
Table of Contents
If you thought that the B-tree index is a technology that was perfected in the 1980s, you are mostly right. But there is still room for improvement, so PostgreSQL v12 (in the tradition of v11) has added some new features in this field. Thanks, Peter Geoghegan!
In this article, I want to explain some of these improvements with examples.
To demonstrate the changes, I'll create an example table on both PostgreSQL v11 and v12:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE rel ( aid bigint NOT NULL, bid bigint NOT NULL ); ALTER TABLE rel ADD CONSTRAINT rel_pkey PRIMARY KEY (aid, bid); CREATE INDEX rel_bid_idx ON rel (bid); d rel Table 'public.rel' Column | Type | Collation | Nullable | Default --------+--------+-----------+----------+--------- aid | bigint | | not null | bid | bigint | | not null | Indexes: 'rel_pkey' PRIMARY KEY, btree (aid, bid) 'rel_bid_idx' btree (bid) |
Tables like this are typically used to implement many-to-many relationships between other tables (entities).
The primary key creates a unique composite B-tree index on the table. The table serves two purposes:
aid and bidbids related to a given aidThe second index speeds up searches for all aids related to a given bid.
Now let's insert some rows in ascending numeric order, as is common for artificially generated keys:
|
1 2 3 4 5 6 |
INSERT INTO rel (aid, bid) SELECT i, i / 10000 FROM generate_series(1, 20000000) AS i; /* set hint bits and calculate statistics */ VACUUM (ANALYZE) rel; |
Here each bid is related to 10000 aids.
INSERT into indexes with many duplicatesThe first difference becomes obvious when we compare the size of the index on bid:
|
1 2 3 4 5 6 |
di+ rel_bid_idx List of relations Schema | Name | Type | Owner | Table | Size | Description --------+-------------+-------+----------+-------+--------+------------- public | rel_bid_idx | index | postgres | rel | 545 MB | (1 row) |
|
1 2 3 4 5 6 |
di+ rel_bid_idx Schema | Name | Type | Owner | Table | Size | Description --------+-------------+-------+----------+-------+--------+------------- public | rel_bid_idx | index | postgres | rel | 408 MB | (1 row) |
The index is 33% bigger in v11.
Every bid occurs 10000 times in the index, therefore there will be many leaf pages where all keys are the same (each leaf page can contain a couple of hundred entries).
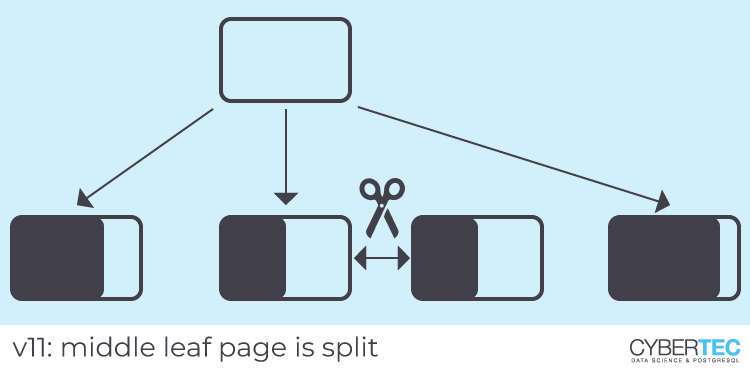
Before v12, PostgreSQL would store such entries in no special order in the index. So if a leaf page had to be split, it was sometimes the rightmost leaf page, but sometimes not. The rightmost leaf page was always split towards the right end to optimize for monotonically increasing inserts. In contrast to this, other leaf pages were split in the middle, which wasted space.
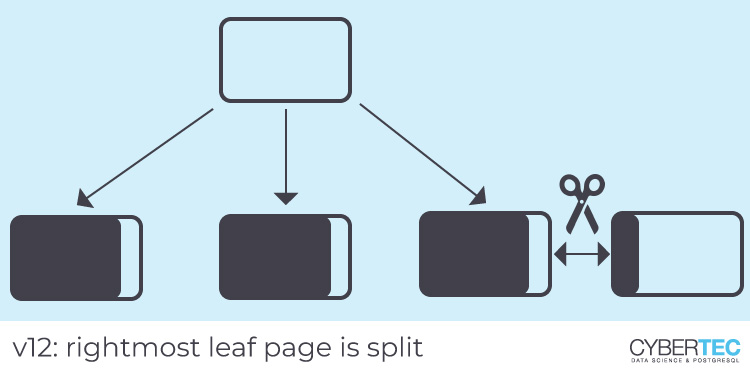
Starting with v12, the physical address (“tuple ID” or TID) of the table row is part of the index key, so duplicate index entries are stored in table order. This will cause index scans for such entries to access the table in physical order, which can be a significant performance benefit, particularly on spinning disks. In other words, the correlation for duplicate index entries will be perfect. Moreover, pages that consist only of duplicates will be split at the right end, resulting in a densely packed index (that is what we observed above).
A similar optimization was added for multi-column indexes, but it does not apply to our primary key index, because the duplicates are not in the first column. The primary key index is densely packed in both v11 and v12, because the first column is monotonically increasing, so leaf page splits occur always at the rightmost page. As mentioned above, PostgreSQL already had an optimization for that.
The improvements for the primary key index are not as obvious, since they are almost equal in size in v11 and v12. We will have to dig deeper here.
First, observe the small difference in an index-only scan in both v11 and v12 (repeat the statement until the blocks are in cache):
|
1 2 3 4 5 6 7 8 9 10 11 |
EXPLAIN (ANALYZE, BUFFERS, COSTS off, SUMMARY off, TIMING off) SELECT aid, bid FROM rel WHERE aid = 420024 AND bid = 42; QUERY PLAN --------------------------------------------------------------- Index Only Scan using rel_pkey on rel (actual rows=1 loops=1) Index Cond: ((aid = 420024) AND (bid = 42)) Heap Fetches: 0 Buffers: shared hit=5 (4 rows) |
|
1 2 3 4 5 6 7 8 9 10 11 |
EXPLAIN (ANALYZE, BUFFERS, COSTS off, SUMMARY off, TIMING off) SELECT aid, bid FROM rel WHERE aid = 420024 AND bid = 42; QUERY PLAN --------------------------------------------------------------- Index Only Scan using rel_pkey on rel (actual rows=1 loops=1) Index Cond: ((aid = 420024) AND (bid = 42)) Heap Fetches: 0 Buffers: shared hit=4 (4 rows) |
In v12, one less (index) block is read, which means that the index has one level less. Since the size of the indexes is almost identical, that must mean that the internal pages can fit more index entries. In v12, the index has a greater fan-out.
As described above, PostgreSQL v12 introduced the TID as part of the index key, which would waste an inordinate amount of space in internal index pages. So the same commit introduced truncation of “redundant” index attributes from internal pages. The TID is redundant, as are non-key attributes from an INCLUDE clause (these were also removed from internal index pages in v11). But PostgreSQL v12 can also truncate those index attributes that are not needed for table row identification.
In our primary key index, bid is a redundant column and is truncated from internal index pages, which saves 8 bytes of space per index entry. Let's have a look at an internal index page with the pageinspect extension:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT * FROM bt_page_items('rel_pkey', 2550); itemoffset | ctid | itemlen | nulls | vars | data ------------+------------+---------+-------+------+------------------------------------------------- 1 | (2667,88) | 24 | f | f | cd 8f 0a 00 00 00 00 00 45 00 00 00 00 00 00 00 2 | (2462,0) | 8 | f | f | 3 | (2463,15) | 24 | f | f | d6 c0 09 00 00 00 00 00 3f 00 00 00 00 00 00 00 4 | (2464,91) | 24 | f | f | db c1 09 00 00 00 00 00 3f 00 00 00 00 00 00 00 5 | (2465,167) | 24 | f | f | e0 c2 09 00 00 00 00 00 3f 00 00 00 00 00 00 00 6 | (2466,58) | 24 | f | f | e5 c3 09 00 00 00 00 00 3f 00 00 00 00 00 00 00 7 | (2467,134) | 24 | f | f | ea c4 09 00 00 00 00 00 40 00 00 00 00 00 00 00 8 | (2468,25) | 24 | f | f | ef c5 09 00 00 00 00 00 40 00 00 00 00 00 00 00 9 | (2469,101) | 24 | f | f | f4 c6 09 00 00 00 00 00 40 00 00 00 00 00 00 00 10 | (2470,177) | 24 | f | f | f9 c7 09 00 00 00 00 00 40 00 00 00 00 00 00 00 ... 205 | (2666,12) | 24 | f | f | c8 8e 0a 00 00 00 00 00 45 00 00 00 00 00 00 00 (205 rows) |
In the data entry we see the bytes from aid and bid. The experiment was conducted on a little-endian machine, so the numbers in row 6 would be 0x09C3E5 and 0x3F or (as decimal numbers) 639973 and 63. Each index entry is 24 bytes wide, of which 8 bytes are the tuple header.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT * FROM bt_page_items('rel_pkey', 2700); itemoffset | ctid | itemlen | nulls | vars | data ------------+----------+---------+-------+------+------------------------- 1 | (2862,1) | 16 | f | f | ab 59 0b 00 00 00 00 00 2 | (2576,0) | 8 | f | f | 3 | (2577,1) | 16 | f | f | 1f 38 0a 00 00 00 00 00 4 | (2578,1) | 16 | f | f | 24 39 0a 00 00 00 00 00 5 | (2579,1) | 16 | f | f | 29 3a 0a 00 00 00 00 00 6 | (2580,1) | 16 | f | f | 2e 3b 0a 00 00 00 00 00 7 | (2581,1) | 16 | f | f | 33 3c 0a 00 00 00 00 00 8 | (2582,1) | 16 | f | f | 38 3d 0a 00 00 00 00 00 9 | (2583,1) | 16 | f | f | 3d 3e 0a 00 00 00 00 00 10 | (2584,1) | 16 | f | f | 42 3f 0a 00 00 00 00 00 ... 286 | (2861,1) | 16 | f | f | a6 58 0b 00 00 00 00 00 (286 rows) |
The data contain only aid, since bid has been truncated away. This reduces the index entry size to 16, so that more entries fit on an index page.
Since index storage has been changed in v12, a new B-tree index version 4 has been introduced.
Since upgrading with pg_upgrade does not change the data files, indexes will still be in version 3 after an upgrade. PostgreSQL v12 can use these indexes, but the above optimizations will not be available. You need to REINDEX an index to upgrade it to version 4 (this has been made easier with REINDEX CONCURRENTLY in PostgreSQL v12).
There were some other improvements added in PostgreSQL v12. I won't discuss them in detail, but here is a list:
REINDEX CONCURRENTLY to make it easier to rebuild an index without down-time.pg_stat_progress_create_index to report progress for CREATE INDEX and REINDEX.B-tree indexes have become smarter again in PostgreSQL v12, particularly for indexes with many duplicate entries. To fully benefit, you either have to upgrade with dump/restore or you have to REINDEX indexes after pg_upgrade.
+43 (0) 2622 93022-0
office@cybertec.at
You are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from X. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information
Hello Laurenz. Thanks for this post !
In the above lists, is ctid equivalent to TID ?
In V12 if the TID is part of the key, itemlen 16 accounts for TID aid
In V11 itemlen is 24 for aid bid: it should rather be 16 ?
Yes,
ctidis the tuple identifier. I don't know whet the “c” stands for.An index entry in v11 also contains the TID (that's there where the index entry points), it just isn't counted as part of the key.
Hi,
Do you have any articles on Hash Index. I only need to do read/select on this index , I read that hash is the way to go.
B Tree is useful if you need it for things like a LIKE statement.
Hash index is useful for equality operators only.
https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
You can choose it when you only perform "= op" on all columns.
I don't remember whether there is a benchmark for hash index though (compared to b-tree)
Search for it 🙂
Think about what they are and you will see you were mislead.
A BTree is an ordered tree. A hash is a mapping from one set to another one.
An example of hash: "iterative sum of digits".
So, if I want to hash 179 -> 17 -> 8
Now, I only need 10 buckets for my index.
Do I have "179" in my table ?
-> Check the buckets 8, then iterate the list of numbers there.
Now, if you want to order by number, your hash will not help you! Indeed, 17 and 161 occupies the same buckets ! 18 and 162 occupies the next buckets !
With BTree that's different, you can go through the tree in prefix order and you get a sorting, in postfix order and you get the reverse sorting.
Need something between two values ? Right in the BTree alley. For a node, everything on the left is smaller (or greater) and everything on the right is greater (or smaller).
The only advantage of Hash is access speed. But that depends on collision.
Create twice the same table and use each index. Try sorting and ">" type of queries.
Bonus: seek Bitmap index!
Bonus2: bloom filters.
There have been no improvements for hash indexes in PostgreSQL v12.
I think that hardly anybody uses them.
The problem is that they were not really usable before v10, and they have not received a lot of love and optimization, unlike B-tree indexes.
Another problem that harms their adoption is that a B-tree index can do everything that a hash index can (and more), except that the hash index *might* be faster in some cases.
If you only have conditions like
WHERE x = 42, you could consider using a hash index. But you should run realistic tests to see if you can measure an improvement over B-tree indexes.