Our PostgreSQL 24x7 support team recently received a request from one of our customers who was facing a performance problem. The solution to the problem could be found in the way PostgreSQL handles query optimization (specifically, statistics). So I thought it would be nice to share some of this knowledge with my beloved readers. The topic of this post is therefore: What kinds of statistics does PostgreSQL store, and where can they be found? Let’s dive in and find out.
Table of Contents
Before we dig into PostgreSQL optimization and statistics, it makes sense to understand how PostgreSQL runs a query. The typical process works as follows:
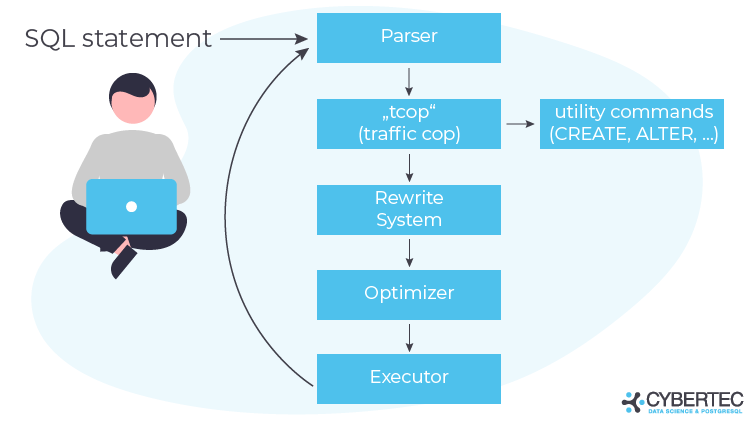
First, PostgreSQL parses the query. Then, the traffic cop separates the utility commands (ALTER, CREATE, DROP, GRANT, etc.) from the rest. After that, the entire thing goes through the rewrite system, which is in charge of handling rules and so on.
Next comes the optimizer - which is supposed to produce the best plan possible. The plan can then be executed by the executor. The main question now is: What does the optimizer do to find the best possible plan? In addition to many mathematical transformations, it uses statistics to estimate the number of rows involved in a query. Let’s take a look and see:
|
1 2 3 4 5 6 7 8 |
test=# CREATE TABLE t_test AS SELECT *, 'hans'::text AS name FROM generate_series(1, 1000000) AS id; SELECT 1000000 test=# ALTER TABLE t_test ALTER COLUMN id SET STATISTICS 10; ALTER TABLE test=# ANALYZE; ANALYZE |
I have created 1 million rows and told the system to calculate statistics for this data. To make things fit onto my website, I also told PostgreSQL to reduce the precision of the statistics. By default, the statistics target is 100. However, I decided to use 10 here, to make things more readable - but more on that later.
Now let’s run a simple query:
|
1 2 3 4 5 6 |
test=# explain SELECT * FROM t_test WHERE id < 150000; QUERY PLAN --------------------------------------------------------------- Seq Scan on t_test (cost=0.00..17906.00 rows=145969 width=9) Filter: (id < 150000) (2 rows) |
What we see here is that PostgreSQL expected 145.000 rows to be returned by the sequential scan. This information is highly important because if the system knows what to expect, it can adjust its strategy accordingly (index, no index, etc.). In my case there are only two choices:
|
1 2 3 |
test=# explain SELECT * FROM t_test WHERE id < 1; QUERY PLAN --------------------------------------------------------------- Gather (cost=1000.00..11714.33 rows=1000 width=9) Workers Planned: 2 -> Parallel Seq Scan on t_test (cost=0.00..10614.33 rows=417 width=9) Filter: (id < 1) (4 rows) |
All I did was to change the number in the WHERE-clause and all of a sudden, the plan has changed. The first query expected a fairly big result set; therefore it was not useful to fire up parallelism, because collecting all those rows in the gather node would have been too expensive. In the second example, the seq scan rarely yields rows - so a parallel query makes sense.
To find the best strategy, PostgreSQL relies on statistics to give the optimizer an indication of what to expect. The better the statistics, the better PostgreSQL can optimize the query.
If you want to see which kind of data PostgreSQL uses, you can take a look at pg_stats which is a view that displays statistics to the user. Here is the content of the view:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
test=# d pg_stats View 'pg_catalog.pg_stats' Column | Type | Collation | Nullable | Default ------------------------+----------+-----------+----------+--------- schemaname | name | | | tablename | name | | | attname | name | | | inherited | boolean | | | null_frac | real | | | avg_width | integer | | | n_distinct | real | | | most_common_vals | anyarray | | | most_common_freqs | real[] | | | histogram_bounds | anyarray | | | correlation | real | | | most_common_elems | anyarray | | | most_common_elem_freqs | real[] | | | elem_count_histogram | real[] | | | |
Let's go through this step-by-step and dissect what kind of data the planner can use:
WHERE col IS NULL” or “WHERE col IS NOT NULL”Finally, there are some entries related to arrays - but let’s not worry about those for the moment. Rather, let’s take a look at some sample content:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
test=# x Expanded display is on. test=# SELECT * FROM pg_stats WHERE tablename = 't_test'; -[ RECORD 1 ]----------+--------------------------------------------------------------------------- schemaname | public tablename | t_test attname | id inherited | f null_frac | 0 avg_width | 4 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds | {47,102906,205351,301006,402747,503156,603102,700866,802387,901069,999982} correlation | 1 most_common_elems | most_common_elem_freqs | elem_count_histogram | -[ RECORD 2 ]----------+--------------------------------------------------------------------------- schemaname | public tablename | t_test attname | name inherited | f null_frac | 0 avg_width | 5 n_distinct | 1 most_common_vals | {hans} most_common_freqs | {1} histogram_bounds | correlation | 1 most_common_elems | most_common_elem_freqs | elem_count_histogram | |
In this listing, you can see what PostgreSQL knows about our table. In the “id” column, the histogram part is most important: “{47,102906,205351,301006,402747,503156,603102,700866,802387,901069,999982}”. PostgreSQL thinks that the smallest value is 47. 10% are smaller than 102906, 20% are expected to be smaller than 205351, and so on. What is also interesting here is the n_distinct: -1 basically means that all values are different. This is important if you are using GROUP BY. In the case of GROUP BY the optimizer wants to know how many groups to expect. n_distinct is used in many cases to provide us with that estimate.
In the case of the “name” column we can see that “hans” is the most frequent value (100%). That’s why we don’t get a histogram.
Of course, there is a lot more to say about how the PostgreSQL optimizer operates. However, to start out with, it is very useful to have a basic understanding of the way Postgres uses statistics.
In general, PostgreSQL generates statistics pretty much automatically. The autovacuum daemon takes care that statistics are updated on a regular basis. Statistics are the fuel needed to optimize queries properly. That’s why they are super important.
If you want to create statistics manually, you can always run ANALYZE. However, in most use cases, autovacuum is just fine.
If you want to learn more about query optimization in general you might want to check out my blog post about GROUP BY. It contains some valuable tips to run analytical queries faster.
Also, If you have any comments, feel free to share them in the Disqus section below. If there are any topics you are especially interested in, feel free to share them as well. We can certainly cover them in future articles.
+43 (0) 2622 93022-0
office@cybertec.at
You are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from X. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information