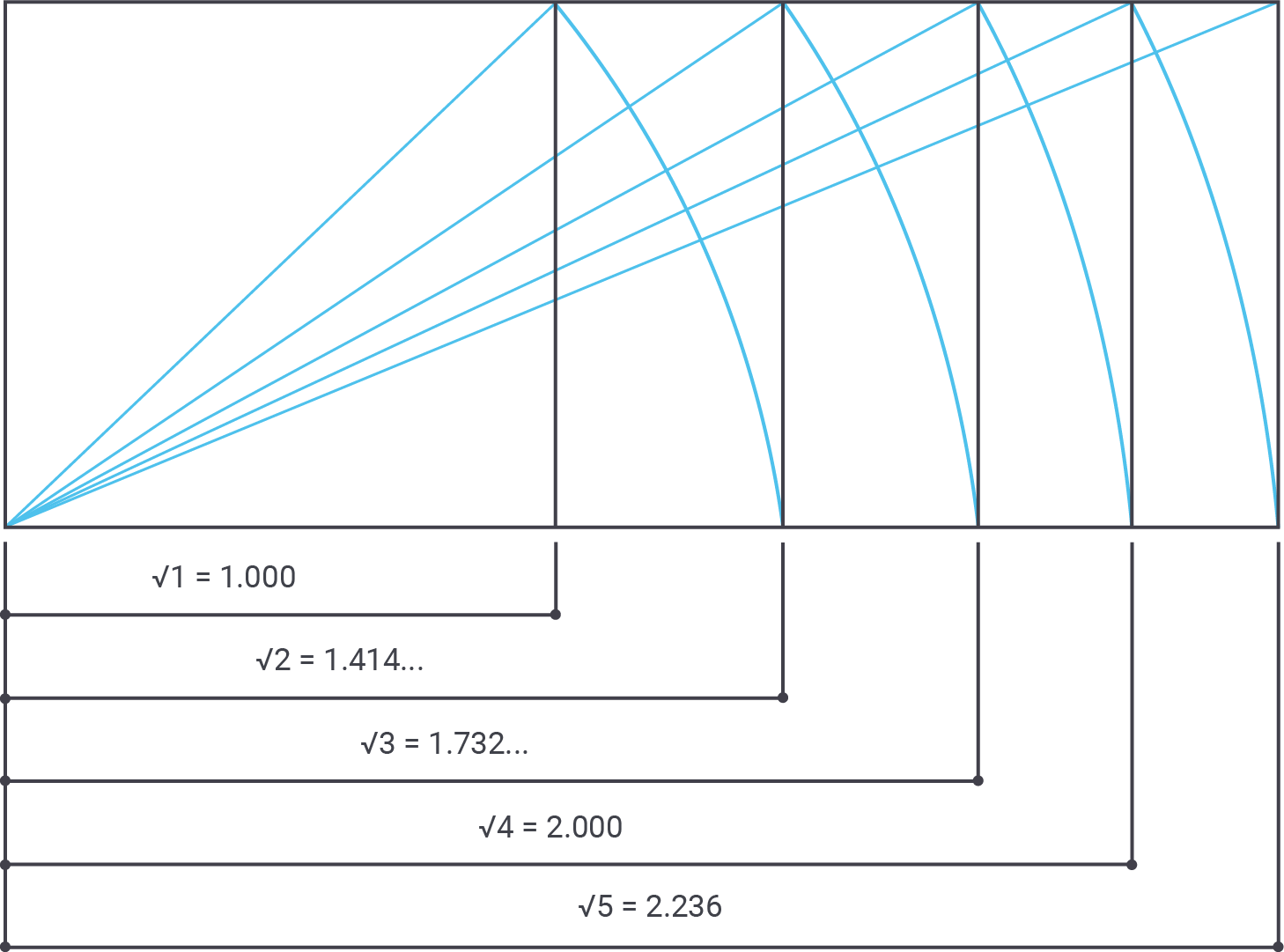
However, there are more “good” numbers in architecture than golden proportions. Square roots and so on are also important. To help calculate those numbers one can use a function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
BEGIN; CREATE TYPE good_number_type AS ( base numeric, golden_short numeric, golden_long numeric, sqrt2 numeric, sqrt3 numeric, sqrt4 numeric, sqrt5 numeric ); CREATE OR REPLACE FUNCTION good_numbers(numeric) RETURNS good_number_type AS $ SELECT ($1, 0.382 * $1, 0.618 * $1, sqrt(2) * $1, sqrt(3) * $1, 2 * $1, sqrt(5) * $1 )::good_number_type; $ LANGUAGE 'sql'; COMMIT; |
Golden proportions are a good thing. However, sometimes it is not possible to use those numbers alone. If we look at some of the greatest buildings (Pantheon, etc.) in the world, we will see that the architects also worked with square roots, cubic roots and so on.
The way to do that in PostgreSQL is to use a function. However, in this case we want a function to return more than just one field. The solution to the problem is a composite data type. It can return more than just one value.
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# x Expanded display is on. test=# SELECT * FROM good_numbers(16); -[ RECORD 1 ]+----------------- base | 16 golden_short | 6.112 golden_long | 9.888 sqrt2 | 22.6274169979695 sqrt3 | 27.712812921102 sqrt4 | 32 sqrt5 | 35.7770876399966 |
22, 27m, and 35m meters are obviously correct values which we can use to ensure beauty.
What you see is that we have used the function call for one number. However, sometimes you might want to calculate things for many values. To do that, it is important to understand how you can handle the return value of composite types:
|
1 2 3 4 |
test=# SELECT a FROM good_numbers(16) AS a; -[ RECORD 1 ] ------------------------------------------------------------ a | (16,6.112,9.888,22.6274169979695,27.712812921102,32,35.7770876399966) |
As you can see, “a” can be used in the SELECT-clause (“target list”) directly. The result is not that readily readable-- however, it is possible to expand this field and extract individual columns as shown in the next listing:
|
1 2 3 4 5 6 |
test=# SELECT (a).base, (a).golden_short, (a).golden_long FROM good_numbers(16) AS a; base | golden_short | golden_long ------+--------------+------------- 16 | 6.112 | 9.888 (1 row) |
This opens the door to calculate our numbers for an entire series of numbers:
|
1 2 3 4 5 6 7 8 9 |
test=# SELECT (good_numbers(id)).* FROM generate_series(1, 4) AS id; base | golden_short | golden_long | sqrt2 | sqrt3 | sqrt4 | sqrt5 ------+--------------+-------------+------------------+------------------+-------+------------------ 1 | 0.382 | 0.618 | 1.4142135623731 | 1.73205080756888 | 2 | 2.23606797749979 2 | 0.764 | 1.236 | 2.82842712474619 | 3.46410161513775 | 4 | 4.47213595499958 3 | 1.146 | 1.854 | 4.24264068711929 | 5.19615242270663 | 6 | 6.70820393249937 4 | 1.528 | 2.472 | 5.65685424949238 | 6.92820323027551 | 8 | 8.94427190999916 (4 rows) |
All we did was to pass the “id” to the function and expand those columns.
If you want to learn more about upgrading PostgreSQL, you should check out our blog post about logical replication.
by Kaarel Moppel
I decided to start out this year by looking into my notes from last year and extracting from them a small set of Postgres tips for you. This might not be, strictly speaking, fresh news... but I guess the average RAM of tech workers is about 64KB or so nowadays, so some repetition might not be such a bad thing.
This is a huge one – and you're really missing out if you've not heard of this feature or are not using it enough... as too often seems to be the case in my daily consulting work! Thus this was the first item on my list from last year. For larger amounts of data, partial indexes can literally be a life-saving trick when your back is already against the wall due to some unexpected increase in workload or disk usage. One of the reasons this feature is relatively unknown is that most other popular DBMS engines don't have it at all, or they call it by another name.
The crux of the thing is super easy to remember – stop indexing the most common values! Since Postgres knows what your data looks like, it does not use the index whenever you search for a value that’s too common! As always, when you reduce indexes, you're not just winning on the storage - you can also avoid the penalties incurred when you're inserting or modifying the data. So: with partial indexes, when a new column contains the most common value, we don't have to go and touch the index at all!
When does a value become “too common”? Sadly, there is no simple rule for this, as it depends on a couple of other config/data layout variables as well as the actual queries themselves - but roughly, starting at about 25-50% of the total rows, Postgres will tend to ignore the indexes.
Here is a small test table with 100 million rows to help you visualize the possible size benefits.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
CREATE UNLOGGED TABLE t_event ( id int GENERATED BY DEFAULT AS IDENTITY, state text NOT NULL, data jsonb NOT NULL ); /* 1% NEW, 4% IN_PROCESSING, 95% FINISHED */ INSERT INTO t_event (state, data) SELECT CASE WHEN random() < 0.95 THEN 'FINISHED' ELSE CASE WHEN random() < 0.8 THEN 'IN_PROCESSING' ELSE 'NEW' END END, '{}' FROM generate_series(1, 5 * 1e7); postgres=# dt+ List of relations Schema | Name | Type | Owner | Size | Description --------+---------+-------+----------+---------+------------- public | t_event | table | postgres | 2489 MB | (1 row) CREATE INDEX ON t_event (state); CREATE INDEX ON t_event (state) WHERE state <> 'FINISHED'; postgres=# di+ t_event_state_* List of relations Schema | Name | Type | Owner | Table | Size | Description --------+--------------------+-------+----------+---------+---------+------------- public | t_event_state_idx | index | postgres | t_event | 1502 MB | public | t_event_state_idx1 | index | postgres | t_event | 71 MB | (2 rows) |
Another tip on partial indexes (to finish off the topic) – usually, another perfect set of candidates are any columns that are left mostly empty, i.e., "NULL". The thing is that unlike Oracle, PostgreSQL has default all-encompassing indexes, so that all the NULL-s are physically stored in the index!
Quite often, you will need to evaluate the approximate size of a number of rows of data for capacity planning reasons. In these cases, there are a couple of approaches. The simplest ones consist of looking at the table size and row count and then doing some elementary math. However, the simplest approaches can be too rough and inaccurate – most often due to bloat; another reason could be that some historical data might not have some recently added columns (for example, due to some peculiarities of when Postgres built-in compression kicks in, etc.) The fastest way to get an estimate is to use the EXPLAIN command. EXPLAIN has the information embedded on the "cost" side - but do note that the estimate may use stale statistics, and it's generally pretty inaccurate on "toasted" columns.
|
1 2 3 4 5 |
explain select * from pgbench_accounts a; QUERY PLAN --------------------------------------------------------------------------- Seq Scan on pgbench_accounts a (cost=0.00..2650.66 rows=100366 width=97) (1 row) |
The function listed below, which answers the question raised above, is a welcome discovery for most people when they see it in action. Probably, not many people know about this due to the somewhat "hidden" function name (naming things is one of the two most difficult problems in computer science 🙂 ), and due to the fact that we're abusing the function - which is expecting a column - by feeding in a whole row! Remember: in Postgres all tables automatically get a virtual table type with all columns that is kind of a "scalar" - if they are not, for example, unpacked with "t.*".
|
1 2 3 4 5 |
select avg(pg_column_size(a)) from pgbench_accounts a; avg ---------------------- 120.9999700000000000 (1 row) |
The advantage of this function is that we can exactly specify and inspect the data that we're interested in. It also handles the disk storage side of things like compression and row headers!
Keep in mind that the size determined still does not usually map 1-to-1 to real-life disk usage for larger amounts of data due to good old companions like "bloat" and normal "defragmentation" or "air bubbles". So if you want super-sharp estimates, there's no way around generating some real-life test data. But do use a TEMP or UNLOGGED table if you do so; no need to create a huge WAL spike...especially if you happen to run a bunch of replicas.
A fun (or maybe sad) fact from the Postgres consulting trenches - most Postgres users are running some pretty darn old versions! One of many reasons behind that is commonly voiced as, “We cannot stop our business for so and so many minutes.” I say - fair enough, minutes are bad...but with Logical Replication (LR) we're talking about seconds!!! It’s no magic, far from it - the built-in LR introduced in v10 couldn't be any simpler! We’ve performed many such migrations. In most instances, everything functioned seamlessly, just as planned! However, there could be issues if the verification or switchover phase is extended for too long.
To sum it up, when it comes to LR, there's truly no justification for using outdated versions—especially considering how quickly technology evolves in the digital age!. If my article got you curious and you want to learn more about this topic, I'd suggest starting here.
By the way, if you're on some pre v10 instance, but higher or equal to v9.4, then logical upgrades are also possible via a 3rd party plugin called "pglogical", which often worked quite well when I used it some years ago.
What if you’re unhappy with your indexing performance? Maybe there are some other more cool index types available for your column? Postgres has a bunch of those, actually...
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
postgres=# SELECT DISTINCT a.amname FROM pg_type t JOIN pg_opclass o ON o.opcintype = t.oid JOIN pg_am a ON a.oid = o.opcmethod WHERE t.typname = 'int4'; amname -------- btree hash brin (3 rows) |
And that's not all - after declaring some "magic" extensions:
|
1 2 |
CREATE EXTENSION btree_gin; CREATE EXTENSION btree_gist; |
the picture changes to something like that below. Quite a lot of stuff to choose from for our good old integer!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
postgres=# SELECT DISTINCT a.amname FROM pg_type t JOIN pg_opclass o ON o.opcintype = t.oid JOIN pg_am a ON a.oid = o.opcmethod WHERE t.typname = 'int4'; amname -------- bloom brin btree gin gist hash (6 rows) |
By the way, if you're thinking, “What the hell are all those weird index types? Why should I give them a chance?”, then I would recommend starting here and here.
Since we are talking about data types...how do we determine what is actually delivered to us by the Postgres engine in tabular format? What type of data is in column XYZ for example?
The thing is that sometimes you get some above-average funky query sent to you where developers are having difficulties with "you might need to add explicit type casts" complaints from the server, converting some end results of a dozen sub-selects and transformations, so that the original column and its data type have already fallen into an abyss. Or, maybe the ORM needs an exact data type specified for your query, but runtime metadata introspection might be a painful task in the programming language at hand.
So here’s a quick tip on how to employ a PostgreSQL DBA's best friend "psql" (sorry, doggos) for that purpose:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
postgres=# SELECT 'jambo' mambo, 1 a, random(), array[1,2]; mambo | a | random | array -------+---+---------------------+------- jambo | 1 | 0.28512335791514687 | {1,2} (1 row) postgres=# gdesc Column | Type --------+------------------ mambo | text a | integer random | double precision array | integer[] (4 rows) |
This only works starting from v11 of Postgres.
Thanks for reading, and hopefully it got you back on track to start learning some new Postgres stuff again in 2021! Check out last years blogpost for more tips.
Data types are an important topic in any relational database. PostgreSQL offers many different types, but not all of them are created equal. Depending on what you are trying to achieve, different column types might be necessary. This post will focus on three important ones: the integer, float and numeric types. Recently, we have seen a couple of support cases related to these topics and I thought it would be worth sharing this information with the public, to ensure that my readers avoid some common pitfalls recently seen in client applications.
To get started, I’ve created a simple table containing 10 million rows. The data types are used as follows:
|
1 2 3 4 5 6 7 8 9 10 |
test=# CREATE TABLE t_demo (a int, b float, c numeric); CREATE TABLE test=# INSERT INTO t_demo SELECT random()*1000000, random()*1000000, random()*1000000 FROM generate_series(1, 10000000) AS id; INSERT 0 10000000 test=# VACUUM ANALYZE; VACUUM test=# timing Timing is on. |
After the import, optimizer statistics and hint bits have been set to ensure a fair comparison.
While the purpose of the integer data type is clear, there is an important difference between the numeric type and the float4 / float8 types. Internally, float uses the FPU (floating point unit) of the CPU. This has a couple of implications: Float follows the IEEE 754 standard, which also implies that the rounding rules defined by the standard are followed. While this is totally fine for many data sets, (measurement data, etc.) it is not suitable for handling money.
In the case of money, different rounding rules are needed, which is why numeric is the data type you have to use to handle financial data.
Here’s an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# SELECT a, b, c, a + b, a + b = c FROM (SELECT 0.1::float8 a, 0.2::float8 b, 0.3::float8 c ) AS t; a | b | c | ?column? | ?column? -----+-----+-----+---------------------+---------- 0.1 | 0.2 | 0.3 | 0.30000000000000004 | f (1 row) |
As you can see, a floating point number always uses approximations. This is perfectly fine in many cases, but not for money. Your favorite tax collector is not going to like approximations at all; that’s why floating point numbers are totally inadequate.
However, are there any advantages of numeric over a floating point number? The answer is: Yes, performance …
Let us take a look at a simple comparison:
|
1 2 3 4 5 6 7 |
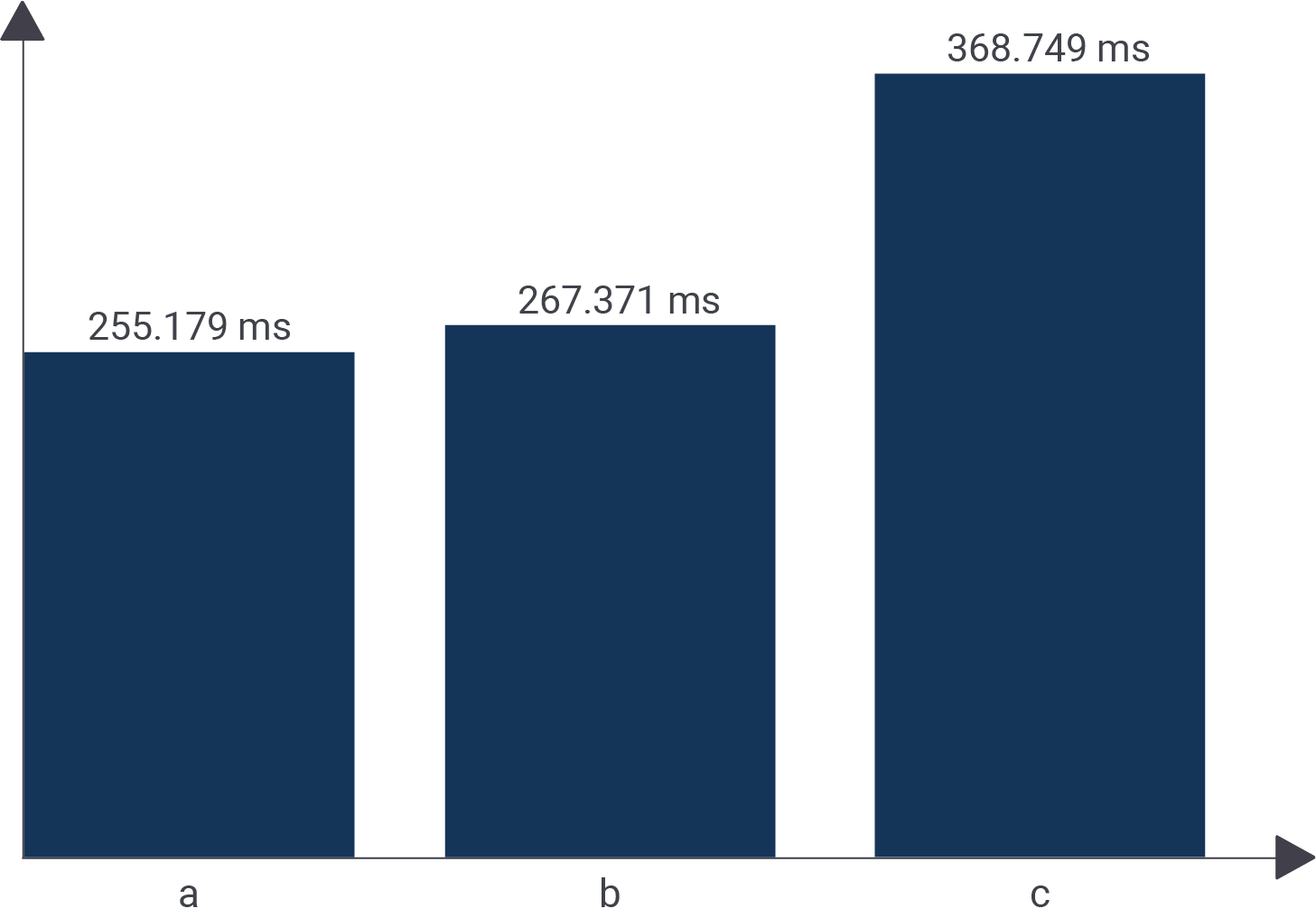
test=# SELECT avg(a) FROM t_demo; avg --------------------- 499977.020028900000 (1 row) Time: 255.179 ms |
Integer is pretty quick. It executes in roughly 250 ms. The same is true for float4 as you can see in the next listing:
|
1 2 3 4 5 6 7 |
test=# SELECT avg(b) FROM t_demo; avg ------------------- 499983.2076499941 (1 row) 3 Time: 267.371 ms |
However, the numeric data type is different. There is a lot more overhead, which is clearly visible in our little benchmark:
|
1 2 3 4 5 6 7 |
test=# SELECT avg(c) FROM t_demo; avg ------------------------- 500114.1490108727200733 (1 row) Time: 368.749 ms |
This query is a lot slower. The reason is the internal representation: “numeric” is done without the FPU and all operations are simulated using integer operations on the CPU. Naturally, that takes longer.
The following image shows the difference:
If you want to know more about performance, I can recommend one of our other blog posts about HOT updates.