
CLUSTER is sometimes the last resort to squeeze performance out of an index scan. Normally, you have to repeat CLUSTER regularly to maintain good performance. In this article, I will show you how you can get away without re-CLUSTERing even in the face of concurrent UPDATEs. Thanks to Steven Hulshof for the idea!
Table of Contents
In a PostgreSQL table (also known as a "heap"), the order of the rows doesn't matter. For fast access to rows, you use a B-tree index. However, if you have to scan a whole range of rows using an index, it could easily be that each row you fetch from the table is in a different 8kB block of the table, which can lead to a lot of expensive I/O operations (Figure 1).
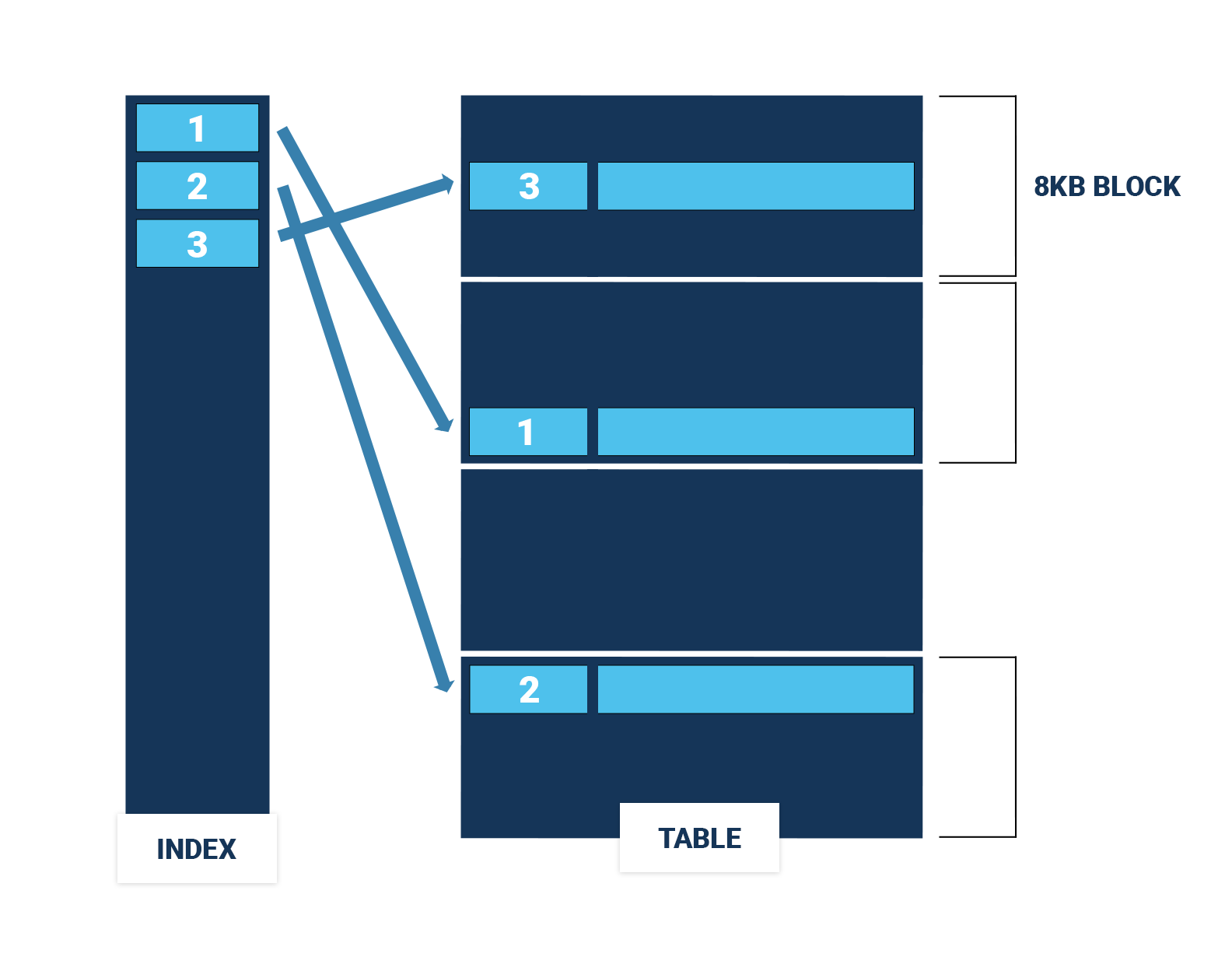
If the rows in the table happen to be sorted in the same order as the index, an index range scan becomes much cheaper, since it has to access far fewer table blocks (Figure 2). In this case, order does matter.
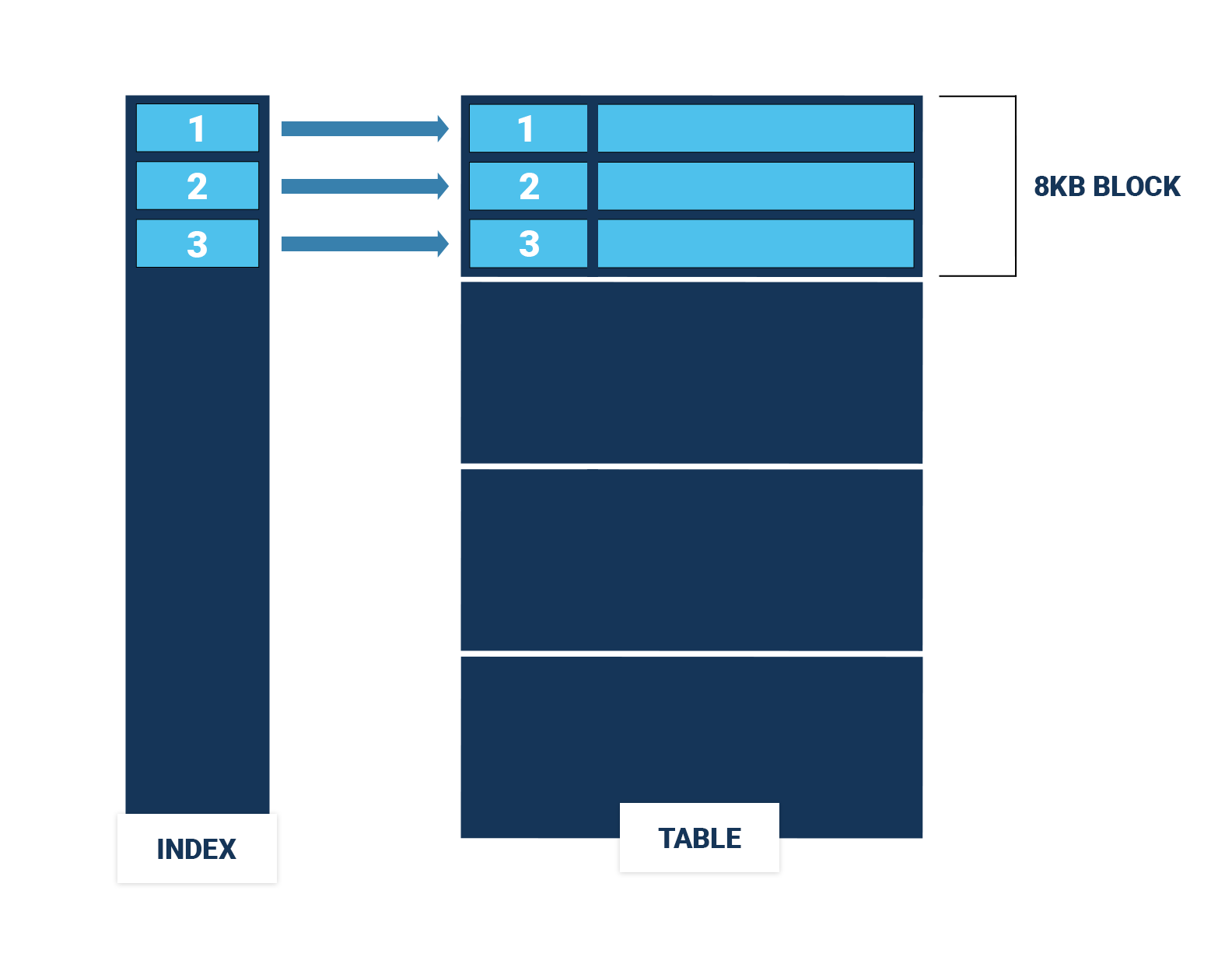
You can use the command CLUSTER to rewrite a table in the order of an index to speed up range scans via that index. Naturally, there can be only one physical ordering of a table, so you can only speed up range scans on one of the indexes on a table. Still, if two indexes share leading columns, clustering the table on one of the indexes will to some extent also speed up range scans on the other index.
Among the statistical data that ANALYZE gathers for each column, there is also the correlation between the column values and the physical order of the rows. This is a number between -1 and 1. If the correlation is 1, the rows are ordered in ascending order of the values. If the correlation is -1, the table is physically sorted in descending order of the values. A correlation around 0 means that there is no connection between the physical and the logical order. The PostgreSQL optimizer uses this correlation to estimate the cost of index range scans.
CLUSTERThe code behind CLUSTER is the same as for VACUUM (FULL), with an additional sort. Consequently, CLUSTER shares all the problems of VACUUM (FULL):
CLUSTER locks the table in ACCESS EXCLUSIVE mode, so you cannot even read itIn addition, the order that CLUSTER establishes won't last: subsequent INSERTs and UPDATEs won't respect the ordering, and the correlation will “rot” over time. So you will have to repeat the painful procedure regularly if you want your index range scans to stay fast.
DELETE won't destroy the ordering of the rows, and there is nothing you can do to prevent INSERTs from messing up your correlation. However, there is a PostgreSQL feature that can keep UPDATE from destroying the table order: HOT updates.
A HOT update places the new version of a row in the same 8kB block as the old one, and it doesn't modify any indexed column, so it is only able to disturb the correlation of all indexed columns a tiny little bit. After a HOT update, index range scans on indexed columns will remain efficient!
As described before, HOT may preserve the correlation during UPDATEs, but it cannot help with INSERT at all. Moreover, you have to set a fillfactor below 100 to get mostly HOT updates, which artificially bloats your table. So it slows down sequential scans and renders caching less effective.
CLUSTERWe create the table without constraints for speedy loading. Since WAL is irrelevant for the effect we want to observe, an unlogged table is good enough, will speed up the tests and won't put stress on my disk. If we set shared_buffers big enough, no I/O has to happen at all.
|
1 2 3 4 5 6 7 8 |
CREATE UNLOGGED TABLE clu ( id bigint NOT NULL, key integer NOT NULL, val integer NOT NULL ) WITH ( autovacuum_vacuum_cost_delay = 0, fillfactor = ??? ); |
I will experiment with different fillfactors. Since I'm going to use pgbench to hammer the table with UPDATEs, I tune autovacuum to run as fast as possible, so it can cope with the workload.
Then I insert 10 million rows so that key is correlated around 0:
|
1 2 3 |
INSERT INTO clu (id, key, val) SELECT i, hashint4(i), 0 FROM generate_series(1, 10000000) AS i; |
Now I create a clustering index and rewrite the table in key order:
|
1 2 |
CREATE INDEX clu_idx ON clu(key); CLUSTER clu USING clu_idx; |
Finally, I add a primary key, gather statistics and set the hint bits:
|
1 2 3 4 |
ALTER TABLE clu ADD PRIMARY KEY (id); /* set hint bits and gather statistics */ VACUUM (ANALYZE) clu; |
pgbench to run a benchmarkThe built-in benchmark tool pgbench is the best fit for our test. I will use the following custom script:
|
1 2 |
set i random(1, 10000000) UPDATE clu SET val = val + 1 WHERE id = :i; |
Then I let pgbench run the UPDATE 60 million times with 6 concurrent clients:
|
1 2 |
pgbench --random-seed=42 --no-vacuum --file=updates --transactions=10000000 --client=6 |
We are mainly interested in how well the correlation is preserved:
|
1 2 3 4 5 |
ANALYZE clu; SELECT correlation FROM pg_stats WHERE tablename = 'clu' AND attname = 'key'; |
Then I am curious how many of the UPDATEs were HOT, and if autovacuum was triggered or not:
|
1 2 3 |
SELECT n_tup_hot_upd, autovacuum_count FROM pg_stat_user_tables WHERE relname = 'clu'; |
As soon as all UPDATEs are hot, I know that lowering the fillfactor won't make a difference any more.
Finally, I want to know how much the table and its indexes were bloated.
|
1 2 3 4 5 6 7 |
SELECT pg_size_pretty( pg_table_size('clu') ) AS tab_size, pg_size_pretty( pg_total_relation_size('clu') - pg_table_size('clu') ) AS ind_size; |
Once all UPDATEs are HOT, there won't be any bloat beyond the one we created with the fillfactor.
I ran my test with PostgreSQL 15.2. Table and index bloat are measured relative to the size of the newly created table and indexes with the default fillfactor (the table occupied 422 MB, and the two indexes together occupied 428 MB).
| fillfactor | correlation | HOT updates | table bloat | index bloat |
|---|---|---|---|---|
| 100 | 0.4906983 | 92 % | 36 % | 48 % |
| 95 | 0.55435437 | 94 % | 36 % | 46 % |
| 90 | 0.6514189 | 96 % | 34 % | 17 % |
| 85 | 0.7231404 | 97 % | 38 % | 0 % |
| 80 | 0.921137 | 99 % | 30 % | 0 % |
| 75 | 1 | 100 % | 33 % | 0 % |
If a table receives no INSERTs and we can set fillfactor so that all or most of the UPDATEs are HOT, the table can remain in the order established by CLUSTER for a much longer time or forever. This way, we can get fast index range scans with no or a reduced need to re-CLUSTER regularly. The reason is that HOT updates keep the new version of an updated row in the same page as the original row.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
Leave a Reply