
Table of Contents
It is known that high network latency is bad for database performance. PostgreSQL v14 has introduced “pipeline mode” for the libpq C API, which is particularly useful to get decent performance over high-latency network connections. If you are using a hosted database in “the cloud”, then this article might be interesting for you.
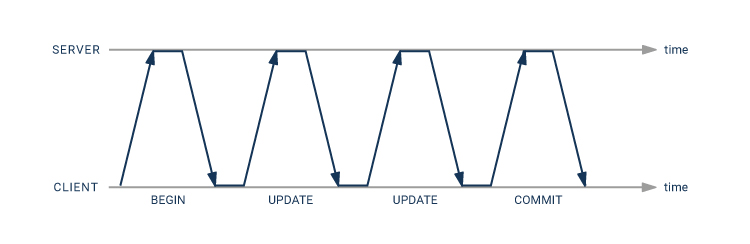
To understand pipeline mode, we have to understand the message flow between client and server. Using the extended query protocol, statements get processed as follows:
The database transaction is finished by sending a “Sync” message. These messages are typically sent in a single TCP packet. All of the above messages are generated by a call to the PQexec or PQexecParams functions of libpq. In the case of a prepared statement, the “Parse” step is separated from the “Bind” and “Execute” steps.
After “Sync” has been sent, the client waits for a response from the server. The server processes the statement and replies with
Finally, the server sends a “ReadyForQuery” message to indicate that the transaction is complete and it is ready for more. Again, these messages are typically sent in a single TCP packet.
Pipeline mode is nothing new on the frontend/backend protocol level. It just relies on the fact that you can send more than one statement before sending “Sync”. This allows you to send multiple statements in a single transaction without waiting for a response from the server. What is new is support for this from the libpq API. PostgreSQL v14 introduced the following new functions:
PQenterPipelineMode: enter pipeline modePQsendFlushRequest: sends a “Flush” message to tell the server to start sending back responses to previous requests right away (otherwise, the server tries to bundle all responses into a single TCP packet)PQpipelineSync: sends a “Sync” message – you must call this explicitlyPQexitPipelineMode: leave pipeline modePQpipelineStatus: shows if libpq is in pipeline mode or notThe statements themselves are sent using the asynchronous query execution functions PQsendQuery, PQsendQueryParams and PQsendQueryPrepared, and after the “Sync” message has been sent, PQgetResult is used to receive the responses.
Since all that does not rely on new features in the frontend/backend protocol, you can use pipeline mode with older versions of the PostgreSQL server.
Let's assume the case of a simple money transfer using a table like
|
1 2 3 4 5 |
CREATE TABLE account ( id bigint PRIMARY KEY, holder text NOT NULL, amount numeric(15,2) NOT NULL ); |
To transfer money from one account to the other, we have to run a transaction like
|
1 2 3 4 |
BEGIN; UPDATE account SET amount = amount + 100 WHERE id = 42; UPDATE account SET amount = amount - 100 WHERE id = 314; COMMIT; |
With normal processing, that makes four round trips from the client to the server, so the whole transaction will incur eight times the network latency.
Using the pipeline mode, you can get away with only twice the network latency:
UPDATE statement can be sent immediately after the first one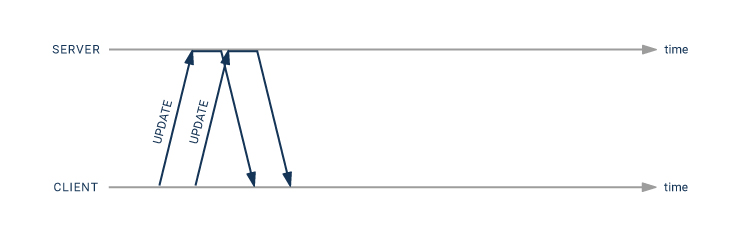
This is C code that can be used to process the above transaction. It uses a prepared statement stmt for this UPDATE statement:
|
1 2 3 4 |
UPDATE account SET amount = amount + $2 WHERE id = $1 RETURNING amount; |
In order to focus on the matter at hand, I have omitted the code to establish a database connection and prepare the statement.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 |
#include <libpq-fe.h> #include <stdio.h> /* * Receive and check a statement result. * If 'res' is NULL, we expect a NULL result and * print the message if we get anything else. * If 'res' is not NULL, the result is stored there. * In that case, if the result status is different * from 'expected_status', print the message. */ static int checkResult(PGconn *conn, PGresult **res, ExecStatusType expected_status, char * const message) { PGresult *r; if (res == NULL) { if ((r = PQgetResult(conn)) == NULL) return 0; PQclear(r); fprintf(stderr, '%s: unexpected resultn', message); return 1; } if ((*res = PQgetResult(conn)) == NULL) { fprintf(stderr, '%s: missing resultn', message); return 1; } if (PQresultStatus(*res) == expected_status) return 0; fprintf(stderr, '%s: %sn', message, PQresultErrorMessage(*res)); PQclear(*res); return 1; } /* transfer 'amount' from 'from_acct' to 'to_acct' */ static int transfer(PGconn *conn, int from_acct, int to_acct, double amount) { PGresult *res; int rc; char acct[100], amt[100]; /* will fit a number */ char * const values[] = { acct, amt }; /* parameters */ /* enter pipeline mode */ if (!PQenterPipelineMode(conn)) { fprintf(stderr, 'Cannot enter pipeline mode: %sn', PQerrorMessage(conn)); return 1; } /* send query to subtract amount from the first account */ snprintf(values[0], 100, '%d', from_acct); snprintf(values[1], 100, '%.2f', -amount); if (!PQsendQueryPrepared(conn, 'stmt', /* statement name */ 2, /* parameter count */ (const char * const *) values, NULL, /* parameter lengths */ NULL, /* text parameters */ 0)) /* text result */ { fprintf(stderr, 'Error queuing first update: %sn', PQerrorMessage(conn)); rc = 1; } /* * Tell the server that it should start returning results * right now rather than wait and gather the results for * the whole pipeline in a single packet. * There is no great benefit for short statements like these, * but it can reduce the time until we get the first result. */ if (rc == 0 && PQsendFlushRequest(conn) == 0) { fprintf(stderr, 'Error queuing flush requestn'); rc = 1; } /* * Dispatch pipelined commands to the server. * There is no great benefit for short statements like these, * but it can reduce the time until we get the first result. */ if (rc == 0 && PQflush(conn) == -1) { fprintf(stderr, 'Error flushing data to the server: %sn', PQerrorMessage(conn)); rc = 1; } /* send query to add amount to the second account */ snprintf(values[0], 100, '%d', to_acct); snprintf(values[1], 100, '%.2f', amount); if (rc == 0 && !PQsendQueryPrepared(conn, 'stmt', /* statement name */ 2, /* parameter count */ (const char * const *) values, NULL, /* parameter lengths */ NULL, /* text parameters */ 0)) /* text result */ { fprintf(stderr, 'Error queuing second update: %sn', PQerrorMessage(conn)); rc = 1; } /*--- * Send a 'sync' request: * - flush the remaining statements * - end the transaction * - wait for results */ if (PQpipelineSync(conn) == 0) { fprintf(stderr, 'Error sending 'sync' request: %sn', PQerrorMessage(conn)); rc = 1; } /* consume the first statement result */ if (checkResult(conn, &res, PGRES_TUPLES_OK, 'first update')) rc = 1; else printf('Account %d now has %sn', from_acct, PQgetvalue(res, 0, 0)); if (res != NULL) PQclear(res); /* the next call must return nothing */ if (checkResult(conn, NULL, -1, 'end of first result set')) rc = 1; /* consume the second statement result */ if (checkResult(conn, &res, PGRES_TUPLES_OK, 'second update')) rc = 1; else printf('Account %d now has %sn', to_acct, PQgetvalue(res, 0, 0)); if (res != NULL) PQclear(res); /* the next call must return nothing */ if (checkResult(conn, NULL, -1, 'end of second result set')) rc = 1; /* consume the 'ReadyForQuery' response */ if (checkResult(conn, &res, PGRES_PIPELINE_SYNC, 'sync result')) rc = 1; else if (res != NULL) PQclear(res); /* exit pipeline mode */ if (PQexitPipelineMode(conn) == 0) { fprintf(stderr, 'error ending pipeline mode: %sn', PQresultErrorMessage(res)); rc = 1; } return rc; } |
To verify the improvement in speed , I used the tc utility on my Linux system to artificially add a 50 millisecond latency to the loopback interface:
|
1 |
sudo tc qdisc add dev lo root netem delay 50ms |
This can be reset with
|
1 |
sudo tc qdisc del dev lo root netem |
I measured the time spent in the above function, as well as the time for a function that used no pipeline and an explicit transaction:
| no pipeline (8 times network latency) | pipeline (2 times network latency) | |
|---|---|---|
| first attempt | 406 ms | 111 ms |
| second attempt | 414 ms | 104 ms |
| third attempt | 414 ms | 103 ms |
With short SQL statements like these, the speed gain from pipelining is almost proportional to the client-server round trips saved.
If you don't want to use the libpq C API or directly speak the frontend/backend protocol, there is another way to get a similar performance improvement: you can write a PL/pgSQL function or procedure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE PROCEDURE transfer( p_from_acct bigint, p_to_acct bigint, p_amount numeric ) LANGUAGE plpgsql AS $$BEGIN UPDATE account SET amount = amount - p_amount WHERE id = p_from_acct; UPDATE account SET amount = amount + p_amount WHERE id = p_to_acct; END;$$; |
This will also run inside a single transaction and is just as fast, because
CALL statementWriting a PL/pgSQL procedure is in this case probably the simpler solution. However, pipeline mode allows you precise control over the message and data flow between client and server, which you won't get with a function.
You may not be able to use this solution in case you operate in an environment where database functions are an anathema. But then, strictly held religious beliefs can be expected to make you suffer occasionally!
Pipeline mode, new with the libpq C API in PostgreSQL v14, allows for considerable performance improvements with laggy network connections. Since it doesn't use new features in the frontend/backend protocol, it can be used with old server versions as well. Often, similar performance gains can be achieved using PL/pgSQL functions.
If you are interested in data manipulation performance, you may want to read my article about HOT updates.
Why not to use pipeline mode by default?
Or, when not to use pipeline? any caveat?
Actually, that's rare situation when you need to send several statements one by one without fetching results
That would break existing code.
Now, you can write
PGsendQuery-PGgetResult-PGsendQuery-PGgetResult, but that would be an error in pipeline mode (you'd have to send an explicity "sync" in between to close the first pipeline.