etcd is one of several solutions to a problem that is faced by many programs that run in a distributed fashion on a set of hosts, each of which may fail or need rebooting at any moment.
Table of Contents
One such program is Patroni; I've already written an introduction to it as well as a guide on how to set up a highly-available PostgreSQL cluster using Patroni.
In that guide, I briefly touched on the reason why Patroni needs a tool like etcd.
Here's a quick recap:
The challenge now lies in providing a mechanism that makes sure that only a single Patroni instance can be successful in acquiring said lock.
In conventional, not distributed, computing systems, this condition would be guarded by a device which enables mutual exclusion, aka. a mutex. A mutex is a software solution that helps make sure that a given variable can only be manipulated by a single program at any given time.
For distributed systems, implementing such a mutex is more challenging:
The programs that contend for the variable need to send their request for change and then a decision has to be inferred somewhere as to whether this request can be accepted or not. Depending upon the outcome of this decision, the request is answered by a response, indicating "success" or "failure". However, because each of the hosts in your cluster may become available, it would be ill-advised to make this decision-making mechanism a centralized one.
Instead, a tool is needed that provides a distributed decision-making mechanism. Ideally, this tool could also take care of storing the variables that your distributed programs try to change. Such a tool, in general, is called a Distributed Consensus Store (DCS), and it makes sure to provide the needed isolation and atomicity required for changing the variables that it guards in mutual exclusion.
An example of one such tool is etcd, but there are others: consul, cockroach, with probably more to come. Several of them (etcd, consul) base their distributed decisions on the RAFT protocol, which includes a concept of leader election. As long as the members of the RAFT cluster can decide on a leader by voting, the DCS is able to function properly and accept changes to the data, as the leader of the current timeline is the one who decides if a request to change a variable can be accepted or not.
A good explanation and visual example of the RAFT protocol can be found here.
In etcd and consul, requests to change the keys and values can be formed to include conditions, like "only change this variable if it wasn't set to anything before" or "only change this variable if it was set to 42 before".
Patroni uses these requests to make sure that it only sets the leader-lock if it is not currently set, and it also uses it to extend the leader-lock, but only if the leader-lock matches its own member name. Patroni waits for the response by the DCS and then continues its work. For example, if Patroni fails to acquire the leader-lock, it will not promote or initialize the PostgreSQL instance.
On the other hand, should Patroni fail to renew the time to live that is associated with the leader-lock, it will stop the PostgreSQL database in order to demote it, because otherwise, it cannot guarantee that no other member of the cluster will attempt to become a leader after the leader key expired.
One of the steps I described in the last blogpost - the step to deploy a Patroni cluster - sets up an etcd cluster:
|
1 |
etcd > etcd_logfile 2>&1 & |
However, that etcd cluster consists only of a single member.
In this scenario, as long as that single member is alive, it can elect itself to be the leader and thus can accept change requests. That's how our first Patroni cluster was able to function atop of this single etcd member.
But if this etcd instance were to crash, it would mean total loss of the DCS. Shortly after the etcd crash, the Patroni instance controlling the PostgreSQL primary would have to stop said primary, as it would be impossible to extend the time to live of the leader key.
To protect against such scenarios, wherein a single etcd failure or planned maintenance might disrupt our much desired highly-available PostgreSQL cluster, we need to introduce more members to the etcd cluster.
The number of cluster members that you choose to deploy is the most important consideration for deploying any DCS. There are two primary aspects to consider:
Usually, etcd members don't fail just by chance. So if you take care to avoid load spikes, and storage or memory issues, you'll want to consider at least two cluster members, so you can shut one down for maintenance.
By design, RAFT clusters require an absolute majority for a leader to be elected. This absolute majority depends upon the number of total etcd cluster members, not only those that are available to vote. This means that the number of votes required for a majority does not change when a member becomes unavailable. The number I just told you, two, was only a lower boundary for system stability and maintenance considerations.
In reality, a two member DCS will not work, because once you shut down one member, the other member will fail to get a majority vote for its leader candidacy, as 1 out of 2 is not more than 50%. If we want to be able to selectively shut members down for maintenance, we will have to introduce a third node, which can then partake in the leader election process. Then, there will always be two voters - out of the total three members - to choose a leader; two thirds is more than 50%, so the demands for absolute majority are met.
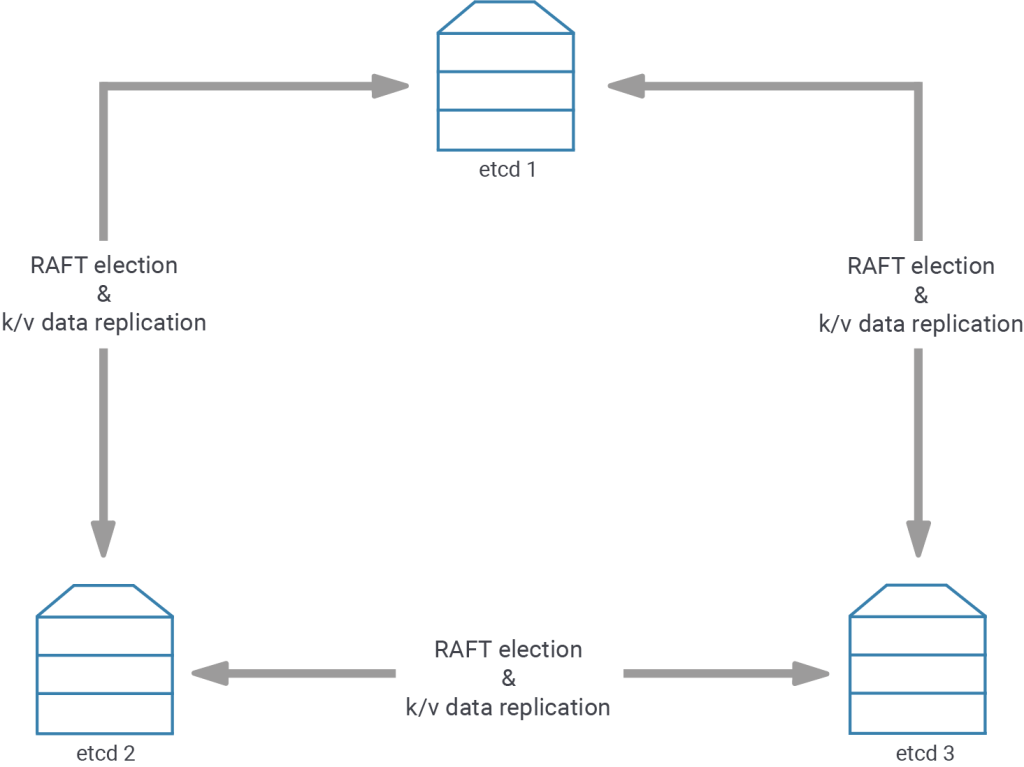
The second most important consideration for etcd cluster deployments is the placement of the etcd nodes. Due to the aforementioned leader key expiry and the need for Patroni to refresh it at the beginning of each loop, and the fact that failure to achieve this will result in a forced stop of the leader, the placement of your etcd cluster members indirectly dictates how Patroni will react to network partitions and to the failure of the minority of nodes.
For starters, the simplest setup only resides in one data center (“completely biased cluster member placement”), so all Patroni and etcd members are not influenced by issues that cut off network access to the outside. At the same time, such a setup deals with the loss of the minority of etcd clusters in a simple way: it does not care - so long as there is still a majority of etcd members left that can talk to each other and to whom Patroni still can talk.
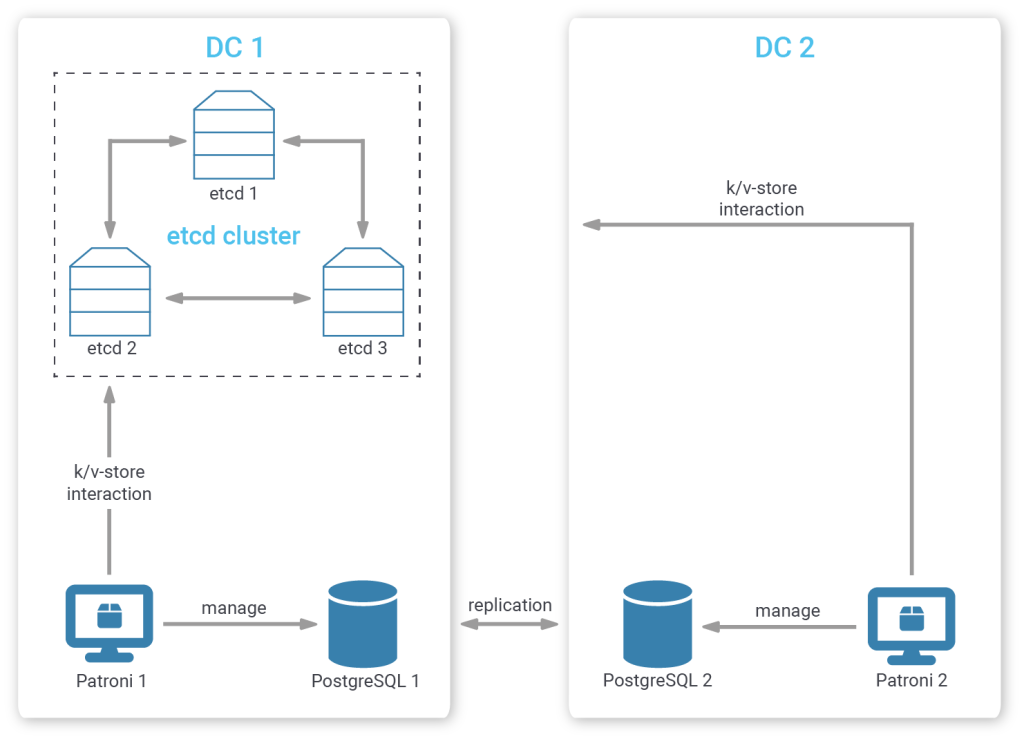
But if you'd prefer a cross-data center setup, where the replicating databases are located in different data centers, etcd member placement becomes critical.
If you've followed along, you will agree that placing all etcd members in your primary data center (“completely biased cluster member placement”) is not wise. Should your primary data center be cut off from the outside world, there will be no etcd left for the Patroni members in the secondary data center to talk to, so even if they were in a healthy state, they could not promote. An alternative would be to place the majority of members in the first data center and a minority in the secondary one (“biased cluster member placement”).
Additionally, if one etcd member in your primary database is stopped - leaving your first data center without a majority of etcd members - and the secondary data center becomes unavailable as well, your database leader in the first data center will be stopped.
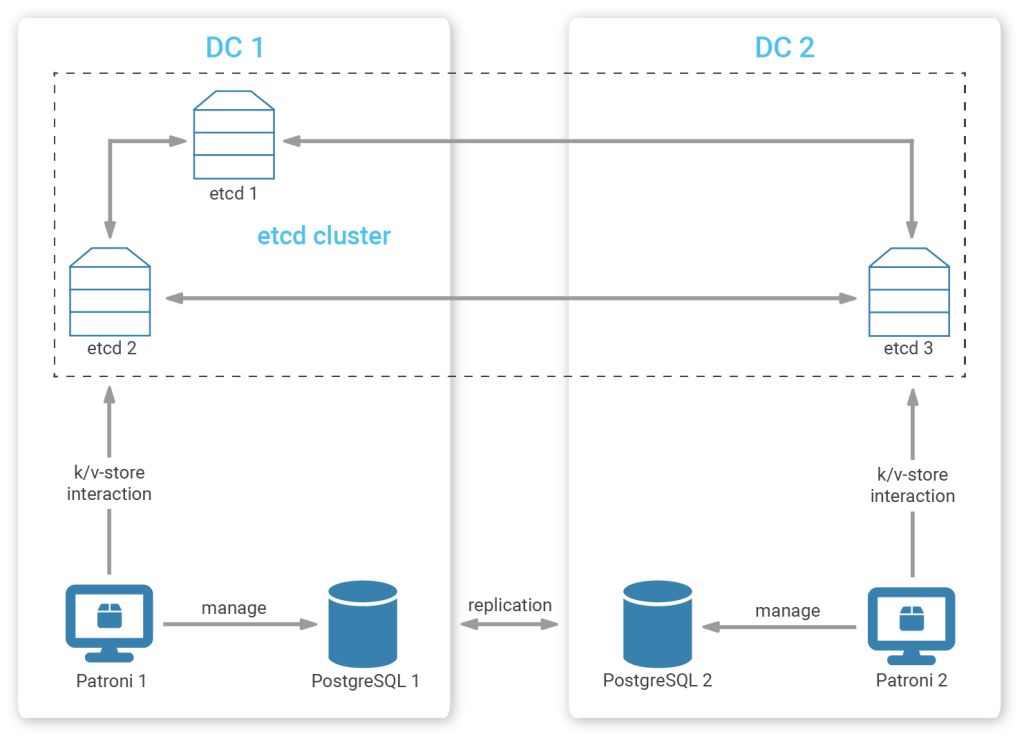
You could certainly manually mitigate this corner case by placing one etcd member in a tertiary position (“tertiary decider placement”), outside of both your first and second data center with a connection to each of them. The two data centers then should contain an equal number of etcd members.
This way, even if either data center becomes unavailable, the remaining data center, together with the tertiary etcd member can still come to a consensus.
Placing one etcd cluster member in a tertiary location can also have the added benefit that its perception of networking partitions might be closer to the way that your customers and applications perceive network partitions.
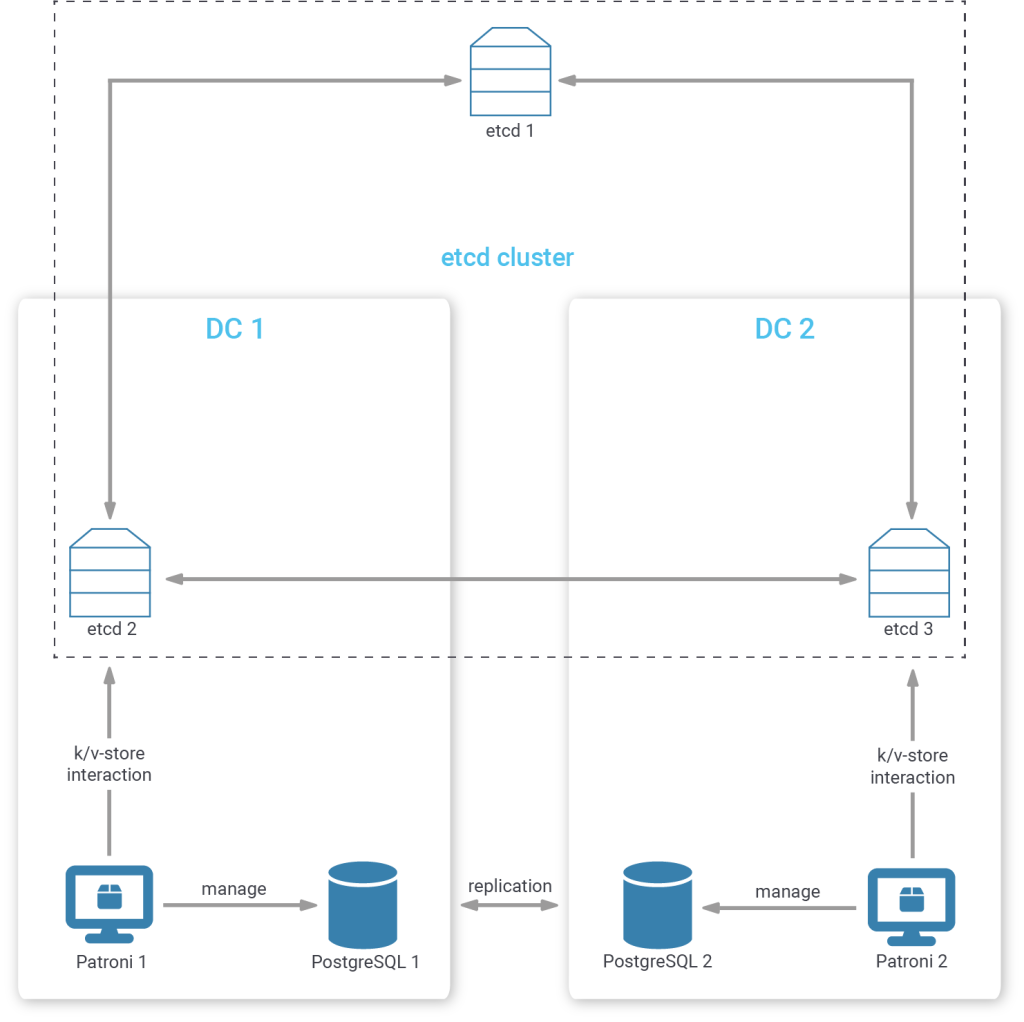
In the biased placement strategies mentioned above, consensus may be reached within a data center that is completely cut off from everything else. Placing one member in the tertiary position means that consensus can only be reached with the members in the data center that still have an intact uplink.
To increase the robustness of such a cluster even more, we can even place more than one node in a tertiary position, to mitigate against failures in a single tertiary member and network issues that could disconnect a single tertiary member.
You see, there are quite a lot of things to consider if you want to create a really robust etcd cluster. The above-mentioned examples are not an exhaustive list, and several other factors could influence your member placement needs. However, our experience has shown that etcd members seldom fail (unless there are disk latency spikes, or cpu-thrashing occurs) and that most customers want a biased solution anyway, as the primary data center is the preferred one. Usually, in biased setups, it is possible to add a new member to the secondary data center and exclude one of the members from the primary data center, in order to move the bias to the second data center. In this way, you can keep running your database even if the first data center becomes completely inaccessible.
With the placement considerations out of the way, let’s look at how to create a simple etcd server. For demonstration purposes, we will constrain this setup to three hosts, 10.88.0.41, 10.88.0.42, 10.88.0.43.
There are a couple of different methods to configure and start (“bootstrap”) etcd clusters; I will outline two of them:
Since etcd uses two different communication channels - one for peer communication with other etcd cluster members, another for client communication with users and applications - some of the configuration parameters may look almost identical, but they are nevertheless essential.
Each etcd member needs the following:
The above parameters are required for each etcd member and they should be different for all etcd members, as they should all have different addresses -- or, at least, different ports.
For the static bootstrap method, all etcd members additionally need the following parameters:
Now, if you start an instance of etcd on each of your nodes with fitting configuration files, they will try to talk to each other and - should your configuration be correct and no firewall rules are blocking traffic - bootstrap the etcd cluster.
As this blog post is already on the rather lengthy side, I have created an archive for you to download that contains logs that show the configuration files used as well as the output of the etcd processes.
Another bootstrap approach, as I mentioned earlier, relies on an existing etcd cluster for discovery. Now, you don’t necessarily have to have a real etcd cluster. Keep in mind, that a single etcd process already acts as a cluster, albeit without high-availability. Alternatively, you can use the public discovery service located at discovery.etcd.io .
For the purpose of this guide, I will create a temporary local etcd cluster that can be reached by all members-to-be:
|
1 |
bash # etcd --name bootstrapper --listen-client-urls=http://0.0.0.0:2379 --advertise-client-urls=http://0.0.0.0:2379 |
We don’t need any of the peer parameters here as this bootstrapper is not expected to have any peers.
A special directory and a key specifying the expected number of members of the new cluster both need to be created.
We will generate a unique discovery token for this new cluster:
|
1 2 3 |
bash # UUID=$(uuidgen) bash # echo $UUID 860a192e-59ae-4a1a-a73c-8fee7fe403f9 |
The following call to curl creates the special size key, which implicitly creates the directory for cluster bootstrap in the bootstrapper’s key-value store:
|
1 |
bash # curl -X PUT http://10.88.0.1:2379/v2/keys/_etcd/registry/${UUID}/_config/size -d value=3 |
The three etcd members-to-be now only need (besides the five basic parameters listed earlier) to know where to reach this discovery service, so the following line is added to all etcd cluster members-to-be:
|
1 |
discovery: 'http://10.88.0.1:2379/v2/keys/_etcd/registry/860a192e-59ae-4a1a-a73c-8fee7fe403f9/' |
Now, when the etcd instances are launched, they will register themselves into the directory that we created earlier. As soon as _config/size many members have gathered there, they will bootstrap a new cluster on their own.
At this point, you can safely terminate the bootstrapper etcd instance.
The output of the discovery bootstrap method along with the config files can also be found in the archive.
To check whether the bootstrap was successful, you can call the etcdctl cluster-health command.
|
1 2 3 4 5 |
bash # etcdctl cluster-health member 919153442f157adf is healthy: got healthy result from http://10.88.0.41:2379 member 939c8672c1e24745 is healthy: got healthy result from http://10.88.0.42:2379 member c38cd15213ffca05 is healthy: got healthy result from http://10.88.0.43:2379 cluster is healthy |
If you want to run this command somewhere other than on the hosts that contain the etcd members, you will have to specify the endpoints to which etcdctl should talk directly:
|
1 |
bash # etcdctl cluster-health --endpoints 'http://10.88.0.41:2379,http://10.88.0.42:2379,http://10.88.0.43:2379' |
Usually, you'll want to run etcd as some sort of daemon that is started whenever your server is started, to protect against intermittent failures and negligence after planned maintenance.
If you've installed etcd via your operating system's package manager, a service file will already have been installed.
The service file is built in such a way that all of the necessary configuration parameters are loaded via environment variables. These can be set in the /etc/etcd/etcd.conf file and have a slightly different notation compared to the parameters that we've placed in YAML files in the examples above.
To convert the YAML configuration, you simply need to convert all parameter names to upper case and change dashes (-) to underscores (_) .
If you try to follow this guide on Ubuntu or Debian and install etcd via apt, you will run into issues.
This is the result of the fact that everything that resembles a server automatically starts an instance through Systemd after installation has completed. You need to kill this instance, otherwise you won't be able to run your etcd cluster members on ports 2379 and 2380.
With the recent update to etcd 3.4, the v2 API of etcd is disabled by default. Since the etcd v3 API is however currently not useable with patroni (due to missing support for multiple etcd endpoints in the library, see this pull request), you'll need to manually re-enable support for the v2 API by adding enable-v2= true to your config file.
Bootstrapping an etcd server can be quite difficult if you run into it blindfolded. However, once the key concepts of etcd clusters are understood and you’ve learned what exactly needs to go into the configuration files, you can bootstrap an etcd cluster quickly and easily.
While there are lots of things to consider for member placement in more complex cross-data center setups, a simple three node cluster is probably fine for any testing environment and for setups which only span a single data center.
Do keep in mind that the cluster setups I demonstrated were stripped of any security considerations for ease of playing around. I highly recommend that you look into the different options for securing etcd. You should at least enable rolename and password authentication, and server certificates are probably a good idea to encrypt traffic if your network might be susceptible to eavesdropping attacks. For even more security, you can even add client certificates. Of course, Patroni works well with all three of these security mechanisms in any combination.
This post is part of a series.
Besides this post the following articles have already been published:
- PostgreSQL High-Availability and Patroni – an Introduction.
- Patroni: Setting up a highly availability PostgreSQL clusters
The series will also cover:
– configuration and troubleshooting
– failover, maintenance, and monitoring
– client connection handling and routing
– WAL archiving and database backups using pgBackrest
– PITR a patroni cluster using pgBackrest
Hello.
Good explanations. Your first article says that there will be others parts in this series.
– configuration and troubleshooting
– failover, maintenance, and monitoring
– client connection handling and routing
– WAL archiving and database backups using pgBackrest
– PITR a patroni cluster using pgBackrest
I would like really read your explanations on these parts. 🙂
Christian