Are you running PostgreSQL databases or plan to do so? Have you thought about disaster recovery? What happens if your database crashes or - more likely - the (virtual) server it runs on stops working? The best option is probably a copy of your database, that is able to take over operations, as soon as something goes wrong. This concept is commonly referred to as high availability.
Table of Contents
Let’s talk about some general concepts that everyone should know about highly available PostgreSQL clusters. This post will first introduce the concept of replication and show which types of replication can be used with PostgreSQL. As the configuration of replication can be quite complicated, I will further discuss how many challenges can be overcome by using an application called Patroni.
A replica is a secondary copy of your data (the primary copy), i.e. of your databases. In the event of a failure, it is possible to continue business operations on the replica. During normal operations, both the primary and the secondary copy can be read from to boost performance.
As your data changes all the time, it is seldomly sufficient to create only a snapshot in time; You'd probably want a mechanism that keeps your replica up to date. This process is called replication, whereby the replica is periodically informed of any updates to the original data and applies them to the copy.
In the context of (PostgreSQL) databases, the database cluster that you're copying is called the primary, or sometimes leader. The copy of your database cluster is usually referred to by the name replica. You'll also often find the names "master" for the former and "slave" for the latter in some literature, but due to the negative connotation that these words carry, we dislike using them. Instead, primary and standby are the used terms.
Creation of a replica in PostgreSQL is very simple. Shut down your database in a controlled manner (so that it creates a checkpoint), copy the data directory to the device where you want to run your replica, start the primary and the replica as usual.
But if you want to be able to continually update your replica with all modifications that occur on the primary, you will need a replication mechanism as described above.
There are a couple of possible replication mechanisms for PostgreSQL.
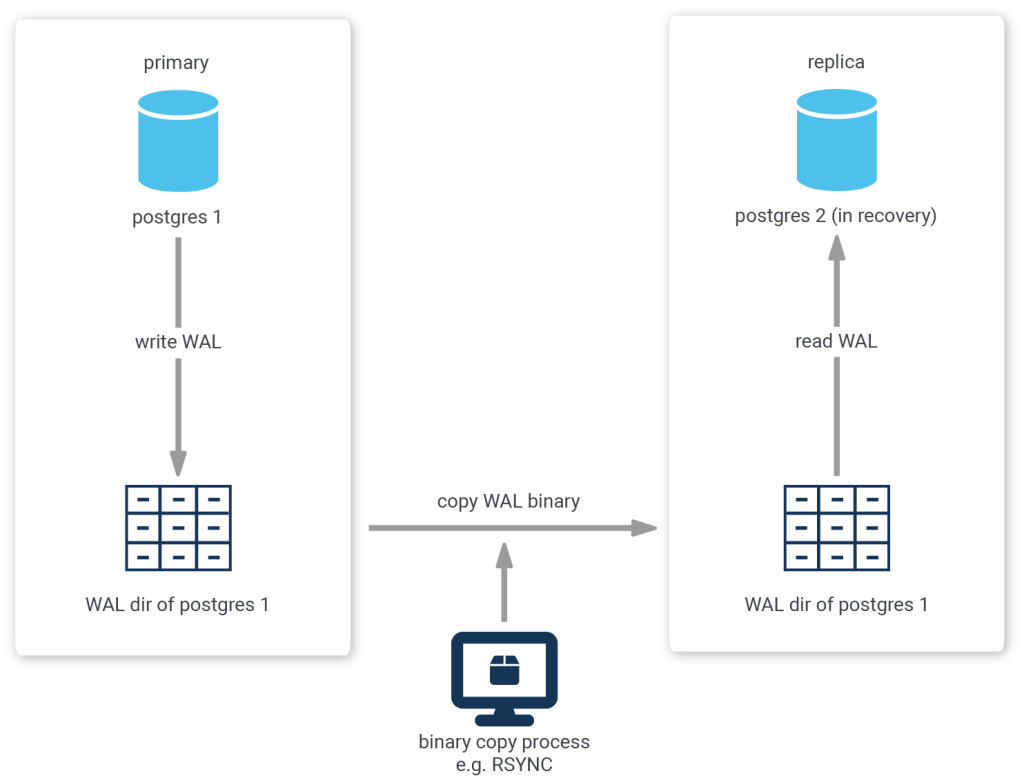
Because PostgreSQL uses a transaction log to enable replay or reversal of transactions, you could continually copy the contents of the transaction log (located in the pg_wal or pg_xlog directory) as it is produced by the primary server to the replica, where you configure the replica to replay any new transaction log files that are copied to it's own pg_wal or pg_xlog directory.
The biggest disadvantage to this method is the fact that transaction log is contained in chunks of usually 16MB. So, if you were to wait for the primary to switch to the next chunk before copying the finished one, your replica would always be 16MB worth of log delayed.
One less obvious disadvantage of this method is the fact that the copying is usually done by a third-party process, i.e. PostgreSQL is not aware of this process. Thus, it is impossible to tell the primary to delay the acceptance or rejection of a commit request until the replica has confirmed that it has copied all prior transaction log messages.
While this method is useful for scenarios where the Recovery Point Objective (RPO, i.e. the time span within which transactions may be lost after recovery) or the Recovery Time Objective (RTO, i.e. the time it takes from failure to successful recovery) are quite large, it is not sufficient for some high-availability requirements, which sometimes require an RPO of zero and RTO in the range of a couple seconds only.
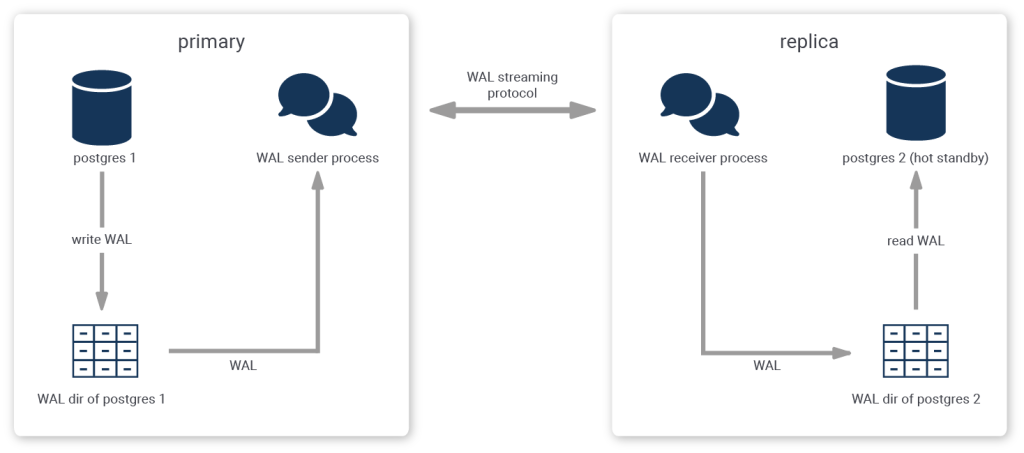
Another approach that is more sophisticated is called streaming replication.
When using streaming replication, single transaction log messages are reproduced to the replica and synchronicity requirements can be handled on a per-message basis.
Streaming replication needs more setup - usually this involves creating a replication user and initiating the replication stream - but this pays off in terms of the recovery objectives.
When streaming replication is employed with the additional requirement of synchronicity, the replica must confirm that it has received (and written) all prior log messages before the primary can confirm or reject a client's commit request. As a result, after a failure on the primary, the replica can instantly be promoted and business can carry on as usual after all connections have been diverted to the replica.
Patroni is a tool that can be used to create, manage, maintain and monitor highly available PostgreSQL cluster setups using streaming replication.
Patroni is distributed under the MIT license and can be easily installed via PIP. For Ubuntu and Debian, it is obtainable via the system repositories and for Fedora, CentOS, or RHEL, RPM packages are provided by CYBERTEC.
Basically, everything you need to run highly available PostgreSQL clusters!
Patroni creates the cluster, initiates streaming replication, handles synchronicity requirements, monitors liveliness of primary and replica, can change the configuration of all cluster members, issues reload commands and restarts selected cluster members, handles planned switchovers and unplanned failovers, rewinds a failed primary to bring it back in line and reinitiates all replication connections to point to the newly promoted primary.
Patroni is engineered to be very fault tolerant and stable; By design, split-brain scenarios are avoided. Split-brain occurs when two members of the same cluster accept writing statements.
It guarantees that certain conditions are always fulfilled and despite the automation of so many complex tasks, it shouldn't corrupt the database cluster nor end in a situation where recovery is impossible.
For example, Patroni can be told never to promote a replica that is lagging behind the primary by more than a configurable amount of log.
It also fulfils several additional requirements; for example, certain replicas should never be considered for promotion if they exist only for the purpose of archiving or data lake applications and not business operations.
The architecture of Patroni is such that every PostgreSQL instance is accompanied by a designated Patroni instance that monitors and controls it.
All of the data that Patroni collects is mirrored in a distributed key-value store, and based on the information present in the store, all Patroni instances agree on decisions, such as which replica to promote if the primary has failed.
The distributed key-value store, for example etcd or consul, enables atomic manipulation of keys and values. This forwards the difficult problem of cluster consensus (which is critical to avoid the split-brain scenario) to battle tested components, proven to work correctly even under the worst circumstances.
Some of the data collected by Patroni is also exhibited through a ReST interface, which can be useful for monitoring purposes as well as for applications to select which PostgreSQL instance to connect to.
Adding a replica to your PostgreSQL cluster can both improve availability and performance. While the configuration of replication is not an easy task (due to the obvious complexity involved with rather sophisticated streaming replication), a solution exists that avoids many pitfalls and enables simple configuration, while also catering to extraordinary demands: Patroni.
This post is part of a series. Apart from this brief introduction, the series covers:
Very very helpful. Thank you for informing our community!
I would like to draw your attention to the automatic deployment tool:
https://github.com/vitabaks/postgresql_cluster
I would be grateful if you test it and recommend for use. Perhaps your team would like to join the further development of this tool.
It tool was written specifically for the Postgres community. MIT License.
Hey!
thanks for letting me know about your project! While we have our own ansible playbooks for installing, creating and managing patroni clusters, we do not have plans to make it public at the moment.
I will look into it, I may give it a try at some point.
Are you coming to pgconf.eu in Milan? Maybe we can have a chat there.
Are you sure you're a junior dev. Your article is awesome.
No, I'm not sure about that 🙂 I might need to update my author profile at some point, but it feels wrong simply to declare myself "senior"...
I'm glad you liked the article!
Hi Julian, Could you please suggest whether one patroni instance can support 2 postgres HA cluster. The design to support in my case is that i have 2 nodes patroni-postgres HA cluster with 3 node etcd as dcs and that is working fine. Now I have another 2 nodes postgres and i wanted to manage it using existing patroni and etcd instances. will this type of design feasible? any suc example or link will be a great help
You may use the same etcd cluster, but you will need one more patroni intance
Correct!
Just make sure that you use a different "scope" in patroni.yml, which is essentially the name of the patroni cluster. Each patroni cluster needs to have a unique name. But of course, members of one cluster need to have the same cluster name.
One etcd cluster can easily support a few dozen patroni clusters, probably a lot more actually - running patroni clusters is not very demanding for etcd. But please check etcd logs as soon as you start launching several dozens of patroni clusters to be sure 😀
Have a nice weekend!
thanks Pavlo.
Hi, how does Patroni compare to Slony? What are the advantages/disadvantages?
Well, Patroni is controlling streaming replication, while Slony is trigger based replication that basically does not deal with HA. Simply said, in trigger based replication, one needs to install triggers on master, and every insert/update/delete gets replicated, while on streaming replication (that comes from version 9.0 on) replication is happening on lower level, on write ahead log (wal). That means, user does not need to take care about that what and how is replicated. In addition, Patroni takes care of HA, automatic failover, recovery and so on. So multiple advantages.
thanks so much for simplifying postgres replication. I have been using streaming replication and remgr for HA. I just got a new job and my environment is using patroni cluster for HA. I have been reading about Patroni but you have share in a simple language that has facilitate my understanding. Thanks for the blog
I'm happy to be able to help you in such a way.
Good luck with your new job!
Hi julian, can you provide me steps on how to install patroni in our existing master-standby replication environmnent, i want to use Patroni to minimize our RPO. Im using pgbackrest as our backup tool. (Postgresql-12/centos7). Is it possible to install Patroni for existing master-standby setup? Thanks. My email is cenon_roxas@yahoo.com.
@Julian : do you aware of any open source DB Monitoring tools build on top of Patroni ?
pgwatch2 can do some basic monotirong of patroni clusters