
Most database tables have an artificial numeric primary key, and that number is usually generated automatically using a sequence. I wrote about auto-generated primary keys in some detail in a previous article. Occasionally, gaps in these primary key sequences can occur - which might come as a surprise to you.
This article shows the causes of sequence gaps, demonstrates the unexpected fact that sequences can even jump backwards, and gives an example of how to build a gapless sequence.
We are used to the atomic behavior of database transactions: when PostgreSQL rolls a transaction back, all its effects are undone. As the documentation tells us, that is not the case for sequence values:
To avoid blocking concurrent transactions that obtain numbers from the same sequence, a
nextvaloperation is never rolled back; that is, once a value has been fetched it is considered used and will not be returned again. This is true even if the surrounding transaction later aborts, or if the calling query ends up not using the value. For example anINSERTwith anON CONFLICTclause will compute the to-be-inserted tuple, including doing any requirednextvalcalls, before detecting any conflict that would cause it to follow theON CONFLICTrule instead. Such cases will leave unused “holes” in the sequence of assigned values.
This little example shows how a gap forms in a sequence:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE TABLE be_positive ( id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY, value integer CHECK (value > 0) ); -- the identity column is backed by a sequence: SELECT pg_get_serial_sequence('be_positive', 'id'); pg_get_serial_sequence ════════════════════════════ laurenz.be_positive_id_seq (1 row) INSERT INTO be_positive (value) VALUES (42); INSERT 0 1 INSERT INTO be_positive (value) VALUES (-99); ERROR: new row for relation 'be_positive' violates check constraint 'be_positive_value_check' DETAIL: Failing row contains (2, -99). INSERT INTO be_positive (value) VALUES (314); INSERT 0 1 TABLE be_positive; id │ value ════╪═══════ 1 │ 42 3 │ 314 (2 rows) |
The second statement was rolled back, but the sequence value 2 is not, forming a gap.
This intentional behavior is necessary for good performance. After all, a sequence should not be the bottleneck for a workload consisting of many INSERTs, so it has to perform well. Rolling back sequence values would reduce concurrency and complicate processing.
Even though nextval is cheap, a sequence could still be a bottleneck in a highly concurrent workload. To work around that, you can define a sequence with a CACHE clause greater than 1. Then the first call to nextval in a database session will actually fetch that many sequence values in a single operation. Subsequent calls to nextval use those cached values, and there is no need to access the sequence.
As a consequence, these cached sequence values get lost when the database session ends, leading to gaps:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE SEQUENCE seq CACHE 20; SELECT nextval('seq'); nextval ═════════ 1 (1 row) SELECT nextval('seq'); nextval ═════════ 2 (1 row) |
Now end the database session and start a new one:
|
1 2 3 4 5 6 |
SELECT nextval('seq'); nextval ═════════ 21 (1 row) |
As with all other objects, changes to sequences are logged to WAL, so that recovery can restore the state from a backup or after a crash. Since writing WAL impacts performance, not each call to nextval will log to WAL. Rather, the first call logs a value 32 numbers ahead of the current value, and the next 32 calls to nextval don't log anything. That means that after recovering from a crash, the sequence may have skipped some values.
To demonstrate, I'll use a little PL/Python function that crashes the server by sending a KILL signal to the current process:
|
1 2 3 4 |
CREATE FUNCTION seppuku() RETURNS void LANGUAGE plpython3u AS 'import os, signal os.kill(os.getpid(), signal.SIGKILL)'; |
Now let's see this in action:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE SEQUENCE seq; SELECT nextval('seq'); nextval ═════════ 1 (1 row) SELECT seppuku(); server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. |
Upon reconnect, we find that some values are missing:
|
1 2 3 4 5 6 |
SELECT nextval('seq'); nextval ═════════ 34 (1 row) |
It is a little-known fact that sequences can also jump backwards. A backwards jump can happen if the WAL record that logs the advancement of the sequence value has not yet been persisted to disk. Why? Because the transaction that contained the call to nextval has not yet committed:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
CREATE SEQUENCE seq; BEGIN; SELECT nextval('seq'); nextval ═════════ 1 (1 row) SELECT nextval('seq'); nextval ═════════ 2 (1 row) SELECT nextval('seq'); nextval ═════════ 3 (1 row) SELECT seppuku(); psql:seq.sql:9: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. |
Now reconnect and fetch the next sequence value:
|
1 2 3 4 5 6 |
SELECT nextval('seq'); nextval ═════════ 1 (1 row) |
This looks scary, but no damage can happen to the database: since the transaction didn't commit, it was rolled back, along with all possible data modifications that used the “lost” sequence values.
However, that leads to an interesting conclusion: don't use sequence values from an uncommitted transaction outside that transaction.
First off: think twice before you decide to build a gapless sequence. It will serialize all transactions that use that “sequence”. That will deteriorate your data modification performance considerably.
You almost never need a gapless sequence. Usually, it is good enough if you know the order of the rows, for example from the current timestamp at the time the row was inserted. Then you can use the row_number window function to calculate the gapless ordering while you query the data:
|
1 2 3 4 |
SELECT created_ts, value, row_number() OVER (ORDER BY created_ts) AS gapless_seq FROM mytable; |
You can implement a truly gapless sequence using a “singleton” table:
|
1 2 3 4 5 6 7 |
CREATE TABLE seq (id bigint NOT NULL); INSERT INTO seq (id) VALUES (0); CREATE FUNCTION next_val() RETURNS bigint LANGUAGE sql AS 'UPDATE seq SET id = id + 1 RETURNING id'; |
It is important not to create an index on the table, so that you can get HOT updates and so that the table does not get bloated.
Calling the next_val function will lock the table row until the end of the transaction, so keep all transactions that use it short.
I've shown you several different ways to make a sequence skip values — sometimes even backwards. But that is never a problem, if all you need are unique primary key values.
Resist the temptation to try for a “gapless sequence”. You can get it, but the performance impact is high.
If you are interested in learning about advanced techniques to enforce integrity, check out our blogpost on constraints over multiple rows.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
The comprehensive JSON support in PostgreSQL is one of its best-loved features. Many people – particularly those with a stronger background in Javascript programming than in relational databases – use it extensively. However, my experience is that the vast majority of people don't use it correctly. That causes problems and unhappiness in the long run.
In this article, I will try to point out good and bad uses of JSON in PostgreSQL, and provide you with guidelines that you can follow.
This data model exemplifies everything that you can do wrong:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
/* this table is fine */ CREATE TABLE people ( id bigint PRIMARY KEY, name text NOT NULL ); INSERT INTO people VALUES (1, 'laurenz'), (2, 'julian'), (3, 'ants'), (4, 'kaarel'); /* this table is ill-defined */ CREATE TABLE rooms ( id bigint PRIMARY KEY, data jsonb ); INSERT INTO rooms VALUES (1, '{ 'name': 'Room 1', 'reservations': [ { 'who': 1, 'from': '2021-06-01 09:00:00', 'to': '2021-06-01 10:00:00' }, { 'who': 3, 'from': '2021-06-01 10:00:00', 'to': '2021-06-01 11:30:00' }, { 'who': 2, 'from': '2021-06-01 13:15:00', 'to': '2021-06-01 14:45:00' }, { 'who': 1, 'from': '2021-06-01 15:00:00', 'to': '2021-06-01 16:00:00' } ] }'), (2, '{ 'name': 'Room 2', 'reservations': [ { 'who': 2, 'from': '2021-06-01 09:30:00', 'to': '2021-06-01 10:30:00' } ] }'); |
There is no reason not to have the room name as a regular column. After all, every room will have a name, and we may want to enforce constraints like uniqueness on the room name.
The room reservations are perfectly regular tabular data that define a many-to-many relationship between the rooms and the people. It would have been simple to model the same data with a junction table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/* no primary key - we'll get to that later */ CREATE TABLE reservations ( people_id bigint REFERENCES people NOT NULL, room_id bigint REFERENCES rooms NOT NULL, reserved tsrange NOT NULL ); INSERT INTO reservations VALUES (1, 1, '[2021-06-01 09:00:00,2021-06-01 10:00:00)'), (3, 1, '[2021-06-01 10:00:00,2021-06-01 11:30:00)'), (2, 1, '[2021-06-01 13:15:00,2021-06-01 14:45:00)'), (1, 1, '[2021-06-01 15:00:00,2021-06-01 16:00:00)'), (2, 2, '[2021-06-01 09:30:00,2021-06-01 10:30:00)'); |
Many people seem to think that storing few large rows in a table is more efficient than storing many small rows. There is some truth to that, since every row has some overhead, and PostgreSQL compresses large data. But if you want to retrieve only parts of the data, or want to modify them, many small rows are much more efficient - as we will see below.
The "who" attribute stores a foreign key reference to people. That is not a good idea, because it is impossible for the database to enforce such a constraint: I could just as well have inserted a reference to a non-existing person. With the junction table from above, defining a foreign key is trivial.
Moreover, you often want to join on foreign keys. With JSON, that would require a cross join with the unnested JSON array:
|
1 2 3 4 5 6 7 8 |
SELECT rooms.data ->> 'name', people.name FROM rooms CROSS JOIN LATERAL jsonb_array_elements( rooms.data -> 'reservations' ) AS res(j) JOIN people ON res.j ->> 'who' = people.id::text; |
With the junction table, that would be
|
1 2 3 4 5 |
SELECT rooms.name, people.name FROM rooms JOIN reservations AS r ON r.room_id = rooms.id JOIN people ON r.people_id = people.id; |
You can probably guess which of these two queries will be more efficient.
If you want to add a new reservation, you have to execute a statement like
|
1 2 3 4 5 6 7 8 |
UPDATE rooms SET data = jsonb_set( data, '{reservations,100000}', '{'who': 3, 'from': '2021-06-01 11:00:00', 'to': '2021-06-01 12:00:00'}', TRUE ) WHERE id = 2; |
This will fetch the complete JSON object, construct a new JSON from it and store that new object in the table. The whole JSON object has to be read and written, which is more I/O than you would want - particularly if the JSON object is large and stored out of line.
Compare how simple the same exercise would be with the junction table:
|
1 2 |
INSERT INTO reservations VALUES (3, 2, '[2021-06-01 11:00:00,2021-06-01 12:00:00)'); |
This statement will only write a small amount of data.
Deleting a reservation is just as complicated and expensive, and is left as an exercise to the reader.
So far, our data model offers no protection against overlapping reservations, which would be good to enforce in the database.
With JSON, we are pretty much out of luck here. The best that comes to mind is a constraint trigger, but that would require elaborate locking or the SERIALIZABLE transaction isolation level to be free from race conditions. Also, the code would be far from simple.
With the junction table, the exercise is simple; all we have to do is to add an exclusion constraint that checks for overlaps with the && operator:
|
1 2 3 4 5 6 |
CREATE EXTENSION IF NOT EXISTS btree_gist; ALTER TABLE reservations ADD EXCLUDE USING gist ( reserved WITH &&, room_id WITH = ); |
The extension is required to create a GiST index on a bigint column.
Simple searches for equality can be performed with the JSON containment operator @>, and such searches can be supported by a GIN index. But complicated searches are a pain.
Imagine we want to search for all rooms that are occupied at 2021-06-01 15:30:00. With JSON, that would look somewhat like
|
1 2 3 4 5 6 7 |
SELECT id FROM rooms CROSS JOIN LATERAL jsonb_array_elements( rooms.data -> 'reservations' ) AS elem(j) WHERE CAST(elem.j ->> 'from' AS timestamp) <= TIMESTAMP '2021-06-01 15:30:00' AND CAST(elem.j ->> 'to' AS timestamp) > TIMESTAMP '2021-06-01 15:30:00'; |
With our junction table, the query becomes
|
1 2 3 |
SELECT room_id FROM reservations WHERE reserved @> TIMESTAMP '2021-06-01 15:30:00'; |
That query can use the GiST index from the exclusion constraint we created above.
Don't get me wrong: JSON support in PostgreSQL is a wonderful thing. It is just that many people don't understand how to use it right. For example, the majority of questions about PostgreSQL and JSON asked on Stackoverflow are about problems that arise from the use of JSON where it had better been avoided.
Follow these guidelines when you consider using JSON in PostgreSQL:
WHERE conditions.Often it may be a good idea to store some attributes as regular table columns and others in a JSON. The less you need to process the data inside the database, the better it is to store them as JSON.
To show an example of how JSON in the database can be used with benefit, let us consider a shop that sells all kinds of mixed goods. There are some properties that all or most of the goods will have, like price, weight, manufacturer, number available or package size. Other attributes may be rare, like the type of power plug, or ambiguous, like the pitch in screws or tuning forks.
Rather than defining a table with hundreds of columns for all the possible attributes, most of which will be NULL, we model the most frequent attributes with normal table columns and use a JSON for the rest:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE TABLE wares ( id bigint PRIMARY KEY, name text UNIQUE NOT NULL, price numeric(15,2) NOT NULL, weight_kg double precision NOT NULL, available integer NOT NULL CHECK (available >= 0), manufacturer text, package_size integer NOT NULL CHECK (package_size >= 0), attributes jsonb ); /* to search in 'attributes' */ CREATE INDEX ON wares USING gin (attributes); /* for similarity search on 'name' */ CREATE EXTENSION IF NOT EXISTS pg_trgm; CREATE INDEX ON wares USING gin (name gin_trgm_ops); |
This will allow efficient queries like
|
1 2 3 4 |
SELECT name, price, available FROM wares WHERE name LIKE '%tuning fork%' AND attributes @> '{'pitch': 'a'}'; |
There is a lot you can do wrong when using JSON in PostgreSQL, especially if you are not acquainted with relational databases. However, it can be a powerful tool - when used properly.
Today, I want to share some of the lessons learned when it comes to actually building an Oracle to PostgreSQL migration tool. Moving from Oracle to PostgreSQL has become a popular sport, widely adopted by many who want to free themselves from license costs, hefty support costs and also technical limitations on the Oracle side. The same is true for people moving from MS SQL and other commercial platforms to PostgreSQL. However, my impression is that moving from Oracle to PostgreSQL is by far the most popular route. This post will teach you how to avoid pitfalls in migrations and in the development of a migration tool - learn from our years of experience with actual migrations.
Over the years, we’ve tried out many different approaches to creating the perfect tool, and we’ve definitely made some mistakes on the way - mistakes you will not want to repeat. I’ll share some of the insights I personally had on this multi-year journey. I can’t give you a complete account of them in the space of a short article, so what I’ve done here is to highlight the most useful methods you can take advantage of to make migrations more efficient. I'll tell you how to avoid the main sources of error, including what slows down migrations and where the differences between how Oracle and PostgreSQL handle data present difficulties.
In case you are migrating just one or two gigabytes of data from Oracle to PostgreSQL, transaction length is really not relevant. However, things are different if we are talking about 10+ TB of data. For many clients, downtime is not an option. To achieve close-to-zero downtime, you need to support CDC (= change data capture). The idea is to take an initial snapshot of data and then apply the changes as the target system (= PostgreSQL) catches up with the source database.
In reality, this means that we have to copy a vast amount of data from Oracle while changes are still being made to the source database. What you soon face on the Oracle side is a famous problem:
|
1 |
ORA-01555 Error Message “Snapshot Too Old” |
Many of you with migration experience will be painfully aware of this issue. Ideally, you need to ensure that Oracle is configured properly to handle real transactions, not just short read bursts. It makes sense to teach the migrator beforehand to check for these frequent showstoppers.
We also need to keep an additional issue from Oracle in mind:
|
1 |
ORA-08177: can't serialize access for this transaction |
PostgreSQL has very good and proper support for high transaction isolation levels - Oracle does not. You can’t just blindly fire up a transaction in isolation SERIALIZABLE and expect things to work - they won’t. Some foresight has to be applied while reading the data, as well. Otherwise, Oracle’s limitations will become painfully obvious. The bottom line really is: Reading many many TBs of data is not the same as reading a handful of rows. It makes a huge difference, and you have to prepare for that.
PostgreSQL users are a bit spoiled. Querying the system catalog is usually extremely fast. In fact, 99% of all PostgreSQL users have never spent a minute on system catalog performance in the first place. When building a migration toolchain such as the CYBERTEC Migrator, the Oracle catalog has to be extensively queried and closely examined. The first thing you will notice: is, “Oh god, how slow can it be?”. What does that mean for migrations? The horrible performance has a couple of implications:
If your graphical interfaces rely on Oracle system catalog performance, your user experience is doomed. The application won’t be usable anymore. We found this to be especially true if the number of objects to be migrated is high
PostgreSQL stores many things such as views in binary format, which comes with a couple of advantages. Consider the following:
|
1 2 3 4 5 6 |
test=# CREATE TABLE a (aid int); CREATE TABLE test=# CREATE TABLE b (bid int); CREATE TABLE test=# CREATE VIEW v AS SELECT * FROM a, b; CREATE VIEW |
I have created two tables and a view joining them. So far, it’s all pretty straightforward, and works within Oracle as well. However, what happens if we rename “a” to “c”?
|
1 2 |
test=# ALTER TABLE a RENAME TO c; ALTER TABLE |
In PostgreSQL, the name of the view is just a label. Behind the scenes, everything is a “number”. We simply don’t store a view as a string; rather, it is stored as a binary representation. That has a couple of advantages:
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# d+ v View 'public.v' Column | Type | Collation | Nullable | Default | Storage | Description --------+---------+-----------+----------+---------+---------+------------- aid | integer | | | | plain | bid | integer | | | | plain | View definition: SELECT c.aid, b.bid FROM c, b; |
The view is still valid, and PostgreSQL will automatically use the new name. In Oracle, that’s NOT the case. You will end up with an INVALID view. Your migration tool has to be prepared at all times for this -- many types of objects in Oracle can actually be invalid. You will require extra logic to exclude and mark those if you want to ensure a smooth transition. Otherwise, you will again jeopardize your user experience, because you have to retry the reply process countless times-- as it keeps failing because of all those stale and invalid objects.
We have done countless migrations in the past. What we have seen too often is unusable data coming from Oracle. Basically, there are two frequent errors: null bytes and broken data. Null bytes simply have to be excluded. But, there is a catch: In various industries (including but not limited to finance) changes made to data have to be documented, so that regulators can track what has happened with the information in transit. That basically means that we just can’t exclude data and be happy (even if the data is obviously broken).
You have to capture those rows and document them. In some cases, it might also be necessary to come up with transformation rules. The idea is again to have revision-safe rules which actually describe what has happened to the data. This is vital to success and acceptance. Of course, we can’t keep migrating TBs of data to find out over and over again that data cannot be loaded. What you need is some kind of “dry run” and a “find me all the broken data run” to again ensure that the tooling stays reasonably usable.
The way PostgreSQL handles COPY statements in case of error cases certainly does not help much. You have to find a couple of ways to ensure that the transaction loading the data ALWAYS commits, even if a lot of data is loaded at a time.
When loading data, PostgreSQL - as well as every other relational database, including Oracle - has to write a WAL (= Write-Ahead transaction Log). Not everyone is fully aware of the consequences: We actually have to write data TWICE. It can mean that up to 40% of the total time needed to load data into PostgreSQL is used for that doubled I/O. For more information on reducing WAL, see my post about reducing checkpoint distances.
But there is more: Did you know that the first reading operation after a write is usually also a write? Yes, you read that correctly. A simple SELECT can be a write operation. Why is that the case? The reason is: hint bits. In other words, once you have loaded the data, it does NOT mean that you are done writing to disk. There might still be TBs of I/O (= especially O) left once the migration is over. This can lead to bad performance instantly after switching to the new system.
You’ve got to avoid that at all costs. Loading has to be done intelligently. One way to do it is to use COPY FREEZE, as described in one of my posts on the topic. It also helps to have some general awareness of hint bits, to create the most optimal loading process possible.
What this shows us is that while performance adjustments during a migration may require a fair amount of knowledge, they can lead to far better results. In many cases, the amount of I/O can be reduced drastically - especially when PostgreSQL replication is added later, we can greatly speed up the loading process.
In the Oracle world, the set of data types used differs quite substantially from what we have on the PostgreSQL side. That means that data type mapping is important for a couple of reasons: first of all, it is a matter of efficiency. Not all data types are created equal. The integer data type is far more efficient than, say, numeric, and boolean is going to be a lot smaller than integer (just to give a few examples). Secondly, it is a matter of what you expect on the target side. When creating tooling, you need to keep in mind that …
A migration is a chance to do cleanup
This is vitally important. Don’t miss the opportunity to clean up legacy messes, remove unneeded stuff or just fix your data structure by using more suitable and more efficient data types.
A lot can be said about the differences between Oracle and PostgreSQL and which nuances should be migrated in what fashion. However, this time I wanted to shed some light on the topic from the perspective of a toolmaker, instead of from the standpoint of a person performing the actual migration.
If you want to learn more about the tooling we came up with, consider checking out the CYBERTEC migrator directly:

Hello, my name is Pavlo Golub, and I am a scheduler addict. That began when I implemented pg_timetable for PostgreSQL. I wrote a lot about it. In this post, I want to share the result of my investigations on the schedulers available for PostgreSQL. I gave a talk about this topic at the CERN meetup, so you may want to check it out for more details.
Let's start with the complete comparison table. If you want to know more about each aspect, you'll find further explanations below.
I would like to get comments and suggestions on this table, especially from developers or users of these products. I can be biased towards my own creation, so please don't judge me too harshly. 🙂
| FeatureProduct | pg_timetable | pg_cron | pgAgent | jpgAgent | pgbucket |
| Architecture | |||||
|---|---|---|---|---|---|
| Year | 2019 | 2016 | 2008 | 2016 | 2015 |
| Implementation | standalone | bgworker | standalone | standalone | standalone |
| Language | Go | C | C++ | Java | C++ |
| Can operate wo extension | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| Jobs meta stored in | database | database | database | database | file |
| Remote Database Execution | ✔️ | ❌ | ✔️ | ✔️ | ✔️ |
| Cross Platform | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| Functionality | |||||
| SQL tasks | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Program/Shell tasks | ✔️ | ❌ | ✔️ | ✔️ | ✔️ |
| Built-in tasks | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Parallel Jobs | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Parallel Jobs Limit | ✔️ | ❔ | ❔ | ❔ | ✔️ |
| Concurrency protection | ✔️ | ✔️ | ❔ | ❔ | ❔ |
| Task Parameters | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Arbitrary Role | ✔️ | ❌ | ✔️ | ✔️ | ✔️ |
| On Success Task | ✔️ | ❌ | ✔️ | ❔ | ✔️ |
| On Error Task | ✔️ | ❌ | ❌ | ❔ | ✔️ |
| Scheduling | |||||
| Standard Cron | ✔️ | ✔️ | ❌ | ❌ | ✔️ |
| Interval | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| On Reboot | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Start Manually | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| Kill Running Job | ✔️ | ❌ | ❌ | ✔️ | ✔️ |
| Job Timeout | ✔️ | ❌ | ❌ | ✔️ | ❌ |
| Task Timeout | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Disable Job | ✔️ | ❔ | ✔️ | ✔️ | ✔️ |
| Auto Job Disable | ❌ | ❌ | ❌ | ❌ | ✔️ |
| Self-Destructive Jobs | ✔️ | ❌ | ❌ | ❌ | ❔ |
| Logging Levels | |||||
| Job | ✔️ | ❔ | ❔ | ❔ | ❔ |
| Task | ✔️ | ❔ | ❔ | ❔ | ❔ |
| Session | ✔️ | ❔ | ❔ | ❔ | ❔ |
| Logging Destinations | |||||
| stdout/stderr | ✔️ | ❔ | ❔ | ❔ | ❔ |
| file | ✔️ | ❔ | ❔ | ❔ | ❔ |
| database | ✔️ | ❔ | ❔ | ❔ | ❔ |
The first important aspect of each scheduler is its implementation. Either it is a standalone client or a background worker.
A standalone client can be run on any host or platform. The only requirement for such architecture is the ability to connect to the target PostgreSQL server.
On the other hand, background worker implementation requires it to be one of the PostgreSQL processes. That, in turn, means you need to change the shared_preload_libraries configuration parameter and restart the server. But in that case, the scheduler doesn't need to connect to PostgreSQL (it can, though) and can use a unique SPI protocol.
There is no right or wrong choice; each of these choices has pros and cons. The proper solution depends on the user and the environment.
Each of the schedulers heavily relies on a database infrastructure. Specific purpose tables, functions, and views are a common thing. So it's up to the developer to decide how to organize this set of objects in a database. Database extensions are one of the obvious ways of doing so. The difference reveals itself during upgrades: either the user should run ALTER EXTENSION name UPDATE for extension-based deployments, or the scheduler is responsible for updating itself.
Right now, only one of the five schedulers can store jobs and task descriptions from the database: pgbucket can store jobs and tasks in files.
Each database scheduler is, at a minimum, supposed to be able to execute SQL tasks. The ability to run external programs or shell commands is a big plus. For some everyday tasks, e.g., send mail, log, copy table, etc., we've implemented them as productive internal tasks in pg_timetable.
An essential aspect of scheduler operation is the capability
When it comes to execution control, I check if:
This is probably the main criteria by which people evaluate schedulers. cron syntax is the standard, de facto.
Both pgAgent and jpgAgent heavily depend on GUI, and it's impossible to use cron syntax as the input value. The user needs to use checkboxes to specify the required schedule.
Interval values specify if jobs can be executed within a time interval, e.g., every hour, every 15 minutes.
On reboot indicates that jobs will be executed after a scheduler restart, not after a PostgreSQL restart. It's almost impossible to handle server restart adequately, unless the scheduler is implemented as a background worker. In that case, a restart of PostgreSQL means restarting all processes, including the scheduling process.
Sometimes it's good to have the opportunity to start a job manually, for example, for debugging purposes or during maintenance windows. The same applies to the ability to stop a frozen or long-running job.
Job and task timeouts allow you to terminate long-running processes automatically.
When using PostgreSQL schedulers, we are interested in:
In this part, we check what, how detailed and where PostgreSQL schedulers can:
I would like to see more PostgreSQL schedulers available! Let me know if you have any suggestions or fixes, and I will update this table with the new info.
I want to remind you that pg_timetable is a community project. So, please, don't hesitate to ask any questions, to report bugs, to star pg_timetable project, and to tell the world about it.
In conclusion, I wish you all the best! ♥️
Please, stay safe - so we can meet in person at one of the conferences, meetups, or training sessions!
Over the years, many of our PostgreSQL clients have asked whether it makes sense to create indexes before - or after - importing data. Does it make sense to disable indexes when bulk loading data, or is it better to keep them enabled? This is an important question for people involved in data warehousing and large-scale data ingestion. So let’s dig in and figure it out:
Before we dive into the difference in performance, we need to take a look at how B-trees in PostgreSQL are actually structured:
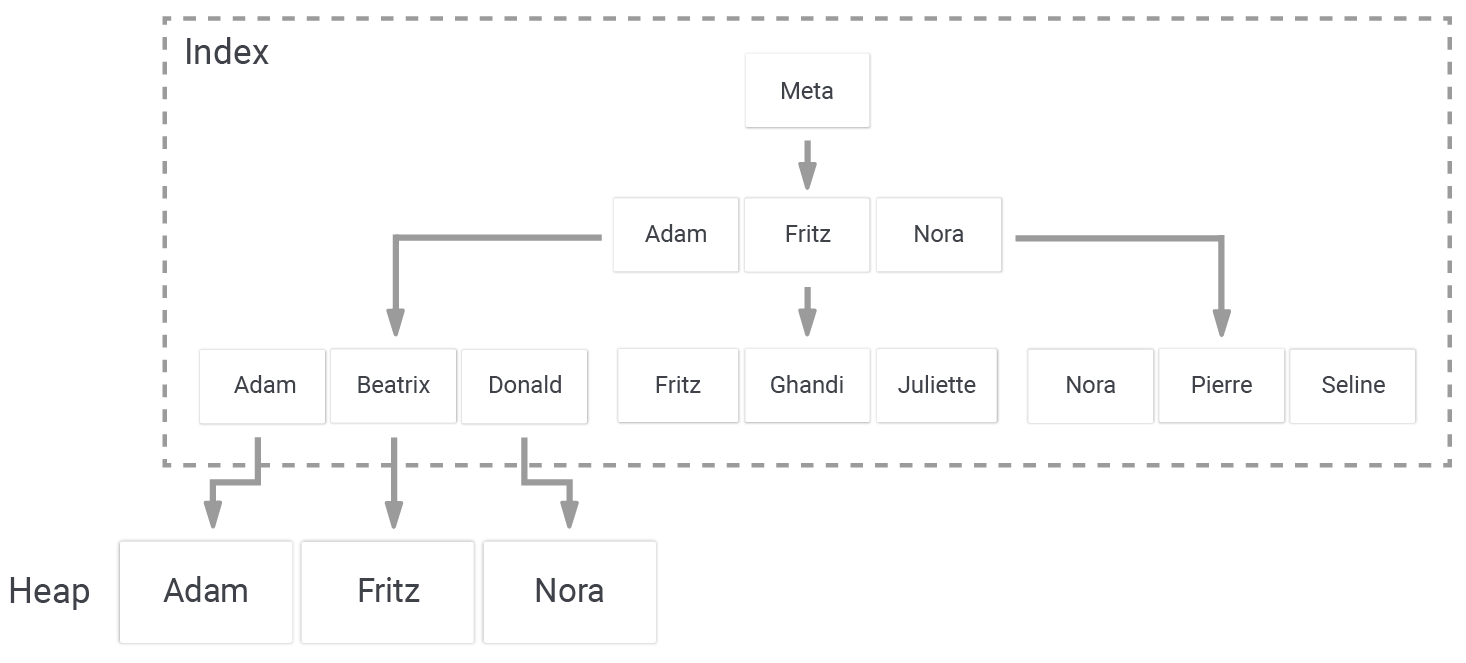
An index points to pages in the heap (= “table”). In PostgreSQL, a B-tree index always contains at least as much data as the underlying table. Inserting content into the table also means that data has to be added to the B-tree structure, which can easily turn a single change into a more expensive process. Keep in mind that this happens for each row (unless you are using partial indexes).
In reality, the additional data can pile up, resulting in a really expensive operation.
To show the difference between indexing after an import and before an import, I have created a simple test on my old Mac OS X machine. However, one can expect to see similar results on almost all other operating systems, including Linux.
Here are some results:
|
1 2 3 4 5 6 7 8 9 |
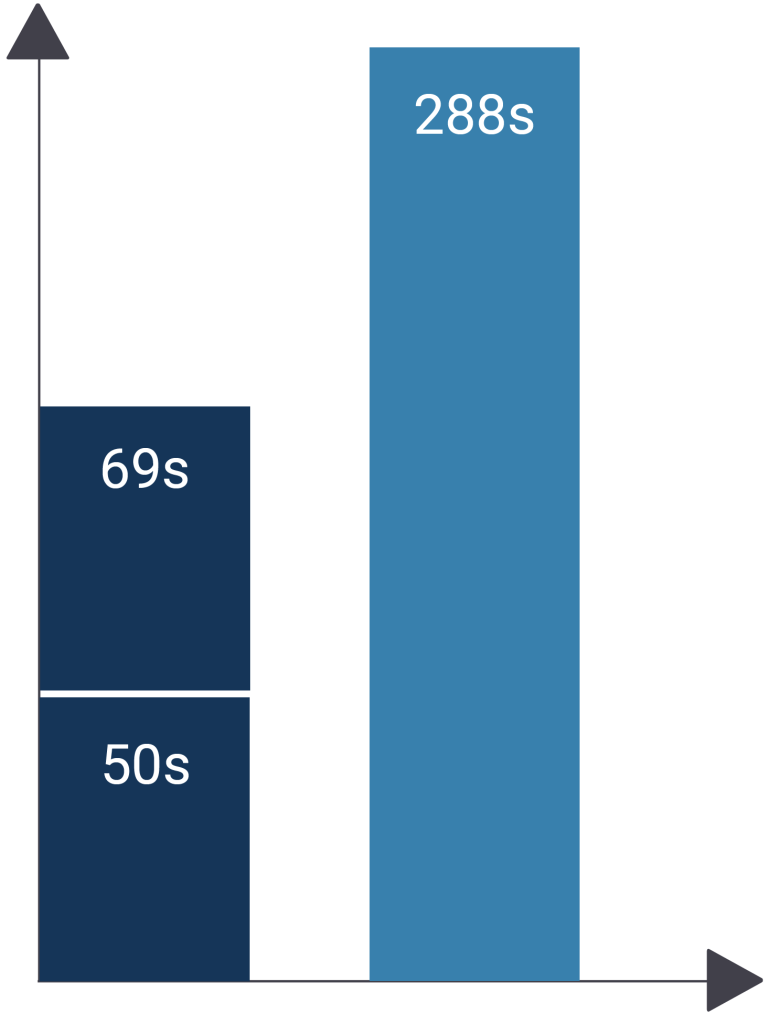
test=# CREATE TABLE t_test (id int, x numeric); CREATE TABLE test=# INSERT INTO t_test SELECT *, random() FROM generate_series(1, 10000000); INSERT 0 10000000 Time: 50249.299 ms (00:50.249) test=# CREATE INDEX idx_test_x ON t_test (x); CREATE INDEX Time: 68710.372 ms (01:08.710) |
As you can see, we need roughly 2 minutes and 50 seconds to load the data, and a little more than one minute to create the index.
But what happens if we drop the table, and create the index before loading the data?
|
1 2 3 4 5 6 7 8 9 |
test=# CREATE TABLE t_test (id int, x numeric); CREATE TABLE test=# CREATE INDEX idx_test_x ON t_test (x); CREATE INDEX Time: 11.192 ms test=# INSERT INTO t_test SELECT *, random() FROM generate_series(1, 10000000); INSERT 0 10000000 Time: 288630.970 ms (04:48.631) |
Wow, the runtime has skyrocketed to close to 5 minutes! The overhead of the additional index is relevant.
The situation can become even worse if there is more than just one index.
In general, our recommendation is therefore:
Create indexes after bulk loading!
The natural question which then arises is: What should I do if there is already data in a table, and even more data is added? In most cases, there is no other way to deal with it but to take on the overhead of the existing indexes, because in most cases, you can’t live without indexes if there is already data in the database.
A second option is to consider PostgreSQL partitioning. If you load data on a monthly basis, it might make sense to create a partition for each month, and attach it after the loading process.
In general, adding to existing data is way more critical, and not so straightforward, as creating data from scratch.
Bulk loading is an important topic and everybody has to load large amounts of data once in a while.
However, bulk loading and indexes are not the only important issues. Docker is also a growing technology that has found many friends around the world. If you want to figure out how to best run PostgreSQL in a container, check out our article about this topic.

PostgreSQL v12 brought more efficient storage for indexes, and v13 improved that even more by adding deduplication of index entries. But Peter Geoghegan wasn't finished! PostgreSQL v14 added “bottom-up” index entry deletion, which targets reducing unnecessary page splits, index bloat and fragmentation of heavily updated indexes.
In a B-tree index, there is an index entry for every row version (“tuple”) in the table that is not dead (invisible to everybody). When VACUUM removes dead tuples, it also has to delete the corresponding index entries. Just like with tables, that creates empty space in an index page. Such space can be reused, but if no new entries are added to the page, the space remains empty.
This “bloat” is unavoidable and normal to some extent, but if it gets to be too much, the index will become less efficient:
This is particularly likely to happen if you update the same row frequently. Until VACUUM can clean up old tuples, the table and the index will contain many versions of the same row. This is particularly unpleasant if an index page fills up: then PostgreSQL will “split” the index page in two. This is an expensive operation, and after VACUUM is done cleaning up, we end up with two bloated pages instead of a single one.
The creation of HOT tuples is perhaps the strongest weapon PostgreSQL has to combat unnecessary churn in the index. With this feature, an UPDATE creates tuples that are not referenced from an index, but only from the previous version of the table row. That way, there is no need to write a new index entry at all, which is good for performance and completely avoids index bloat.
Read more in my article about HOT updates.
When an index scan encounters an entry that points to a dead tuple in the table, it will mark the index entry as “killed”. Subsequent index scans will skip such entries even before VACUUM can remove them. Moreover, PostgreSQL can delete such entries when the index page is full, to avoid a page split.
See my article on killed index tuples for details.
“Bottom-up index tuple deletion” goes farther than the previous approaches: it deletes index entries that point to dead tuples right before an index page split is about to occur. This can reduce the number of index entries and avoid the expensive page split, together with the bloat that will occur later, when VACUUM cleans up.
In a way, this performs part of the work of VACUUM earlier, at a point where it is useful to avoid index bloat.
To demonstrate the effects of the new feature, I performed a custom pgbench run on PostgreSQL v13 and v14.
This is the table for the test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE testtab ( id bigint CONSTRAINT testtab_pkey PRIMARY KEY, unchanged integer, changed integer ); INSERT INTO testtab SELECT i, i, 0 FROM generate_series(1, 10000) AS i; CREATE INDEX testtab_unchanged_idx ON testtab (unchanged); CREATE INDEX testtab_changed_idx ON testtab (changed); |
This is the pgbench script called “bench.sql”:
|
1 2 3 4 5 6 7 8 9 10 11 |
set id random_gaussian(1, 10000, 10) UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; UPDATE testtab SET changed = changed + 1 WHERE id = :id; |
I chose a normal distribution, because in real life there are usually some (recent?) table rows that receive more updates than others. The row is updated ten times, in order to make it more likely that the affected page will have to be split.
I run the script 60000 times (10000 iterations by 6 clients) as follows:
|
1 |
pgbench -n -c 6 -f bench.sql -t 10000 test |
We use the pgstattuple extension to get index statistics with psql:
|
1 2 3 4 5 6 |
SELECT i.indexrelid::regclass AS index, s.index_size, s.avg_leaf_density FROM pg_index AS i CROSS JOIN LATERAL pgstatindex(i.indexrelid) AS s WHERE indrelid = 'testtab'::regclass; |
This is what we get for v13:
|
1 2 3 4 5 6 |
index │ index_size │ avg_leaf_density ═══════════════════════╪════════════╪══════════════════ testtab_pkey │ 319488 │ 66.6 testtab_unchanged_idx │ 4022272 │ 5.33 testtab_changed_idx │ 4505600 │ 13.57 (3 rows) |
For v14, the result is:
|
1 2 3 4 5 6 |
index │ index_size │ avg_leaf_density ═══════════════════════╪════════════╪══════════════════ testtab_pkey │ 245760 │ 87.91 testtab_unchanged_idx │ 532480 │ 39.23 testtab_changed_idx │ 4038656 │ 14.23 (3 rows) |
We see the biggest improvement in testtab_unchanged_idx. In v13, the index is bloated out of shape, while in v14 it only has 60% bloat (which is not bad for an index). Here we see the biggest effect of the new feature. The UPDATE doesn't scan that index, so there are no killed index tuples, and still “bottom-up deletion” could remove enough of them to avoid a page split in most cases.
There is also a measurable improvement in testtab_pkey. Since the UPDATE scans that index, dead index tuples will be killed, and the new feature removes those before splitting the page. The difference to v13 is less pronounced here, since v13 already avoids index bloat quite well.
The index testtab_changed_idx cannot benefit from the new feature, since that only addresses the case where the UPDATE doesn't modify the indexed value. In case you wonder why the leaf density is so much lower compared to testtab_unchanged_idx in v13: that is index de-duplication, which can kick in because the index entry is not modified.
pg_upgrade?The storage format of the index is unchanged, so this will automatically work after a pg_upgrade of an index created on PostgreSQL v12 or later. If the index was created with an earlier version of PostgreSQL, you will have to REINDEX the index to benefit from the new feature. Remember that pg_upgrade simply copies the index files and does not update the internal index version.
PostgreSQL v14 continues to bring improvements to B-tree indexes. While this particular one may not be revolutionary, it promises to provide a solid improvement for many workloads, especially those with lots of updates.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
Last time, we installed PostGIS on top of PostgreSQL. Today, I will complement this article by describing how to upgrade PostGIS on Ubuntu. A detailed description can be found at postgis.net and should be referred to in parallel.
An artificial customer wants his PostGIS-enabled PostgreSQL 13 cluster running on Ubuntu 20.04.02 to be upgraded. The current PostGIS extension states version 2.5 and should be upgraded to its latest version. At the customer site, one spatial database serving both vector and raster data must be upgraded to its successor.
It should be highlighted here, that PostGIS upgrades can be accomplished in two ways, namely a soft or hard upgrade. A soft upgrade refers to only the binary upgrade of a PostGIS’ extension, a hard upgrade implies dumping and restoring the whole database in a fresh PostGIS enabled database. From this description, it would be natural to choose the soft upgrade path by default. Unfortunately, a soft upgrade is not possible all the time, especially when PostGIS objects' internal storage changes. So how do we know which path to follow? Fortunately, PostGIS release notes explicitly state when a hard upgrade is required. Seems we are in luck and a soft upgrade is sufficient for our use case ????. For completeness, the annex contains needed steps to carry out a hard upgrade too.
Now, let's break down this task in the following steps:
Let's start and cross-check statements with reality by listing installed packages on the OS level.
sudo apt list --installed | grep postgresql
From the listing, we realize that PostGIS extension 2.5 has been installed on top of PostgreSQL 13.
postgresql-13-postgis-2.5-scripts/focal-pgdg,now 2.5.5+dfsg-1.pgdg20.04+2 all [installed]
postgresql-13-postgis-2.5/focal-pgdg,now 2.5.5+dfsg-1.pgdg20.04+2 amd64 [installed]
postgresql-13/focal-pgdg,now 13.2-1.pgdg20.04+1 amd64 [installed,automatic]
postgresql-client-13/focal-pgdg,now 13.2-1.pgdg20.04+1 amd64 [installed,automatic]
postgresql-client-common/focal-pgdg,now 225.pgdg20.04+1 all [installed,automatic]
postgresql-common/focal-pgdg,now 225.pgdg20.04+1 all [installed,automatic]
postgresql-contrib/focal-pgdg,now 13+225.pgdg20.04+1 all [installed]
postgresql/focal-pgdg,now 13+225.pgdg20.04+1 all [installed]
It makes sense to extend our test by verifying that our PostGIS extension has been registered correctly within PostgreSQL’s ecosystem. This can be quickly checked on the cluster level by reviewing the related system catalogs or querying pg_available_extensions as a shortcut.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
pdemo=# select * from pg_available_extensions where name like 'postgis%'; name | default_version | installed_version | comment ----------------------------+-----------------+-------------------+--------------------------------------------------------------------- postgis_topology | 2.5.5 | | PostGIS topology spatial types and functions postgis-2.5 | 2.5.5 | | PostGIS geometry, geography, and raster spatial types and functions postgis_tiger_geocoder-2.5 | 2.5.5 | | PostGIS tiger geocoder and reverse geocoder postgis_tiger_geocoder | 2.5.5 | | PostGIS tiger geocoder and reverse geocoder postgis | 2.5.5 | | PostGIS geometry, geography, and raster spatial types and functions postgis_topology-2.5 | 2.5.5 | | PostGIS topology spatial types and functions postgis_sfcgal | 2.5.5 | | PostGIS SFCGAL functions postgis_sfcgal-2.5 | 2.5.5 | | PostGIS SFCGAL functions (8 rows) |
Surprise, surprise - results of our query confirm the availability of PostGIS extension(s) in version 2.5 only. Finally, it is not only interesting to list available extensions on a cluster level but rather explicitly the listing installed extensions on the database level.
dxTo do so, let’s open up a psql session, connect to our database and finally utilize dx to quickly grab the installed extensions.
|
1 2 3 4 5 6 7 8 |
pdemo=# dx List of installed extensions Name | Version | Schema | Description ---------+---------+------------+--------------------------------------------------------------------- plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language postgis | 2.5.5 | public | PostGIS geometry, geography, and raster spatial types and functions (2 rows) |
Additionally, querying postgis_full_version() returns even more detailed information about our PostGIS extension.
|
1 2 3 4 5 6 7 |
pdemo=# select postgis_full_version(); postgis_full_version ---------------------------------------------------------------------------------- POSTGIS='2.5.5' [EXTENSION] PGSQL='130' GEOS='3.8.0-CAPI-1.13.1 ' PROJ='Rel. 6.3.1, February 10th, 2020' GDAL='GDAL 3.0.4, released 2020/01/28' LIBXML='2.9.10' LIBJSON='0.13.1' LIBPROTOBUF='1.3.3' RASTER (1 row) |
I, by the way, recommend using all available mechanisms to assess the status on the cluster and database level to gain a holistic picture of the system.
After assessing our cluster, we can move forward and install the latest PostGIS packages for PostgreSQL 13 on Ubuntu 20.
Let's quickly ensure that the required PostGIS package is accessible by grabbing the available packages utilizing apt-cache search.
|
1 2 3 4 5 6 7 8 |
sudo apt-cache search postgresql-13-postgis postgresql-13-postgis-2.5 - Geographic objects support for PostgreSQL 13 postgresql-13-postgis-2.5-dbgsym - debug symbols for postgresql-13-postgis-2.5 postgresql-13-postgis-2.5-scripts - Geographic objects support for PostgreSQL 13 -- SQL scripts postgresql-13-postgis-3 - Geographic objects support for PostgreSQL 13 postgresql-13-postgis-3-dbgsym - debug symbols for postgresql-13-postgis-3 postgresql-13-postgis-3-scripts - Geographic objects support for PostgreSQL 13 -- SQL scripts |
Seems we are fine and can install the latest PostGIS 3 version as follows:
sudo apt-get install postgresql-13-postgis-3 postgresql-13-postgis-3-scripts
It can't hurt to replay what I mentioned in the beginning: query installed PostgreSQL packages on the OS level (1) and verify packages registration (2) within PostgreSQL.
|
1 |
sudo apt list --installed | grep postgresql<br><br>postgresql-13-postgis-2.5-scripts/focal-pgdg,now 2.5.5+dfsg-1.pgdg20.04+2 all [installed]<br>postgresql-13-postgis-2.5/focal-pgdg,now 2.5.5+dfsg-1.pgdg20.04+2 amd64 [installed]<br>postgresql-13-postgis-3-scripts/focal-pgdg,now 3.1.1+dfsg-1.pgdg20.04+1 all [installed,automatic]<br>postgresql-13-postgis-3/focal-pgdg,now 3.1.1+dfsg-1.pgdg20.04+1 amd64 [installed]<br>postgresql-13/focal-pgdg,now 13.2-1.pgdg20.04+1 amd64 [installed,automatic]<br>postgresql-client-13/focal-pgdg,now 13.2-1.pgdg20.04+1 amd64 [installed,automatic]<br>postgresql-client-common/focal-pgdg,now 225.pgdg20.04+1 all [installed,automatic]<br>postgresql-common/focal-pgdg,now 225.pgdg20.04+1 all [installed,automatic]<br>postgresql-contrib/focal-pgdg,now 13+225.pgdg20.04+1 all [installed]<br>postgresql/focal-pgdg,now 13+225.pgdg20.04+1 all [installed]<br><br> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
pdemo=# select * from pg_available_extensions where name like 'postgis%' and default_version= '3.1.1'; name | default_version | installed_version | comment --------------------------+-----------------+-------------------+------------------------------------------------------------ postgis_topology | 3.1.1 | | PostGIS topology spatial types and functions postgis_tiger_geocoder-3 | 3.1.1 | | PostGIS tiger geocoder and reverse geocoder postgis_raster | 3.1.1 | | PostGIS raster types and functions postgis_tiger_geocoder | 3.1.1 | | PostGIS tiger geocoder and reverse geocoder postgis_raster-3 | 3.1.1 | | PostGIS raster types and functions postgis | 3.1.1 | 2.5.5 | PostGIS geometry and geography spatial types and functions postgis-3 | 3.1.1 | | PostGIS geometry and geography spatial types and functions postgis_sfcgal | 3.1.1 | | PostGIS SFCGAL functions postgis_topology-3 | 3.1.1 | | PostGIS topology spatial types and functions postgis_sfcgal-3 | 3.1.1 | | PostGIS SFCGAL functions (10 rows) |
As the requirements are fulfilled, we can proceed and upgrade PostGIS within our database. Let’s open up a psql session, connect to our database and call PostGIS_Extensions_Upgrade(). Please note that PostGIS_Extensions_Upgrade() is only available from 2.5 upwards. Upgrading from prior versions imply manual steps (see annex) or upgrading to 2.5 as intermediate version. From version 3 PostGIS separates functionality for vector and raster in different extensions - PostGIS_Extensions_Upgrade() takes care of this fact.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
pdemo=# select postgis_extensions_upgrade(); postgis_extensions_upgrade --------------------------------------------------------------------------------------------- POSTGIS="3.1.1 aaf4c79" [EXTENSION] PGSQL="130" GEOS="3.8.0-CAPI-1.13.1 " PROJ="6.3.1" GDAL="GDAL 3.0.4, released 2020/01/28" LIBXML="2.9.10" LIBJSON="0.13.1" LIBPROTOBUF="1.3.3" WAGYU="0.5.0 (Internal)" RASTER (raster lib from "2.5.5 r0" need upgrade) [UNPACKAGED!] (raster procs from "2.5.5 r0" need upgrade) (1 row) select PostGIS_Extensions_Upgrade(); WARNING: unpackaging raster WARNING: PostGIS Raster functionality has been unpackaged HINT: type `SELECT postgis_extensions_upgrade();` to finish the upgrade. After upgrading, if you want to drop raster, run: DROP EXTENSION postgis_raster; NOTICE: ALTER EXTENSION postgis UPDATE TO "3.1.1"; |
Reading the query result, it seems we are not done and the PostGIS raster extension must be upgraded separately. This should be necessary only when moving from PostGIS version <3 to PostGIS 3. The reason behind this is that raster functionality has been moved to a separate extension named PostGIS_Raster. To upgrade and install PostGIS_Raster, a second call to PostGIS_Extensions_Upgrade() does the trick.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
pdemo=# select postgis_extensions_upgrade(); WARNUNG: unpackaging raster WARNUNG: PostGIS Raster functionality has been unpackaged TIP: type `SELECT postgis_extensions_upgrade();` to finish the upgrade. After upgrading, if you want to drop raster, run: DROP EXTENSION postgis_raster; HINWEIS: ALTER EXTENSION postgis UPDATE TO "3.1.1"; post25=# select postgis_extensions_upgrade(); HINWEIS: Packaging extension postgis_raster WARNUNG: 'postgis.gdal_datapath' is already set and cannot be changed until you reconnect WARNUNG: 'postgis.gdal_enabled_drivers' is already set and cannot be changed until you reconnect WARNUNG: 'postgis.enable_outdb_rasters' is already set and cannot be changed until you reconnect HINWEIS: Extension postgis_sfcgal is not available or not packagable for some reason HINWEIS: Extension postgis_topology is not available or not packagable for some reason HINWEIS: Extension postgis_tiger_geocoder is not available or not packagable for some reason postgis_extensions_upgrade ------------------------------------------------------------------- Upgrade completed, run SELECT postgis_full_version(); for details (1 Zeile) |
dx again to see what we achieved.|
1 2 3 4 5 6 7 8 |
pdemo=# dx List of installed extensions Name | Version | Schema | Description ----------------+---------+------------+--------------------------------------------------------------------- plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language postgis | 3.1.1 | public | PostGIS geometry, geography, and raster spatial types and functions postgis_raster | 3.1.1 | public | PostGIS raster types and functions (3 rows) |
Congratulations! You made it here and followed my partially repetitive steps to upgrade your PostGIS installation. It should be stated that depending on the PostGIS version and OS, upgrades can turn out to be tricky and cause headaches and sleepless nights. Do not forget to backup and assess your system comprehensively before initiating an upgrade!
Alter extension postgis update to '3.1.1';
Create extension postgis_raster from unpackaged;
*-From unpackaged removed by PostgreSQL version 13.0, https://www.postgresql.org/docs/release/13.0/
Alter extension postgis update to '2.5.5';
Select PostGIS_Extensions_Upgrade();
*-From unpackaged removed by PostgreSQL version 13.0, https://www.postgresql.org/docs/release/13.0/
1. Create a new database and enable PostGIS
Create database pdemo_new;
c pdemo_new;
Create extension postgis with version '3.1.1';
Create extension postgis_raster with version '3.1.1';
2. Dump and restore database
pg_dump -Fc -b -v -f 'pdemo.backup' pdemo
pg_restore 'pdemo.backup' -d pdemo_new
3. Rename databases
alter database pdemo rename to pdemo_old;
alter database pdemo_new rename to pdemo;
In case you'd like to read more about PostGIS, see my post about upgrading PostGIS-related libraries such as GEOS and GDAL.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
