When you think about migration from Oracle to Postgres, most people just say that it is easy. And if you consult the various sources of information, nothing tells you differently.
And it might not even be untrue. Most databases we create, manage, and run are easy to migrate. If you look at the characteristics of these databases, the large bulk of these:
Table of Contents
For moving these databases from Oracle to PostgreSQL, you do not think about a larger-scale project or other big complexities.
And that is good. These allow you to save a lot of budget where it does not make sense to spend serious money whatsoever, not even if it is from a standardization point of view, quite the contrary.
It gets significantly more interesting with “the big fish”. Those database has an alternate signature to the ones mentioned above, or they might be the “devil in disguise”. They may just have a single or perhaps two of the characteristics. A super busy and tiny database might not be so easy to move from Oracle to Postgres!
To get a firm grasp on this, we look at a database migration from the four quadrants that make up the complete setup.
This post aims to discuss these four quadrants at a little more abstract level. There is much more to explore for each of the steps along the way.
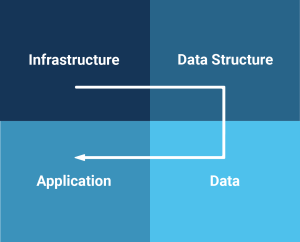
We will go through these four quadrants one by one and review their relevant attributes. For every migration these four quadrants contain elements that need to be addressed to complete a database migration successfully.
The first big step in a database migration is ensuring we have an infrastructure available for our database, and the workload to land on. Especially as we start thinking about migrating some of “the bigger fish” out there, this can be a very interesting first part of our journey.
In the source environment, we might be dealing with very specific hardware configurations. These might be Oracle Exadata machines with Infiniband connects and specific extreme internal configurations. Or we might come across Oracle RAC, with a multi-node cluster that has been tailor-made for this specific workload.
More often than not; though, as a good friend of mine once said; “If it is not configured by one of the folks on my list, I do not fear it!” In other words, most Exadata machines, and most RAC implementations are quite poorly designed or executed implementations of very powerful, but also extremely specific hardware and software. You would not be the first person to encounter a RAC cluster that fails completely upon the crash of a single node.
That all sounds great, and some of you will think: “he’s just saying that because he is into PostgreSQL!”. Well, apart from that apparent truth, the core of the message is; do not just shy away because the source environment might have specific pieces of hardware or a specific configuration.
Your challenge is to investigate if this workload needs all those bells and whistles, if it is performing up to specification and what are the bare requirements for uptime and disaster resilience. The paradigm should not be: “the best money can buy!” as that is something from days gone by. Rather it should be: “this is good enough to do the job!”
Based on those KPIs, more often than not, you will find that you will be able to build something, that, combined with Postgres, matches the existing Oracle setup. Or, as we have even found, by thinking outside (or even beyond) the box, both literally and figuratively, that a Postgres setup outperforms a comparable Oracle (or DB2, or…) architecture.
We can conclude that, even though it is not the easiest of the four quadrants, it is definitely one that can be tackled.
I have said this many times already. And I am going to say it again. The PostgreSQL extensibility system is so incredibly cool. It can do anything, and what it cannot do today, you can teach it to do it tomorrow.
From defining your own bespoke data types, through defining operators, and if you want, you can create your server-side programming language in Postgres.
Postgres can jump any hoop you can think of.
This is quite nifty and useful when you are moving from Oracle to Postgres.
But do not think of this as something daunting… Most of the tooling is out there, with the CYBERTEC Migrator leading the pack.
The Data structure, also known as “the data model” helps you achieve the goals you have set for your migration specifically and for your application in general. Depending on the requirements of your project, this might be a good time to make some changes in the physical data model, where you can work with different physical storage options or make other changes to the underlying structures to help prepare for further growth and development of the application.
The story of our third quadrant is not so much about the data itself, but much more about the things you would need from the data.
Moving data from Oracle to Postgres as an action by itself is not going to be any hassle. We have defined our target structures and ensured we have a nice new home for our precious data.
The interesting elements of this part of our project are:
If you have a small database, that is not “very important” and gets infrequent updates or additions, you will have little challenges. But if some of these criteria get more demanding, so will the complexity of your data movement increase. I want to touch briefly on all four of these points.
If you have a very large quantity of data to be moved, time will be your challenge. This time will impact your considerations when you start looking at the other 3 points. Depending on the actual size, which might run into multiple terabytes, influenced by distance. Imagine the difference if you have the source and the target neatly together in one rack on one switch, or having the source in your data center, with the target “somewhere in some Cloud”.
An important database might be very busy. Almost regardless of the size of your dataset, you will need to consider the changes that happen to the source data, while you move to your new target and how you will catch up. With a small system, doing 100 TPS, that takes you 20 minutes to move, you will need to catch up 120,000 transactions which is, at the very least, something that you need to be sufficiently aware of.
If your database system is super important. If it is the backend of a web store, or if it is part of some form of chained data management solution, where external systems depend on it for answers or data persistence, you might not be able to afford any downtime. You will need to find a way to ensure continuity. This availability answers to the same criteria as your disaster recovery planning; RTO (Recovery Time Objective, how much time can your data be unavailable) and RPO (Recovery Point Objective, how many transactions can you afford to lose)..
From a solutions perspective, there are many things you can do. One of the more common things you would do is to do an online migration. In this scenario, you do an initial “big bulk” migration. After that, you establish a mechanism that keeps both the source and the target database up-to-date with the changes to happen. This mechanism usually is a form of implementation of “Change Data Capture” or CDC that processes the transactions logs and forwards relevant changes from the source to the target and/or vice versa.
Another area that you may want to explore is segmentation. By dividing your data into multiple logical units or tiers, you might very well find that some of the challenges of your migration get easier. You are splitting your database into smaller databases which each have different demands. You might end up with one, single critical piece that is so “small” that you still have a good shot at migrating it without breaking your SLAs.
You can do this at the source, but more easily and more cheaply, most of these tricks can be applied at the target, where you can make Postgres jump through your architectural hoops.
All of this work and planning finally brings us to the fourth quadrant to consider. And, not an unimportant part at that! What is data worth if you cannot work with it? I am guessing nothing!
Especially when it comes to Oracle and Postgres, the definition of “application” goes in two directions. What we traditionally know as applications; are the screens you use to do your data operations (Create, Read, Update, and Delete). But also, your database side application code for super efficient data management, using stored procedures, triggers, constraints and what have you.
Both Oracle and Postgres have very strong procedural languages embedded in their server. As we saw with the Postgres extensibility system, PostgreSQL even allows you to build your own languages, complete with data types and operators.
Moving database side application code is where the CYBERTEC Migrator steps in and helps you out with automatic translations, a knowledge base, and many suggestions to complete this. Within an integrated migration recommendation, you get estimates for completing the migration, including database-sided application code.
It usually gets a bit painful when it comes to the traditional application. This might be written in almost any programming language, where it might or might not include your selection of dialect-specific SQL queries (where Oracle deviates from the more general interpretations of the ANSI-SQL Standards) or procedural code, both invisible from the database.
Depending on the availability of the original programmers guild, and the complexity of the code, you might be in for a formidable refactoring of the application.
Looking at your project and considering the four quarters of an Oracle migration, I think we have found our missing piece.
Until now.

Even though we are very far along with our project, the chain is as strong as its weakest link. If we cannot get our application working, what’s the use of the migration? How much time, effort, and money do we need to invest to cover the last few meters?
Now, there is CYPEX. A rapid web application development framework that predicts what your application at the target side should be. You just have to make it pretty, and you are done!
“How do you do this?”, you might ask. Remember quadrant two of our project, the “Data structure”? The data structure has the foundation for the application locked inside. Just think about it. If you look at your data structure with a bit of an intelligent view, all that you need is already there, from relationships to dependencies to representations of values.
This is what CYPEX brings:
All of this brings you the logical application that you just have to paint on the screen and you are done.
We can help! We have done migrations multiple hundreds of times, not in Powerpoint, but hands-on!
With the introduction of CYPEX, we can give you even more capabilites to cover all four quadrants of your database migration project.
Leave traditional, legacy, proprietary database management systems and embrace the future, head-long. No more excuses.
Leave a Reply