UPDATED August 2023: Autovacuum has been part of PostgreSQL for a long time. But how does it really work? Can you simply turn it on and off? People keep asking us these questions about enabling and disabling autovacuum. PostgreSQL relies on MVCC to handle concurrency in a multiuser environment. The problem which arises with concurrent transactions is that dead tuples must be cleaned up. In PostgreSQL this is handled by the VACUUM command, which we already have covered in some other posts. However, running VACUUM manually is a thing of the past. Most people rely on the PostgreSQL autovacuum daemon to handle cleanup.
Table of Contents
The first thing to understand is that autovacuum really does what it says: basically, it is automation around manual VACUUM. All it does is to sleep for a while and check periodically if a table requires processing. There are three things autovacuum takes care of:
ANALYZE)In PostgreSQL, autovacuum is a server-side daemon which is always there. Yes, that’s right: ALWAYS. Even if you turn autovacuum off in postgresql.conf (or by using ALTER SYSTEM to adjust postgresql.auto.conf), the daemon will still be around - by design - to help with wraparound protection.
The way autovacuum works is: it periodically checks if work has to be done, and notifies the postmaster in case new workers have to be launched to take care of a table. Autovacuum does not launch a worker directly, but works indirectly through the postmaster to make sure that all processes are on one level. The fact that it works through the postmaster clearly helps to make the system more reliable.
Let’s take a closer look at what autovacuum does.
The PostgreSQL optimizer relies heavily on statistics. It estimates the number of rows returned by various operations and tries to guess the best way to optimize a query.
The optimizer uses the statistical distribution of data in a table in order to do that. In case the content of a table changes, the optimizer has to use stale data, which in turn can lead to bad performance.
Therefore autovacuum kicks in on a regular basis to update all the statistics. Autovacuum relies on various configuration parameters (to be found in postgresql.conf) which can be changed to optimize this behavior:
|
1 2 3 4 |
autovacuum_analyze_threshold = 50 # min number of row updates before analyze autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze |
These parameters will tell autovacuum when to create new statistics. In the above case, the rule is as follows:
|
1 2 |
analyze threshold = analyze base threshold + analyze scale factor * number of tuples |
Given the default configuration, autovacuum usually does a good job to maintain statistics automatically. However, sometimes it is necessary to exercise some more precise control:
|
1 2 3 4 5 6 7 8 9 |
test=# CREATE TABLE t_foo (id int) WITH (autovacuum_analyze_scale_factor = 0.05); CREATE TABLE test=# d+ t_foo Table 'public.t_foo' Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- id | integer | | | | plain | | Access method: heap Options: autovacuum_analyze_scale_factor=0.05 |
In this example, I have adjusted autovacuum_analyze_scale_factor to 0.05 to make autovacuum more aggressive. Once in a while, this is necessary - especially if tables are really, really large in size.
Creating fresh optimizer statistics is quite important. However, there’s more: cleaning out dead rows. The purpose of VACUUM in general is to make sure that dead rows are removed from heaps and indexes nicely. We have written extensively about VACUUM and cleanup in the past.
Usually, the default settings are ok. However, just like in the case of ANALYZE, it can make sense to adjust these parameters to make the autovacuum daemon either more aggressive, or to make it behave in a more relaxed way.
Setting autovacuum parameters can either be done globally during table creation (check out postgresql.conf or postgresql.auto.conf), or later on in the process, as shown in the next listing:
|
1 2 3 |
test=# ALTER TABLE t_foo SET (autovacuum_vacuum_scale_factor = 0.4); ALTER TABLE |
In this case, we have changed the scale factor and made autovacuum kick in less frequently.
There is a third thing autovacuum does: it prevents transaction wraparound. If you want to find out more about this topic, you can also check out my article about wraparound protection in PostgreSQL.
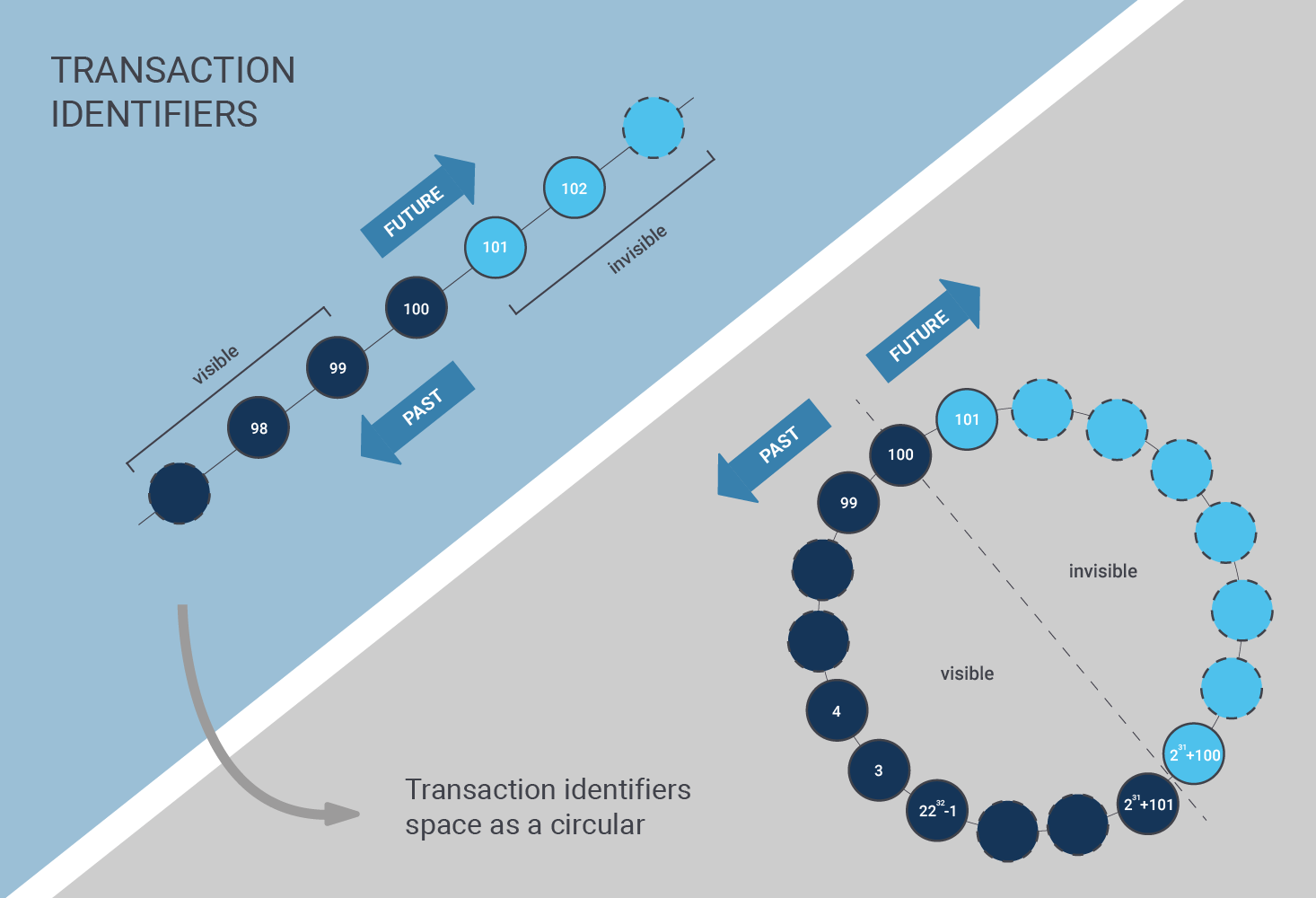
Wraparound protection is an important thing which must not be taken lightly; it can cause serious downtime and cause problems for various workloads.
Autovacuum can be turned off globally. However, this does NOT mean that the daemon stops - it merely means that it ONLY does wraparound protection. The reason why this is done is to make sure that downtime is minimized as much as possible. It’s easier to live with table bloat than with downtime.
Therefore, stopping autovacuum is not really possible - it can only be suspended for the majority of tasks. It is not a good idea to turn off the autovacuum completely, anyway. In most cases, all turning it off does is cause trouble.
What does make sense is to disable autovacuum within special scenarios on individual tables. Here is a scenario in which it might make sense:
UPDATE, DELETE)Why would anybody care about wraparound, cleanup and so on in this case? When it is clear that a table is thrown away anyway, why clean it up? Keep in mind: We're talking about very specific scenarios here, and we're definitely not talking about general-purpose tables.
Here’s how you can turn autovacuum on and off for a single table:
|
1 2 3 4 |
test=# ALTER TABLE t_foo SET (autovacuum_enabled = off); ALTER TABLE test=# ALTER TABLE t_foo SET (autovacuum_enabled = on); ALTER TABLE |
Please understand that turning autovacuum off is certainly not a good idea unless you face a specific use case with a strong justification for doing so.
What happens if the autovacuum is running but somebody starts a manual VACUUM? The general rule is: autovacuum always loses out. If you start a VACUUM but there is already an autovacuum worker running, PostgreSQL will terminate the worker and give your manual process priority.
The same is true for pretty much all other operations. Suppose somebody wants to drop a column, a table, etc. In case of a conflict, PostgreSQL will always kill the autovacuum process and make sure that normal user operations aren't harmed by background operations.
Many people keep asking why autovacuum is slower than manual VACUUM. First of all, in the default configuration, it is indeed true that autovacuum is a lot slower than manual VACUUM. The reason is a thing generally known as cost delay:
|
1 2 3 4 5 |
test=# SHOW autovacuum_vacuum_cost_delay; autovacuum_vacuum_cost_delay ------------------------------ 2ms (1 row) |
When VACUUM hits a table, it usually does so “full speed” which means that cleaning up a table can cause massive I/O bottlenecks. A single VACUUM job can suck hundreds of megabytes of I/O per second - which leaves less capacity for other operations, and can, in turn, lead to bad response times.
The solution is to punish autovacuum for I/O and add artificial delays to the process. Processing a table will take longer, but it leads to a lower overall impact on other processes. In older versions of PostgreSQL, the setting was at 20 milliseconds. However, it is set to 2 milliseconds in PostgreSQL 13 and beyond.
The artificial delays (which can be turned off on a per-table basis) are the core reason why end-users observe runtime differences.
If you want to know more about PostgreSQL performance, we also recommend checking out our consulting services. We help you to tune your database and make sure that your servers operate perfectly.
One issue is that autovacuum takes locks that can interfere with periodic maintenance tasks like adding/dropping weekly or monthly partitions to tables, or DML like ALTER TABLE.
We used to run postgres in single-user mode to do these during a maintenance window, but those tables are created with pg_type.typarray=NULL, which causes pg_upgrade to fail. So now we are launching postgres in postmaster mode with TCP/IP disabled, a non-standard UNIX socket directory, autovacuum=off, autovacuum_nap_time=3600 and a separate thread that kills autovacuums as soon as they appear because even with autovacuum=off the XID rollover autovacuums still run. Very clunky.
you forgot the visibility map ...