An Entity Relationship (ER) diagram is one of the most important tools for database design. It helps you visualize the relationships between different entities and how they interact with each other. Many GUI tools have their own tools to build ER diagrams, e.g. pgAdmin IV, DBeaver, etc.
In this blog post, we'll explore how to create an ER diagram for a PostgreSQL database using plain SQL and Mermaid. Mermaid is a JavaScript-based diagramming and charting tool that renders Markdown-inspired text definitions to create and modify diagrams dynamically.
Table of Contents
Today I will show you how to generate an ER diagram for any PostgreSQL database using only plain SQL and Mermaid. I propose to use the Pagila example database as a target. You may either install it locally, or run a Docker Compos script.
The task is to create an SQL script which will output valid Mermaid syntax. Later we can use either Mermaid Live Editor or a local installation to view and save the ER diagram in one of the preferred formats, e.g. .svg, .png, etc.
If you examine Mermaid ER syntax, you will find that:
I've split the SQL script into 3 parts. The first one is very basic - it outputs the special keyword erDiagram to indicate how Mermaid should visualize the diagram.
|
1 2 3 |
select 'erDiagram' union all ... |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
select format(E't%s{n%sn}', c.relname, string_agg(format(E'tt~%s~ %s', format_type(t.oid, a.atttypmod), a.attname ), E'n')) from pg_class c join pg_namespace n on n.oid = c.relnamespace left join pg_attribute a ON c.oid = a.attrelid and a.attnum > 0 and not a.attisdropped left join pg_type t ON a.atttypid = t.oid where c.relkind in ('r', 'p') and not c.relispartition and n.nspname !~ '^pg_' AND n.nspname <> 'information_schema' group by c.relname union all ... |
Here's what the above snippet does:
c.relname) and the associated column names (a.attname) with data types (t.oid) from the pg_class, pg_namespace, pg_attribute, and pg_type tables.create table foo(); is a valid DDL statement.a.attnum > 0) and columns that are still valid (not a.attisdropped).information_schema schemas. The partitions themselves are not interesting for us, because they are only implementation details.|
1 2 3 4 5 6 7 8 |
select format('%s }|..|| %s : %s', c1.relname, c2.relname, c.conname) from pg_constraint c join pg_class c1 on c.conrelid = c1.oid and c.contype = 'f' join pg_class c2 on c.confrelid = c2.oid where not c1.relispartition and not c2.relispartition; |
This snippet is much easier:
c.contype = 'f').Here is the final script to copy-paste:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
select 'erDiagram' union all select format(E't%s{n%sn}', c.relname, string_agg(format(E'tt~%s~ %s', format_type(t.oid, a.atttypmod), a.attname ), E'n')) from pg_class c join pg_namespace n on n.oid = c.relnamespace left join pg_attribute a ON c.oid = a.attrelid and a.attnum > 0 and not a.attisdropped left join pg_type t ON a.atttypid = t.oid where c.relkind in ('r', 'p') and not c.relispartition and n.nspname !~ '^pg_' AND n.nspname <> 'information_schema' group by c.relname union all select format('%s }|..|| %s : %s', c1.relname, c2.relname, c.conname) from pg_constraint c join pg_class c1 on c.conrelid = c1.oid and c.contype = 'f' join pg_class c2 on c.confrelid = c2.oid where not c1.relispartition and not c2.relispartition; |
And here is how the final result looks for the Pagila database (click to enlarge):
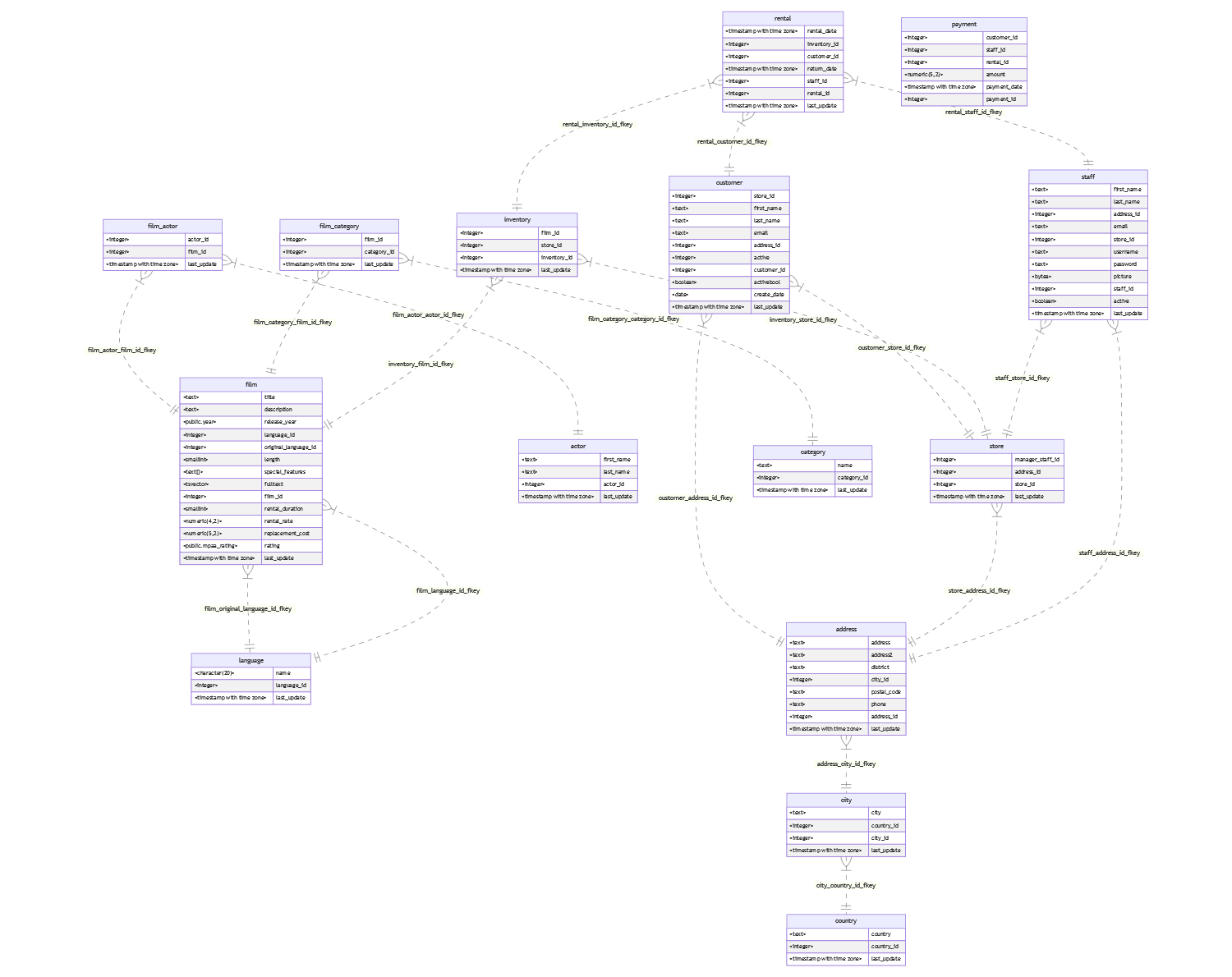
Thanks for reading, I hope you enjoyed it! If you liked this one, check out my blog post about usql, universal psql!
I love it! Thanks. Just tried it on a schema of mine containing names
with spaces (I like problems), and the mermaid parser failed. It should
render names with double quotes, something that
format()should beable to handle with a %I formatter, no?
Yeah, it's not perfect. I already broke it several times ( https://github.com/mermaid-js/mermaid/issues/4008 ). And AFAIK one cannot use double quoting for relation names. It should be improved, agree. You can check the sources and maybe propose a PR ( https://github.com/mermaid-js/mermaid/tree/develop/packages/mermaid/src/diagrams/er ).
from what I tried, it looks like it works, just wrap names with double quotes as in:
family_has_attribute }|..|| family : "family has attribute"
I want to make updates to your SQL sample:
from____pg_class c
____join pg_namespace n on n.oid = c.relnamespace
____left join pg_attribute a ON c.oid = a.attrelid
I would write like this:
FROM pg_class c__JOIN pg_namespace n
____ON n.oid = c.relnamespace
__LEFT JOIN pg_attribute a
____ON a.attrelid = c.oid
please note:
- reserved keywords are in upper case
- visually easy to find joined tables and conditions
- in join condition expression for joined table is always on left
Thanks. UPPERCASE reserved SQL words are kind of holy war nowadays. 🙂 If you check my previous posts, I always use uppercase there. This time I decided to use lowercase.
Are these rules specified somewhere or are they your personal preferences?
its my best practice after 27 years of experience working with sql
The choice of using all uppercase or lowercase SQL reserved words in
coding is a matter of personal preference, which may have originated
from a time when code editors did not have color-coding features. While I
used to favor all uppercase SQL reserved words, I am now gravitating
towards using all lowercase. Regardless of the choice, it's essential to
maintain consistency throughout.
The code samples don't show backslashes that are required to represent tab and newlines characters. Copying and pasting and SQL code as-is doesn't work. For example:
should be
It seems like the web page strips single backslashes from string. My comment from a few months ago had as its 2nd code sample: format(E' followed by backslash-t -- but the backslash isn't shown in my comment. Probably the same is true with the code sample.
I love this, thanks!