People tend to think that a SELECT-operation is always a read. This might look obvious and make sense but does it actually hold true? Is a SELECT-statement a read? Can we really determine from the statement what it does so that we can safely load balance? In fact, no. The fact that something seems to be a pure read does not make it a read - and that has huge implications which will be discussed in this short but
important post.
Table of Contents
Often people try to build their own replication solution assumung that load balancing of queries can be simply handled by some kind of middleware. However, this is definitely doomed to fail. In short: Do NOT build software that magically decides in some middleware what to do.
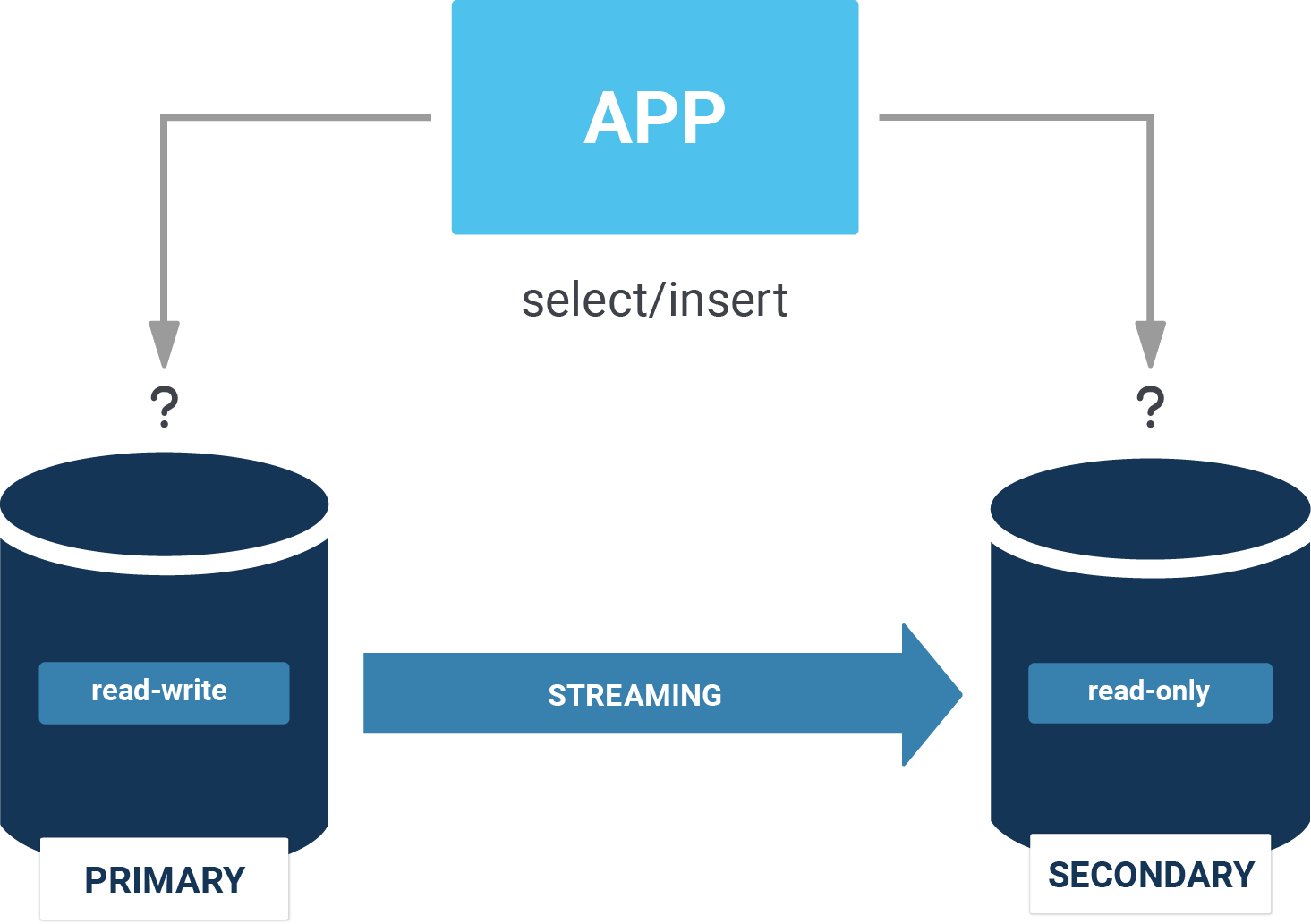
Why is that? Consider the following:
|
1 |
SELECT * FROM tab; |
But what if the following happens?
|
1 2 3 4 5 6 |
test=# CREATE TABLE a (id int); CREATE TABLE test=# CREATE FUNCTION x(int) RETURNS int AS ' INSERT INTO a VALUES ($1) RETURNING *' LANGUAGE 'sql'; CREATE FUNCTION |
In this case I have defined a simple table and a function that just happens to insert some simple data. But what if we add the following view to the scenario?
|
1 2 |
test=# CREATE VIEW tab AS SELECT * FROM a, x(10) AS y; CREATE VIEW |
This will change things because we can access the view easily:
|
1 2 3 4 |
test=# SELECT * FROM tab; id | y ----+--- (0 rows) |
If we call it again we will already see the leftovers of the previous execution:
|
1 2 3 4 5 |
test=# SELECT * FROM tab; id | y ----+---- 10 | 10 (1 row) |
From the application or middleware point of view we are still talking about a simple SELECT statement. What can possibly go wrong? Well, as you can see: A lot can go wrong because the string we send to the database does not carry all the information the middleware needs to make a decision whether we are talking about reading and writing.
Let us focus on what we want to solve here: We want to use our read-replicas which we have connected via streaming replication to do load balancing. To do that we have to know what is a read and what is a write. But who else is there who could have this information? There is only one component that knows: The application. To do load balancing the application has to be aware of what is going on.
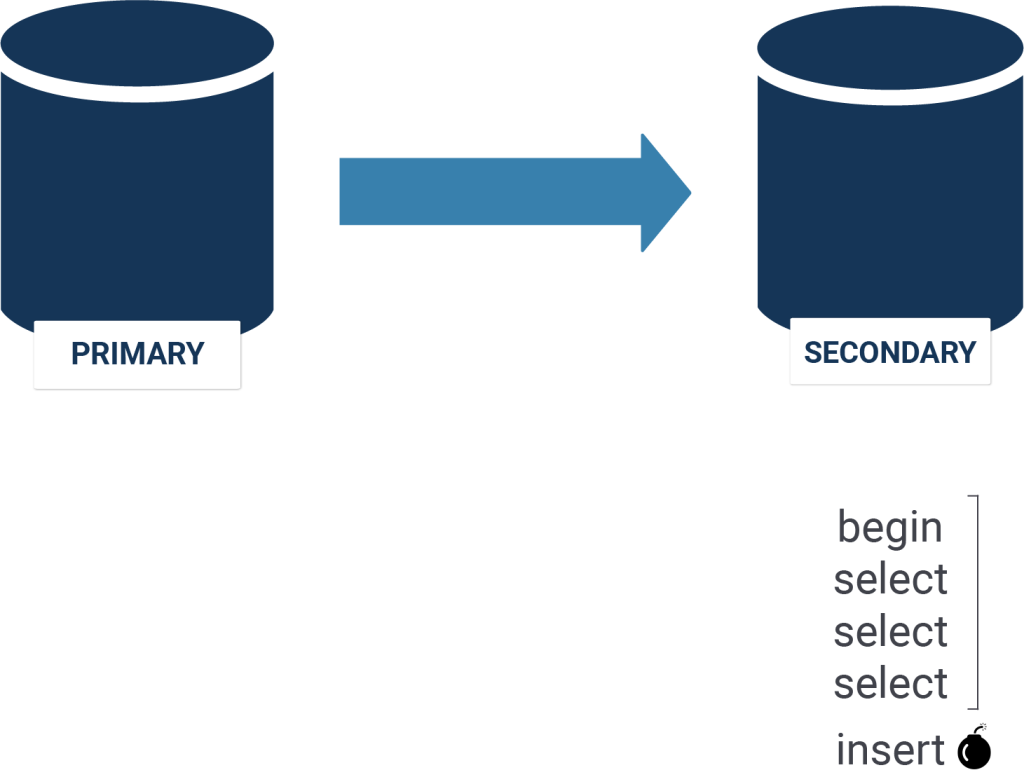
Consider the following example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
test=# START TRANSACTION; START TRANSACTION test=*# SELECT 1; ?column? ---------- 1 (1 row) test=*# SELECT 2; ?column? ---------- 2 (1 row) test=*# INSERT ... |
We start a transaction assuming that we will just read. However, during the transaction it turns out (application logic) that we indeed have to write some data. The question is: What shall we do with the open transaction? It is impossible to move it to the primary as we would immediately…
There is no other way: If you want to do load balancing you need AT LEAST two database connections. Your application has to be aware of what is a read and what is a write. There is no way around it.
There is one more thing which has to be kept here: Suppose we have made our application smart enough. It knows when it does a write and when it does a read. Can we finally simply route reads to the replicas and load balance things? In PostgreSQL there is a thing called "synchronous replication". Most people
assume that synchronous replication (synchronous_commit = on) is enough to immediately see data on the replicas. This is not true. Let reflect on what we are doing here? By default synchronous replication means that data has been written (= as in "written to the WAL") on at least two machines. This is not enough to ensure that data is visible (= SELECT) on a replica. Why can this happen? The reason for this is the concept of a "replication conflict". There are two blogs which are recommended to learn about
this:
"Dealing with replication conflicts" by Laurenz Albe
"What hot_standby_feedback in PostgreSQL really does" by Hans-Jürgen Schönig
The core idea is that a read can prevent WAL from being applied on the replica (as described in our blogs). The fact that WAL has been written to disk on the replica therefore does not ensure that you can see the data that has changed unless synchronous_commit is changed to "remote_apply" which of course comes with a handful of implications which is beyond the scope of this article.
The conclusion here is: If you are aiming for load balancing, please stop writing middleware that tries to figure out somehow how to load balance and what to load balance. It might backfire badly unless you are totally aware of what you are doing and unless you know exactly what can break things and what does not. In case transactional integrity is an issue, coming up with your own load balancing solution is most likely to fail miserably. We are posting this as a warning because we have seen too many people fail recently so that we decided to write a small article which hopefully prevents more disaster from happening.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
What would be the preferred load balancers then? pgbouncer, pgpool? any etc?
I have the impression that you missed the point of the article: no load balancer is going to help you with that in a reliable fashion. You have to teach the application to explicitly perform reads and writes on different data sources.
Ah, when you mentioned writing your middleware, I understood that you are referring own poolers solutions apart from regular poolers in market. Do you think replication parameters like read_only_function_list will help here?
Yes, that pgpool parameter is an attempt to address that problem. But we don't consider that a very robust solution: it requires that you configure pgpool with application knowledge, and if you forget something or the application changes, things will go wrong.
It is much better to have the decision where to route the statement right in the application code, so that it can be easily maintained whenever you change the code.