Data types are an important topic in any relational database. PostgreSQL offers many different types, but not all of them are created equal. Depending on what you are trying to achieve, different column types might be necessary. This post will focus on three important ones: the integer, float and numeric types. Recently, we have seen a couple of support cases related to these topics and I thought it would be worth sharing this information with the public, to ensure that my readers avoid some common pitfalls recently seen in client applications.
Table of Contents
To get started, I’ve created a simple table containing 10 million rows. The data types are used as follows:
|
1 2 3 4 5 6 7 8 9 10 |
test=# CREATE TABLE t_demo (a int, b float, c numeric); CREATE TABLE test=# INSERT INTO t_demo SELECT random()*1000000, random()*1000000, random()*1000000 FROM generate_series(1, 10000000) AS id; INSERT 0 10000000 test=# VACUUM ANALYZE; VACUUM test=# timing Timing is on. |
After the import, optimizer statistics and hint bits have been set to ensure a fair comparison.
While the purpose of the integer data type is clear, there is an important difference between the numeric type and the float4 / float8 types. Internally, float uses the FPU (floating point unit) of the CPU. This has a couple of implications: Float follows the IEEE 754 standard, which also implies that the rounding rules defined by the standard are followed. While this is totally fine for many data sets, (measurement data, etc.) it is not suitable for handling money.
In the case of money, different rounding rules are needed, which is why numeric is the data type you have to use to handle financial data.
Here’s an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# SELECT a, b, c, a + b, a + b = c FROM (SELECT 0.1::float8 a, 0.2::float8 b, 0.3::float8 c ) AS t; a | b | c | ?column? | ?column? -----+-----+-----+---------------------+---------- 0.1 | 0.2 | 0.3 | 0.30000000000000004 | f (1 row) |
As you can see, a floating point number always uses approximations. This is perfectly fine in many cases, but not for money. Your favorite tax collector is not going to like approximations at all; that’s why floating point numbers are totally inadequate.
However, are there any advantages of numeric over a floating point number? The answer is: Yes, performance …
Let us take a look at a simple comparison:
|
1 2 3 4 5 6 7 |
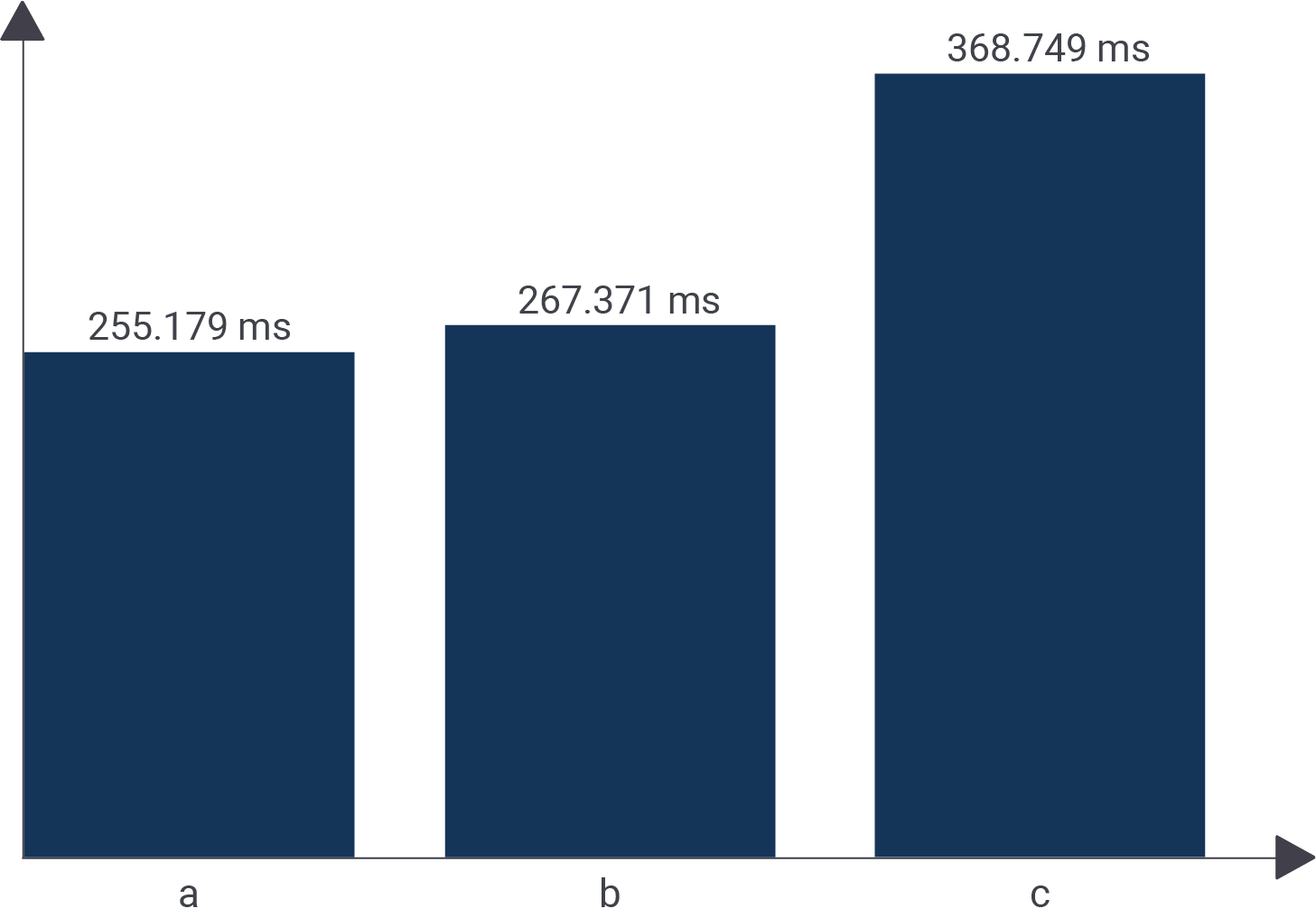
test=# SELECT avg(a) FROM t_demo; avg --------------------- 499977.020028900000 (1 row) Time: 255.179 ms |
Integer is pretty quick. It executes in roughly 250 ms. The same is true for float4 as you can see in the next listing:
|
1 2 3 4 5 6 7 |
test=# SELECT avg(b) FROM t_demo; avg ------------------- 499983.2076499941 (1 row) 3 Time: 267.371 ms |
However, the numeric data type is different. There is a lot more overhead, which is clearly visible in our little benchmark:
|
1 2 3 4 5 6 7 |
test=# SELECT avg(c) FROM t_demo; avg ------------------------- 500114.1490108727200733 (1 row) Time: 368.749 ms |
This query is a lot slower. The reason is the internal representation: “numeric” is done without the FPU and all operations are simulated using integer operations on the CPU. Naturally, that takes longer.
The following image shows the difference:
If you want to know more about performance, I can recommend one of our other blog posts about HOT updates.
Which data type would you recommend for Lat/Lon positional data?
I would go with integer data types depending on the precision you want
I think you've got this sentence the wrong way round
> However, are there any advantages of numeric over a floating point number? The answer is: Yes, performance …
But you then go and supply example for the opposite - floats being faster.