In PostgreSQL table bloat has been a primary concern since the original MVCC model was conceived. Therefore we have decided to do a series of blog posts discussing this issue in more detail. What is table bloat in the first place? Table bloat means that a table and/or indexes are growing in size even if the amount of data stored in the database does not grow at all. If one wants to support transactions it is absolutely necessary not to overwrite data in case it is modified because one has to keep in mind that people might want to read an old row while it is modified or rollback a transaction.
Table of Contents
Therefore bloat is an intrinsic thing related to MVCC in PostgreSQL. However, the way PostgreSQL stores data and handles transactions is not the only way a database can handle transactions and concurrency. Let us see which other options there are:
In MS SQL you will find a thing called tempdb while Oracle and MySQL put old versions into the redo log. As you might know PostgreSQL copies rows on UPDATE and stores them in the same table. Firebird is also storing old row versions inline.
There are two main points I want to make here:
Getting rid of rows is definitely an issue. In PostgreSQL removing old rows is usually done by VACUUM. However, in some cases VACUUM cannot keep up or space is growing for some other reasons (usually long transactions). We at CYBERTEC have blogged extensively about that scenario.
“No solution is without tradeoffs” is also an important aspect of storage. There is no such thing as a perfect storage engine - there are only storage engines serving a certain workload well. The same is true for PostgreSQL: The current table format is ideal for many workloads. However, there is also a dark side which leads us back to where we started: Table bloat. If you are running UPDATE-intense workloads it happens more often than not that the size of a table is hard to keep under control. This is especially true if developers and system administrators are not fully aware of the inner workings of PostgreSQL in the first place.
zheap is a way to keep table bloat under control by implementing a storage engine capable of running UPDATE-intense workloads a lot more efficiently. The project has originally been started by EnterpriseDB and a lot of effort has been put into the project already.
To make zheap ready for production we are proud to announce that our partners at Heroic Labs have committed to fund the further development of zheap and release all code to the community. CYBERTEC has decided to double the amount of funding and to put up additional expertise and manpower to move zheap forward. If there are people, companies, etc. who are also interested in helping us move zheap forward we are eager to team up with everybody willing to make this great technology succeed.
Let us take a look at the key design goals:
So let us see how those goals can be achieved in general.
zheap is a completely new storage engine and it therefore makes sense to dive into the basic architecture. Three essential components have to work together:
Let us take a look at the layout of a zheap page first. As you know PostgreSQL typically sees tables as a sequence of 8k blocks, so the layout of a page is definitely important:
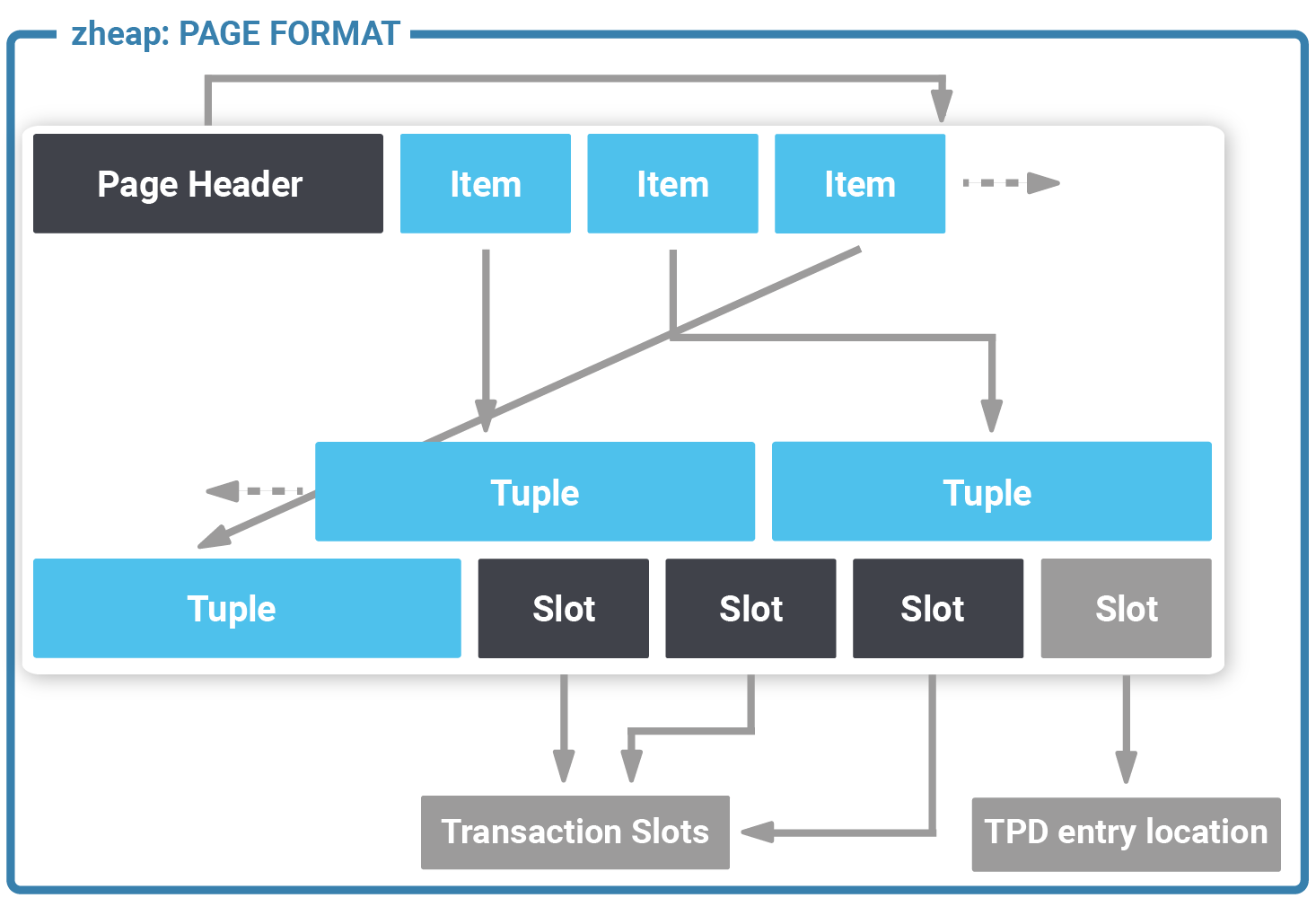
At first glance, this image looks almost like a standard PostgreSQL 8k page but in fact it is not. The first thing you might notice is that tuples are stored in the same order as item entries at the beginning of the page to allow for faster scans. The next thing we see here is the presence of “slot” entries at the end of the page. In a standard PostgreSQL table visibility information is stored as part of the row which needs a lot of space. In zheap transaction information has been moved to the page which significantly reduces the size of data (which in turn translates to better performance).
A transaction occupies 16 bytes of storage and contains the following information: transaction id, epoch and the latest undo record pointer of that transaction. A row points to a transaction slot. The default number of transaction slots in the table is 4 which is usually ok for big tables. However, sometimes more transaction slots are needed. In this case, zheap has something called “TPD” which is nothing more than an overflow area to store additional transaction information as needed.
Here is the basic layout:
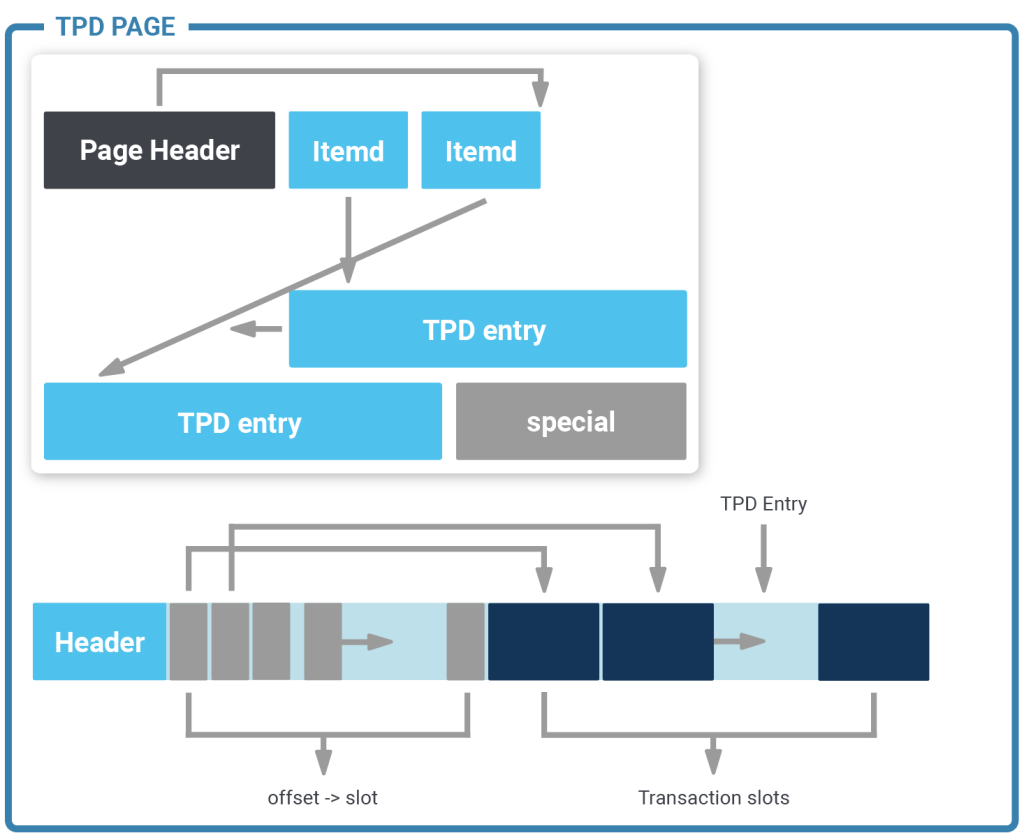
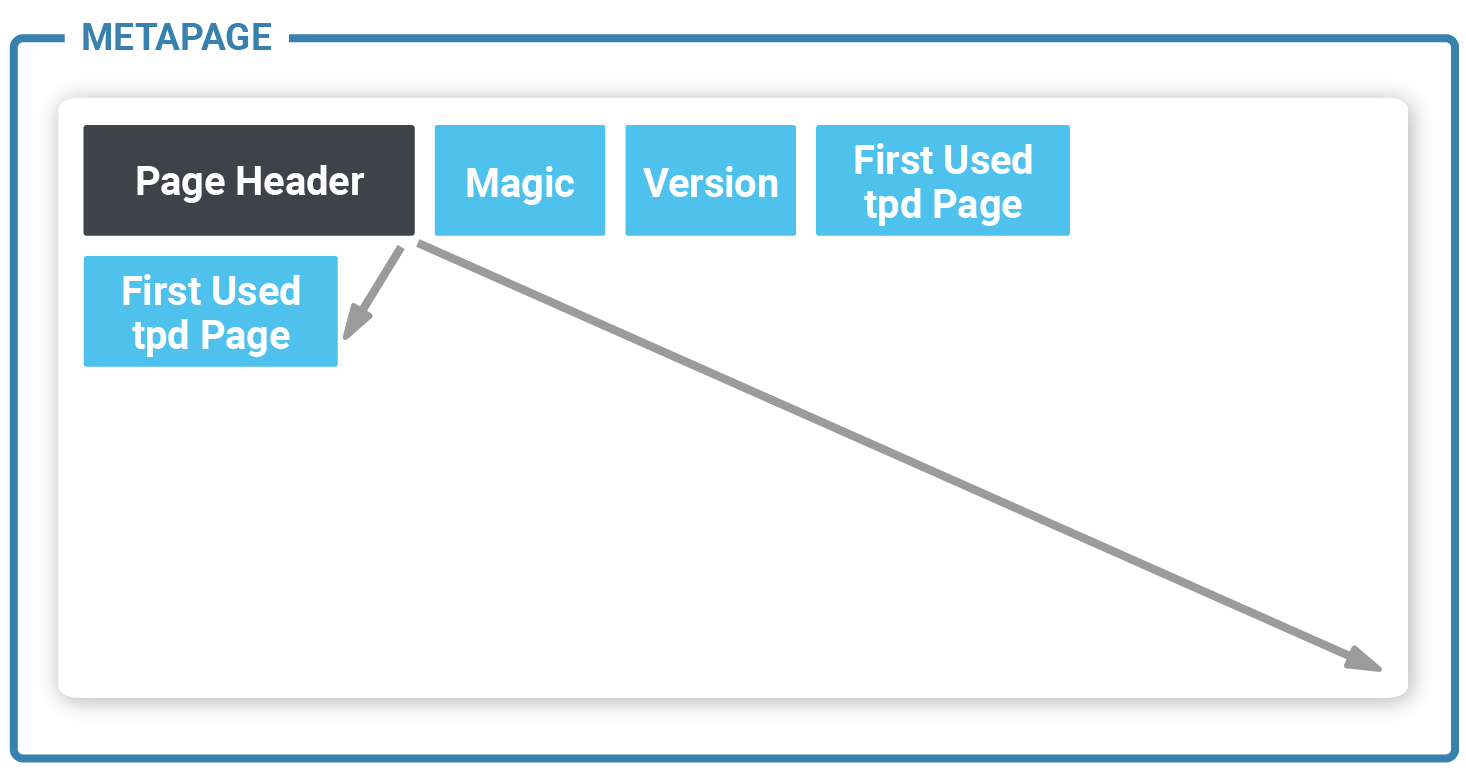
Sometimes many transaction slots are needed for a single page. TPD offers a flexible way to handle that. The question is: Where does zheap store TPD data? The answer is: These special pages are interleaved with the standard data pages. They are just marked in a special way to ensure that sequential scans won’t touch them. To track these special purpose pages zheap uses a meta page to track them:
TDP is simply a way to make transaction slots more scalable. Having some slots in the block itself reduces the need to excessively touch pages. If more are needed TPD is an elegant way out. In a way it is the best of both worlds.
Transaction slots can be reused after a transaction ends.
The next important part of the puzzle is the layout of a single tuple: In PostgreSQL a standard heap tuple has a 20+ byte header because all the transactional information is stored in a tuple. Not so in this case. All transactional information has been moved to page level structures (transaction slots). This is super important: The header has therefore been reduced to merely 5 bytes. But there are more optimizations going on here: A standard tuple has to use CPU alignment (padding) between the tuple header and the real data in the row. This can burn some bytes for every single row in the table. zheap doesn't do that, which leads to more tightly packed storage.
Additional space is saved by removing the padding from pass-by-value data types. All those optimizations mean that we can save valuable space in every single row of the table.
Here is what a standard PostgreSQL tuple header looks like:
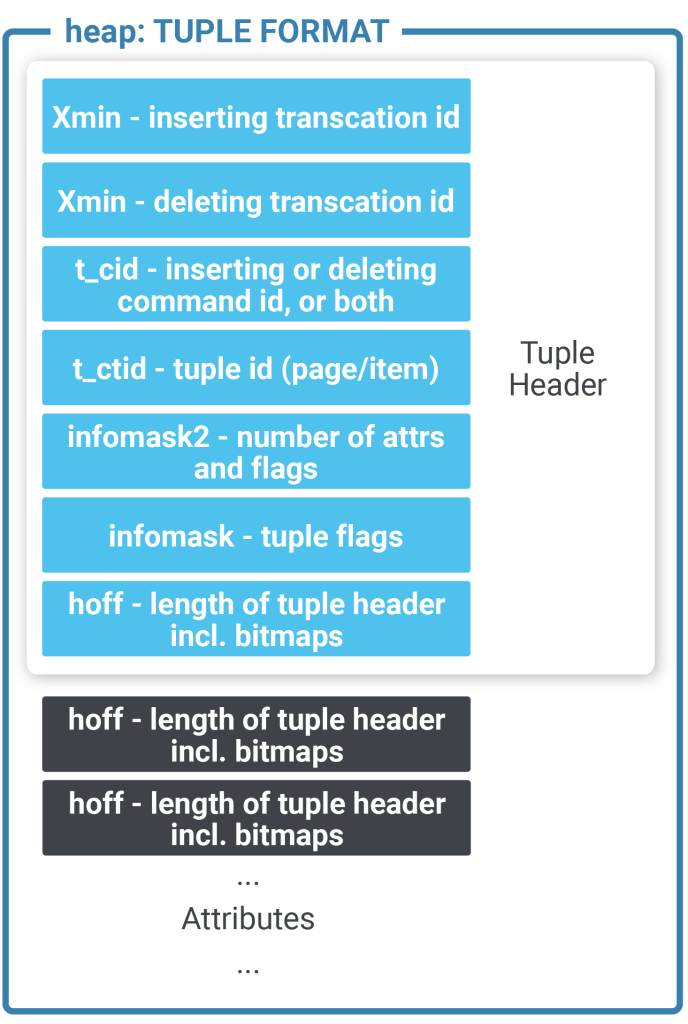 | Now let us compare this to a zheap tuple:
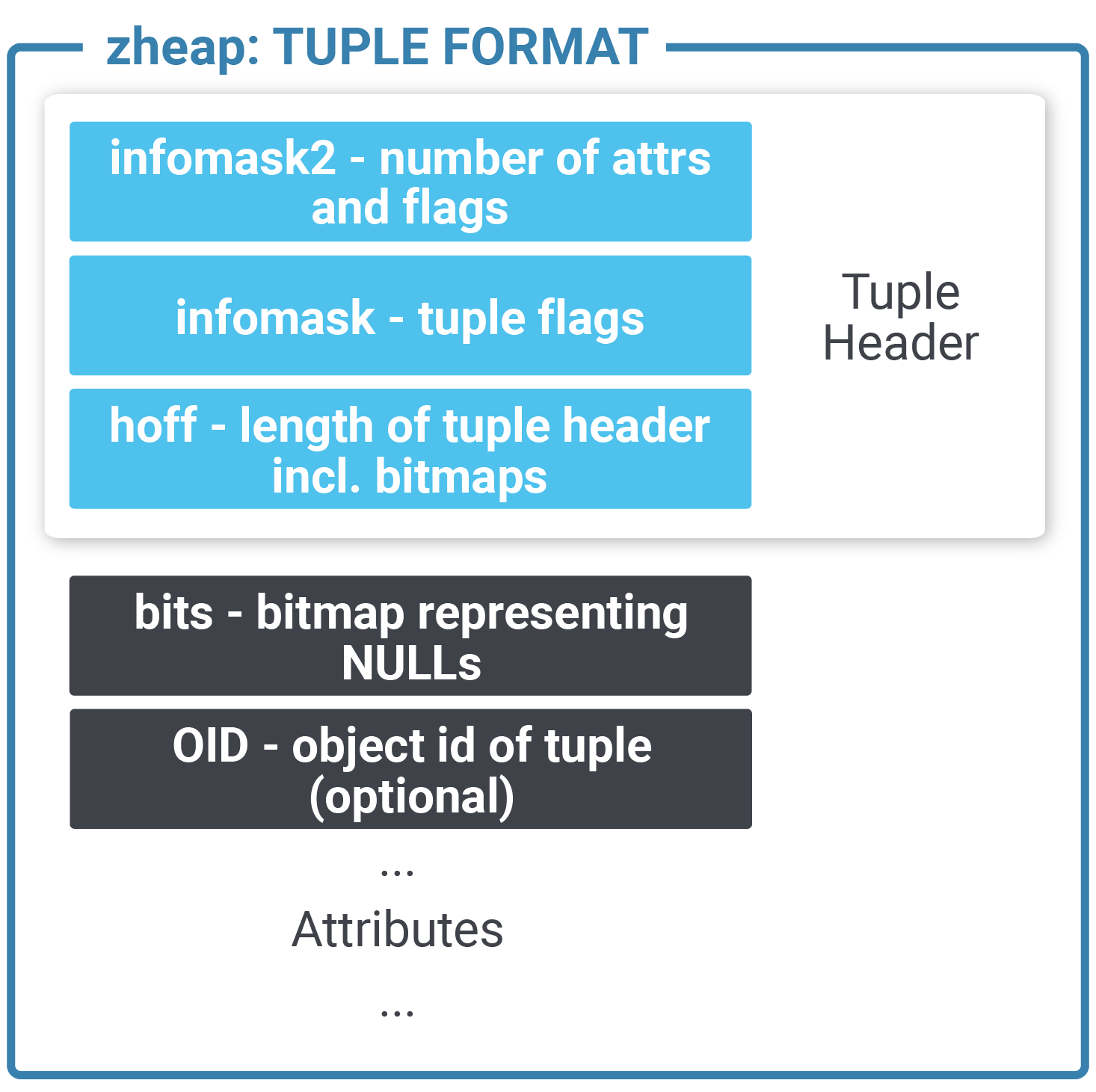 |
As you can see a zheap tuple is a lot smaller than a normal heap tuple. As the transactional information has been unified in the transaction slot machinery, we don’t have to handle visibility on the row level anymore but can do it more efficiently on the page level.
By shrinking the storage footprint zheap will contribute to good performance.
One of the most important things when talking about zheap is the notion of “undo”. What is the purpose of this thing in the first place? Let us take a look and see: Consider the following operation:
|
1 2 3 4 |
BEGIN; UPDATE tab SET x = 7 WHERE x = 5; … COMMIT / ROLLBACK; |
To ensure that transactions can operate correctly UPDATE cannot just overwrite the old value and forget about it. There are two reasons for that: First of all, we want to support concurrency. Many users should be able to read data while it is modified. The second problem is that updating a row does not necessarily mean that it will be committed. Thus we need a way to handle ROLLBACK in a useful way. The classical PostgreSQL storage format will simply copy the row INSIDE standard heap which leads to all those bloat related issues we have discussed on our blog already.
The way zheap approaches things here is a bit different: In case a modification is made the system writes “undo” information to fix it in case the transaction has to be aborted for whatever reason. This is the fundamental concept applicable to INSERT, UPDATE, and DELETE. Let us go through those operations one by one and see how it works:
In case of INSERT zheap has to allocate a transaction slot and then emit an undo entry to fix things on error. In case of INSERT the TID is the most relevant information needed by undo. Space can be reclaimed instantly after an INSERT has been rolled back which is a major difference between zheap and standard heap tables in PostgreSQL.
An UPDATE statement is far more complicated: There are basically two cases:
In case the old row is shorter than the new one we can simply overwrite it and emit an undo entry holding the complete old row. In short: We hold the new row in zheap and a copy of the old row in undo so that we can copy it back to the old structure in case it is needed.
What happens if the new row does not fit in? In this case performance will be worse because zheap essentially has to perform a DELETE / INSERT operation which is of course not as efficient as an in-place UPDATE.
Space can instantly be reclaimed in the following cases:
Finally there is DELETE. To handle the removal of a row zheap has to emit an undo record to put the old row back in place in case of ROLLBACK. The row has to be removed from the zheap during DELETE.
Up to now we have spoken quite a bit about undo and rollback. However, let us dive a bit deeper and see how undo, rollback, and so on interact with each other.
In case a ROLLBACK happens the undo has to make sure that the old state of the table is restored. Thus the undo action we have scheduled before has to be executed. In case of errors the undo action is applied as part of a new transaction to ensure success.
Ideally, all undo action associated with a single page is applied at once to cut down on the amount of WAL that has to be written. A nice side effect of this strategy is also that we can reduce page-level locking to the absolute minimum which reduces contention and therefore helps contribute to good performance.
So far this sounds easy but let us consider an important use case: What happens in the event of a really long transaction? What happens if a terabyte of data has to be rolled back at once? End users certainly don’t appreciate never-ending rollbacks. It is also worth keeping in mind that we must also be prepared for a crash during rollback.
What happens is that if undo action is larger than a certain configurable threshold the job is done by a background worker process. This is a really elegant solution that helps to maintain a good end-user experience.
Undo itself can be removed in three cases:
Let us take a look at a basic architecture diagram:
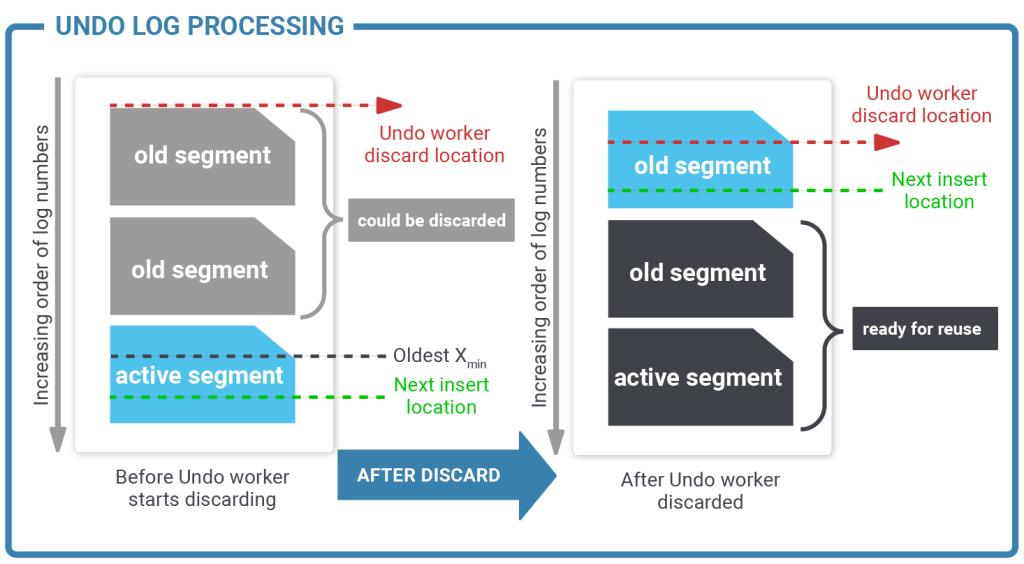
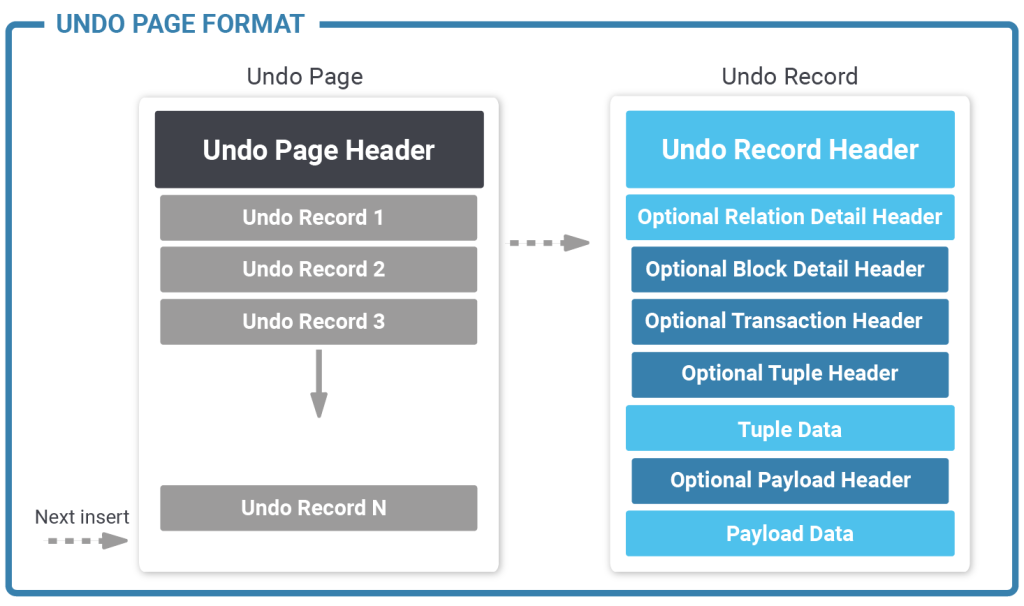
As you can see the process is quite sophisticated.
To ensure that zheap is a drop-in replacement for the current heap it is important to keep the indexing code untouched. Zheap can work with PostgreSQL’s standard access methods. There is of course room to make things even more efficient. However, at this point no changes to the indexing code are needed. This also implies that all index types available in PostgreSQL are fully available without known restrictions.
Currently zheap is still under development and we are glad for the contributions made by Heroic Labs to develop this technology further. So far we have already implemented logical decoding for zheap and added support for PostgreSQL. We will continue to allocate more resources to push the tool to make it production-ready.
If you want to read more about PostgreSQL and VACUUM right now consider checking our previous posts on the subject. In addition, we also want to invite you to keep visiting our blog on a regular basis to learn more about it and other interesting technologies.
nice blog.
Please, can we get link of github zheap repo or code?
Links added to https://wiki.postgresql.org/wiki/Zheap
Definitely look forward to see it in production !
MySQL/InnoDB stores the deltas of previous versions of the row required for MVCC in an undo logs not in the redo log.
I am happy to see that you have picked it up and completed logical replication work. However, there are a lot of design issues with the TPD stuff which are not apparent or documented very clearly but might have been discussed on pgsql-hackers. Then, I think we have pending things with heap-page-format, multi-lockers and undo layer. I am open to contribute/help to move this work forward if you are planning to do it on pgsql-hackers. Feel free to contact me at my community email in case you think my inputs can be of any help to you or this project.
Amit Kapila.
Thanks! We will contact you via email.
Would pg_xact_commit_timestamp(xmin) still return the row's commit timestamp under zheap? The diagrams seem to leave open the possibility that xmin is not recorded for the row under zheap. I'd miss that; it's been useful for me.
We can identify the xmin of the row. It is not directly stored in tuple but we can get that value. So, pg_xact_commit_timestamp should work.